无向图的遍历(BFS+DFS,MATLAB)
来源:互联网 发布:德国pjur怎么样 知乎 编辑:程序博客网 时间:2024/06/01 09:31
广度/宽度优先搜索(BFS)
【算法入门】
1.前言
广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历策略。因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较广的区域,故得名。
一般可以用它做什么呢?一个最直观经典的例子就是走迷宫,我们从起点开始,找出到终点的最短路程,很多最短路径算法就是基于广度优先的思想成立的。
算法导论里边会给出不少严格的证明,我想尽量写得通俗一点,因此采用一些直观的讲法来伪装成证明,关键的point能够帮你get到就好。
2.图的概念
刚刚说的广度优先搜索是连通图的一种遍历策略,那就有必要将图先简单解释一下。
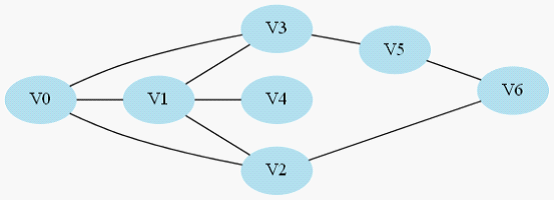
图2-1 连通图示例图
如图2-1所示,这就是我们所说的连通图,这里展示的是一个无向图,连通即每2个点都有至少一条路径相连,例如V0到V4的路径就是V0->V1->V4。
一般我们把顶点用V缩写,把边用E缩写。
3.广度优先搜索
3.1.算法的基本思路
常常我们有这样一个问题,从一个起点开始要到一个终点,我们要找寻一条最短的路径,从图2-1举例,如果我们要求V0到V6的一条最短路(假设走一个节点按一步来算)【注意:此处你可以选择不看这段文字直接看图3-1】,我们明显看出这条路径就是V0->V2->V6,而不是V0->V3->V5->V6。先想想你自己刚刚是怎么找到这条路径的:首先看跟V0直接连接的节点V1、V2、V3,发现没有V6,进而再看刚刚V1、V2、V3的直接连接节点分别是:{V0、V4}、{V0、V1、V6}、{V0、V1、V5}(这里画删除线的意思是那些顶点在我们刚刚的搜索过程中已经找过了,我们不需要重新回头再看他们了)。这时候我们从V2的连通节点集中找到了V6,那说明我们找到了这条V0到V6的最短路径:V0->V2->V6,虽然你再进一步搜索V5的连接节点集合后会找到另一条路径V0->V3->V5->V6,但显然他不是最短路径。
你会看到这里有点像辐射形状的搜索方式,从一个节点,向其旁边节点传递病毒,就这样一层一层的传递辐射下去,知道目标节点被辐射中了,此时就已经找到了从起点到终点的路径。
我们采用示例图来说明这个过程,在搜索的过程中,初始所有节点是白色(代表了所有点都还没开始搜索),把起点V0标志成灰色(表示即将辐射V0),下一步搜索的时候,我们把所有的灰色节点访问一次,然后将其变成黑色(表示已经被辐射过了),进而再将他们所能到达的节点标志成灰色(因为那些节点是下一步搜索的目标点了),但是这里有个判断,就像刚刚的例子,当访问到V1节点的时候,它的下一个节点应该是V0和V4,但是V0已经在前面被染成黑色了,所以不会将它染灰色。这样持续下去,直到目标节点V6被染灰色,说明了下一步就到终点了,没必要再搜索(染色)其他节点了,此时可以结束搜索了,整个搜索就结束了。然后根据搜索过程,反过来把最短路径找出来,图3-1中把最终路径上的节点标志成绿色。
整个过程的实例图如图3-1所示。
 初始全部都是白色(未访问)
初始全部都是白色(未访问)
 即将搜索起点V0(灰色)
即将搜索起点V0(灰色)
 已搜索V0,即将搜索V1、V2、V3
已搜索V0,即将搜索V1、V2、V3
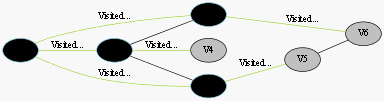 ……终点V6被染灰色,终止
……终点V6被染灰色,终止
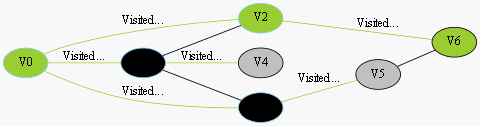 找到最短路径
找到最短路径
图3-1 寻找V0到V6的过程
3.2.广度优先搜索流程图
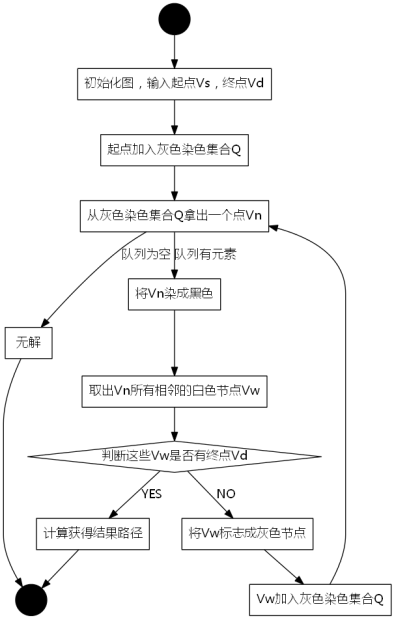
图3-2 广度优先搜索的流程图
在写具体代码之前有必要先举个实例,详见第4节。
4.实例
第一节就讲过广度优先搜索适用于迷宫类问题,这里先给出POJ3984《迷宫问题》。
《迷宫问题》
定义一个二维数组:
int maze[5][5] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的最短路线。
题目保证了输入是一定有解的。
也许你会问,这个跟广度优先搜索的图怎么对应起来?BFS的第一步就是要识别图的节点跟边!
4.1.识别出节点跟边
节点就是某种状态,边就是节点与节点间的某种规则。
对应于《迷宫问题》,你可以这么认为,节点就是迷宫路上的每一个格子(非墙),走迷宫的时候,格子间的关系是什么呢?按照题目意思,我们只能横竖走,因此我们可以这样看,格子与它横竖方向上的格子是有连通关系的,只要这个格子跟另一个格子是连通的,那么两个格子节点间就有一条边。
如果说本题再修改成斜方向也可以走的话,那么就是格子跟周围8个格子都可以连通,于是一个节点就会有8条边(除了边界的节点)。
4.2.解题思路
对应于题目的输入数组:
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
我们把节点定义为(x,y),(x,y)表示数组maze的项maze[x][y]。
于是起点就是(0,0),终点是(4,4)。按照刚刚的思路,我们大概手工梳理一遍:
初始条件:
起点Vs为(0,0)
终点Vd为(4,4)
灰色节点集合Q={}
初始化所有节点为白色节点
开始我们的广度搜索!
手工执行步骤【PS:你可以直接看图4-1】:
1.起始节点Vs变成灰色,加入队列Q,Q={(0,0)}
2.取出队列Q的头一个节点Vn,Vn={0,0},Q={}
3.把Vn={0,0}染成黑色,取出Vn所有相邻的白色节点{(1,0)}
4.不包含终点(4,4),染成灰色,加入队列Q,Q={(1,0)}
5.取出队列Q的头一个节点Vn,Vn={1,0},Q={}
6.把Vn={1,0}染成黑色,取出Vn所有相邻的白色节点{(2,0)}
7.不包含终点(4,4),染成灰色,加入队列Q,Q={(2,0)}
8.取出队列Q的头一个节点Vn,Vn={2,0},Q={}
9.把Vn={2,0}染成黑色,取出Vn所有相邻的白色节点{(2,1), (3,0)}
10.不包含终点(4,4),染成灰色,加入队列Q,Q={(2,1), (3,0)}
11.取出队列Q的头一个节点Vn,Vn={2,1},Q={(3,0)}
12. 把Vn={2,1}染成黑色,取出Vn所有相邻的白色节点{(2,2)}
13.不包含终点(4,4),染成灰色,加入队列Q,Q={(3,0), (2,2)}
14.持续下去,知道Vn的所有相邻的白色节点中包含了(4,4)……
15.此时获得了答案
起始你很容易模仿上边过程走到终点,那为什么它就是最短的呢?
怎么保证呢?
我们来看看广度搜索的过程中节点的顺序情况:

图4-1 迷宫问题的搜索树
你是否观察到了,广度搜索的顺序是什么样子的?
图中标号即为我们搜索过程中的顺序,我们观察到,这个搜索顺序是按照上图的层次关系来的,例如节点(0,0)在第1层,节点(1,0)在第2层,节点(2,0)在第3层,节点(2,1)和节点(3,0)在第3层。
我们的搜索顺序就是第一层->第二层->第三层->第N层这样子。
我们假设终点在第N层,因此我们搜索到的路径长度肯定是N,而且这个N一定是所求最短的。
我们用简单的反证法来证明:假设终点在第N层上边出现过,例如第M层,M<N,那么我们在搜索的过程中,肯定是先搜索到第M层的,此时搜索到第M层的时候发现终点出现过了,那么最短路径应该是M,而不是N了。
所以根据广度优先搜索的话,搜索到终点时,该路径一定是最短的。
6.其他实例
6.1.题目描述
给定序列1 2 3 4 5 6,再给定一个k,我们给出这样的操作:对于序列,我们可以将其中k个连续的数全部反转过来,例如k = 3的时候,上述序列经过1步操作后可以变成:3 2 1 4 5 6 ,如果再对序列 3 2 1 4 5 6进行一步操作,可以变成3 4 1 2 5 6.
那么现在题目就是,给定初始序列,以及结束序列,以及k的值,那么你能够求出从初始序列到结束序列的转变至少需要几步操作吗?
6.2.思路
本题可以采用BFS求解,已经给定初始状态跟目标状态,要求之间的最短操作,其实也很明显是用BFS了。
我们把每次操作完的序列当做一个状态节点。那每一次操作就产生一条边,这个操作就是规则。
假设起始节点是:{1 2 3 4 5 6},终点是:{3 4 1 2 5 6}
去除队列中的起始节点时,将它的相邻节点加入队列,其相邻节点就是对其操作一次的所有序列:
{3 2 1 4 5 6}、{1 4 3 2 5 6}、{1 2 5 4 3 6}、{1 2 3 6 5 4}
然后继续搜索即可得到终点,此时操作数就是搜索到的节点所在的层数2。
7.OJ题目
题目分类来自网络:
sicily:1048 1444 1215 1135 1150 1151 1114
pku:1136 1249 1028 1191 3278 1426 3126 3087 3414
8.总结
假设图有V个顶点,E条边,广度优先搜索算法需要搜索V个节点,因此这里的消耗是O(V),在搜索过程中,又需要根据边来增加队列的长度,于是这里需要消耗O(E),总得来说,效率大约是O(V+E)。
其实最影响BFS算法的是在于Hash运算,我们前面给出了一个visit数组,已经算是最快的Hash了,但有些题目来说可能Hash的速度要退化到O(lgn)的复杂度,当然了,具体还是看实际情况的。
BFS适合此类题目:给定初始状态跟目标状态,要求从初始状态到目标状态的最短路径。
9.扩展
进而扩展的话就是双向广度搜索算法,顾名思义,即是从起点跟终点分别做广度优先搜索,直到他们的搜索过程中有一个节点相同了,于是就找到了起点跟终点的一条路径。
腾讯笔试题目:假设每个人平均是有25个好友,根据六维理论,任何人之间的联系一定可以通过6个人而间接认识,间接通过N个人认识的,那他就是你的N度好友,现在要你编程验证这个6维理论。
此题如果直接做广度优先搜索,那么搜索的节点数可能达到25^6,如果是用双向的话,两个树分别只需要搜索到3度好友即可,搜索节点最多为25^3个,但是用双向广度算法的话会有一个问题要解决,就是你如何在搜索的过程中判断第一棵树中的节点跟第二棵树中的节点有相同的呢?按我的理解,可以用Hash,又或者放进队列的元素都是指向原来节点的指针,而每个节点加入一个color的属性,这样再搜索过程中就可以根据节点的color来判断是否已经被搜索过了。
深度优先搜索(DFS)
【算法入门】
1.前言
深度优先搜索(缩写DFS)有点类似广度优先搜索,也是对一个连通图进行遍历的算法。它的思想是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底,这种尽量往深处走的概念即是深度优先的概念。
你可以跳过第二节先看第三节,:)
2.深度优先搜索VS广度优先搜索
2.1演示深度优先搜索的过程
还是引用上篇文章的样例图,起点仍然是V0,我们修改一下题目意思,只需要让你找出一条V0到V6的道路,而无需最短路。
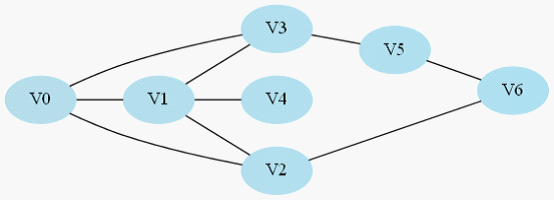
图2-1 寻找V0到V6的一条路(无需最短路径)
假设按照以下的顺序来搜索:
1.V0->V1->V4,此时到底尽头,仍然到不了V6,于是原路返回到V1去搜索其他路径;
2.返回到V1后既搜索V2,于是搜索路径是V0->V1->V2->V6,,找到目标节点,返回有解。
这样搜索只是2步就到达了,但是如果用BFS的话就需要多几步。
2.2深度与广度的比较
(你可以跳过这一节先看第三节,重点在第三节)
从上一篇《【算法入门】广度/宽度优先搜索(BFS) 》中知道,我们搜索一个图是按照树的层次来搜索的。
我们假设一个节点衍生出来的相邻节点平均的个数是N个,那么当起点开始搜索的时候,队列有一个节点,当起点拿出来后,把它相邻的节点放进去,那么队列就有N个节点,当下一层的搜索中再加入元素到队列的时候,节点数达到了N2,你可以想想,一旦N是一个比较大的数的时候,这个树的层次又比较深,那这个队列就得需要很大的内存空间了。
于是广度优先搜索的缺点出来了:在树的层次较深&子节点数较多的情况下,消耗内存十分严重。广度优先搜索适用于节点的子节点数量不多,并且树的层次不会太深的情况。
那么深度优先就可以克服这个缺点,因为每次搜的过程,每一层只需维护一个节点。但回过头想想,广度优先能够找到最短路径,那深度优先能否找到呢?深度优先的方法是一条路走到黑,那显然无法知道这条路是不是最短的,所以你还得继续走别的路去判断是否是最短路?
于是深度优先搜索的缺点也出来了:难以寻找最优解,仅仅只能寻找有解。其优点就是内存消耗小,克服了刚刚说的广度优先搜索的缺点。
3.深度优先搜索
3.1.举例
给出如图3-1所示的图,求图中的V0出发,是否存在一条路径长度为4的搜索路径。

图3-1
显然,我们知道是有这样一个解的:V0->V3->V5->V6。
3.2.处理过程

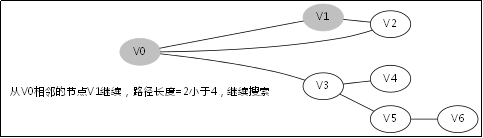

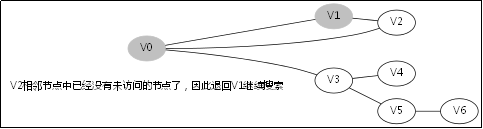
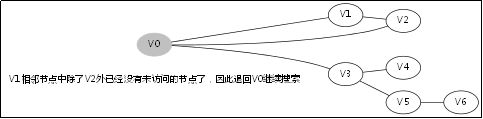
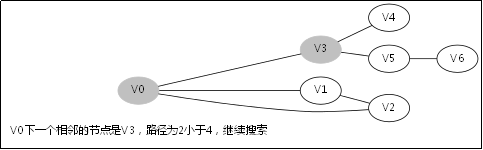
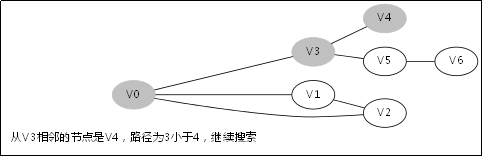
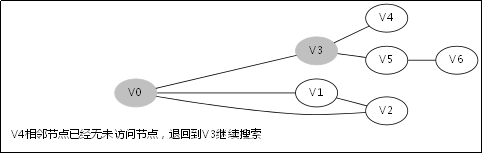
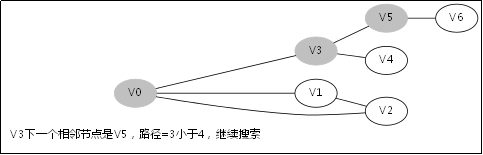
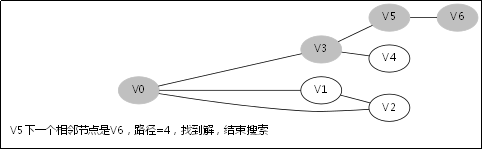
3.4.DFS函数的调用堆栈

此后堆栈调用返回到V0那一层,因为V1那一层也找不到跟V1的相邻未访问节点

此后堆栈调用返回到V3那一层

此后堆栈调用返回到主函数调用DFS(V0,0)的地方,因为已经找到解,无需再从别的节点去搜别的路径了。
5.另一个例子:24点
5.1.题目描述
想必大家都玩过一个游戏,叫做“24点”:给出4个整数,要求用加减乘除4个运算使其运算结果变成24,4个数字要不重复的用到计算中。
例如给出4个数:1、2、3、4。我可以用以下运算得到结果24:
1*2*3*4 = 24;2*3*4/1 = 24;(1+2+3)*4=24;……
如上,是有很多种组合方式使得他们变成24的,当然也有无法得到结果的4个数,例如:1、1、1、1。
现在我给你这样4个数,你能告诉我它们能够通过一定的运算组合之后变成24吗?这里我给出约束:数字之间的除法中不得出现小数,例如原本我们可以1/4=0.25,但是这里的约束指定了这样操作是不合法的。
5.2.解法:搜索树
这里为了方便叙述,我假设现在只有3个数,只允许加法减法运算。我绘制了如图5-1的搜索树。
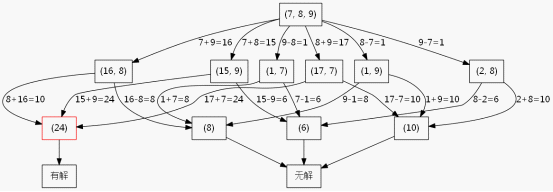
图5-1
此处只有3个数并且只有加减法,所以第二层的节点最多就6个,如果是给你4个数并且有加减乘除,那么第二层的节点就会比较多了,当延伸到第三层的时候节点数就比较多了,使用BFS的缺点就暴露了,需要很大的空间去维护那个队列。而你看这个搜索树,其实第一层是3个数,到了第二层就变成2个数了,也就是递归深度其实不会超过3层,所以采用DFS来做会更合理,平均效率要比BFS快(我没写代码验证过,读者自行验证)。
6.OJ题目
题目分类来自网络:
sicily:1019 1024 1034 1050 1052 1153 1171 1187
pku:1088 1176 1321 1416 1564 1753 2492 3083 3411
7.总结
DFS适合此类题目:给定初始状态跟目标状态,要求判断从初始状态到目标状态是否有解。
8.扩展
不知道你注意到没,在深度/广度搜索的过程中,其实相邻节点的加入如果是有一定策略的话,对算法的效率是有很大影响的,你可以做一下简单马周游跟马周游这两个题,你就有所体会,你会发现你在搜索的过程中,用一定策略去访问相邻节点会提升很大的效率。
这些运用到的贪心的思想,你可以再看看启发式搜索的算法,例如A*算法等。
无向图的存储方式有邻接矩阵,邻接链表,稀疏矩阵等。无向图主要包含两方面内容,图的遍历和寻找联通分量。
一、无向图的遍历
无向图的遍历有两种方式—广度优先搜索(BFS)和深度优先搜索(DFS)。广度优先搜索在遍历一个顶点的所有节点时,先把当前节点所有相邻节点遍历了,然后遍历当前节点第一个相邻的节点的所有相邻节点,广度优先搜索使用队列来实现。深度优先搜索在遍历当前节点的所有相邻节点时,先对当前节点的第一个相邻节点进行访问,然后遍历第一个相邻节点的相邻节点,依次递归,因此深度优先搜索使用栈实现。
1、BFS图遍历代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、DFS图遍历代码
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
二、寻找联通分量
寻找联通分量的方法就是把一个节点的所有相邻节点找出来,然后再在未访问过的节点中选择一个节点用遍历方法寻找相邻节点。
1、基于BFS的寻找联通分量代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2、基于BFS的寻找联通分量代码:
在访问记录链表中选择未访问过的节点作为深度优先搜索的起点直到所有节点都被访问过即可。
三、图的高级应用
1、BFS
最短路径(Dijkstra),最小生成树(Prim),拓扑排序
2、DFS
拓扑排序,强连通分量
本文代码基于邻接矩阵实现。
- 无向图的遍历(BFS+DFS,MATLAB)
- 算法导论—无向图的遍历(BFS+DFS,MATLAB)
- 邻接矩阵遍历(无向图,邻接矩阵,DFS,BFS)
- 邻接矩阵存储的无向图深度优先(DFS)广度优先(BFS)遍历
- 无向图的DFS和BFS算法实现
- 无向图创建+BFS+DFS(整合)
- dfs, bfs之邻接矩阵无向图
- 无向DFS遍历
- 无向图邻接表的深度优先遍历(DFS)
- 无向图的邻接矩阵 -- DFS - 深度优先遍历
- 邻接表无向图的创建和遍历(dfs)
- 邻接矩阵无向图的创建和遍历(dfs)
- 图的遍历:DFS BFS
- 图的遍历(DFS&BFS)
- 图的遍历[DFS][BFS]
- 图的dfs遍历和bfs遍历
- 利用邻接矩阵存储无向图,并实现BFS(非递归) DFS(递归+非递归)两种遍历
- 通过DFS和BFS判断无向图是否连通
- PHP对程序员的要求更高
- 士兵杀敌(三)(线段树)
- 网易2018校招编程题集合3
- Linux下搭建 NFS
- 基于Cesium剖面分析功能的实现
- 无向图的遍历(BFS+DFS,MATLAB)
- LVM(逻辑卷管理)
- 欢迎使用CSDN-markdown编辑器
- 字符串反转
- 问题 F: 拦截导弹
- 求阶乘
- 线段树模板(学长给的,自己消化了一下,其实基本上差不多(好吧,一模一样QAQ))
- 初学JDBC
- [第七季]4.控制DIV的选取


