区域推荐网络RPN
来源:互联网 发布:office软件卸载不了 编辑:程序博客网 时间:2024/06/05 01:50
Region Proposal Network
RPN的实现方式:在conv5-3的卷积feature map上用一个n*n的滑窗(论文中作者选用了n=3,即3*3的滑窗)生成一个长度为256(对应于ZF网络)或512(对应于VGG网络)维长度的全连接特征.然后在这个256维或512维的特征后产生两个分支的全连接层:
(1)reg-layer,用于预测proposal的中心锚点对应的proposal的坐标x,y和宽高w,h;
(2)cls-layer,用于判定该proposal是前景还是背景.sliding window的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间.事实上,作者用全连接层实现方式介绍RPN层实现容易帮助我们理解这一过程,但在实现时作者选用了卷积层实现全连接层的功能.
(3)个人理解:全连接层本来就是特殊的卷积层,如果产生256或512维的fc特征,事实上可以用Num_out=256或512, kernel_size=3*3, stride=1的卷积层实现conv5-3到第一个全连接特征的映射.然后再用两个Num_out分别为2*9=18和4*9=36,kernel_size=1*1,stride=1的卷积层实现上一层特征到两个分支cls层和reg层的特征映射.
(4)注意:这里2*9中的2指cls层的分类结果包括前后背景两类,4*9的4表示一个Proposal的中心点坐标x,y和宽高w,h四个参数.采用卷积的方式实现全连接处理并不会减少参数的数量,但是使得输入图像的尺寸可以更加灵活.在RPN网络中,我们需要重点理解其中的anchors概念,Loss fucntions计算方式和RPN层训练数据生成的具体细节.
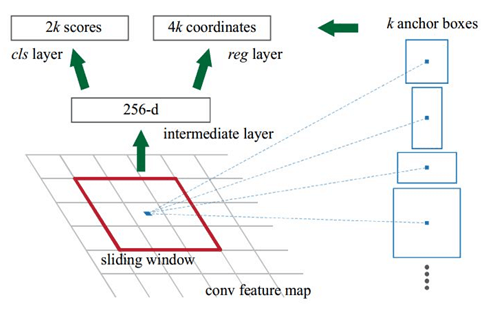
Anchors:字面上可以理解为锚点,位于之前提到的n*n的sliding window的中心处.对于一个sliding window,我们可以同时预测多个proposal,假定有k个.k个proposal即k个reference boxes,每一个reference box又可以用一个scale,一个aspect_ratio和sliding window中的锚点唯一确定.所以,我们在后面说一个anchor,你就理解成一个anchor box 或一个reference box.作者在论文中定义k=9,即3种scales和3种aspect_ratio确定出当前sliding window位置处对应的9个reference boxes, 4*k个reg-layer的输出和2*k个cls-layer的score输出.对于一幅W*H的feature map,对应W*H*k个锚点.所有的锚点都具有尺度不变性.
Loss functions:
在计算Loss值之前,作者设置了anchors的标定方法.正样本标定规则:
1) 如果Anchor对应的reference box与ground truth的IoU值最大,标记为正样本;
2) 如果Anchor对应的reference box与ground truth的IoU>0.7,标记为正样本.事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3) 负样本标定规则:如果Anchor对应的reference box与ground truth的IoU<0.3,标记为负样本.
4) 剩下的既不是正样本也不是负样本,不用于最终训练.
5) 训练RPN的Loss是有classification loss (即softmax loss)和regression loss (即L1 loss)按一定比重组成的.
计算softmax loss需要的是anchors对应的groundtruth标定结果和预测结果,计算regression loss需要三组信息:
i. 预测框,即RPN网络预测出的proposal的中心位置坐标x,y和宽高w,h;
ii. 锚点reference box:
之前的9个锚点对应9个不同scale和aspect_ratio的reference boxes,每一个reference boxes都有一个中心点位置坐标x_a,y_a和宽高w_a,h_a;
iii. ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*.因此计算regression loss和总Loss方式如下:

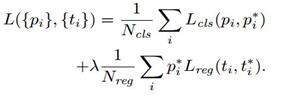
RPN训练设置:
(1)在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1.
(2)如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然.
(3)训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化.
- 区域推荐网络RPN
- RPN 区域推荐网络
- 深度学习: RPN网络结构
- RPN
- faster-rcnn 之 RPN网络的结构解析以及RPN代码详解
- faster-rcnn 之 RPN网络的结构解析以及RPN代码详解
- faster-rcnn 之 RPN网络的结构解析
- faster-rcnn 之 RPN网络的结构解析
- faster-rcnn 之 RPN网络的结构解析
- faster-rcnn 中的RPN网络的结构解析
- faster-rcnn之RPN网络的结构解析
- RPN网络的锚是如何生成的
- faster-rcnn 之 RPN网络的结构解析
- faster-rcnn 之 RPN网络的结构解析
- faster-rcnn 之 RPN网络的结构解析
- Faster RCNN 推荐区域理解
- 存储区域网络(SAN)
- 网络区域划分
- Centos6.5源码安装MySQL
- [笔记分享] [Camera] MTK Camera module
- 百度之星初赛(A)--今夕何夕----大模拟
- 台达伺服ASD-B2的调试
- python实现生产者消费者模式代码示例
- 区域推荐网络RPN
- cocos2dx2.2.3+python搭建 Lua工程/开发环境,Lua生成 android项目
- 基督徒如何面对死亡?
- JSON
- Docker教程4
- 软件测试理论学习2017.08.13
- Pytorch中文视频教程,Pytorch实战视频教程
- git笔记
- Spring-Framework启动简介


