DQN从入门到放弃学习总结(2)
来源:互联网 发布:淘宝游戏光盘 编辑:程序博客网 时间:2024/05/16 12:56
1、动作价值函数:
每个状态对应多种动作,我们考率在某个状态下执行不同动作所获得的价值,通过其大小,便可选择价值最大的来执行。Action-Value function:。同样,也是用reward来表示,但是此处reward是执行动作以后获得的,之前state对应的reward则是多种动作对应的reward的期望。
动作-价值函数表示如下:
此处包含策略,即在策略下的动作价值。因为对于每一个动作,都需要由策略根据当前的状态生成。但价值函数不一定依赖于策略。
但因为动作价值函数更直观,更方便用于算法,所以更多的使用的是动作价值函数。
2、最优价值函数
如果能找到最优的价值函数,则自然找到策略(这是策略的求解方法之一,即Value-based approach,DQN就是Value-based,还有policy-based和model-based前者直接计算策略函数,后者是估计模型,计算出状态转移概率)
因为
所以
,最优Q值必然为最大,所以等式右侧的Q值必然为使a'取最大的Q值。(a‘使Q为最大)
3、策略迭代 policy iteration
通过迭代计算value function 使policy收敛到最优
策略迭代的本质是使用bellman方程得到的:
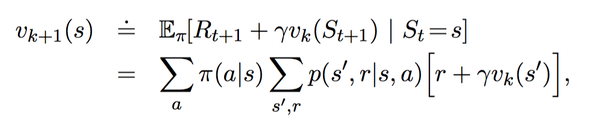
策略迭代分为两步:
1、策略评估。目的:更新value-function (更好地估计基于当前策略的价值)
2、策略改进。使用贪婪策略产生新的样本用于第一步的策略评估
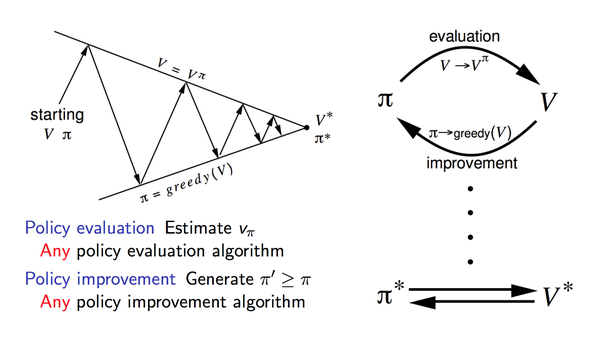
具体算法:

policy-evaluation 中,需要知道转移概率,即依赖模型。且迭代中需要限制迭代次数。不论策略迭代还是值迭代,都是“上帝”视角推导出来的,本质上不能直接应用,因为是依赖模型的。
4、价值迭代
价值迭代是通过Bellman最优方程得到的:
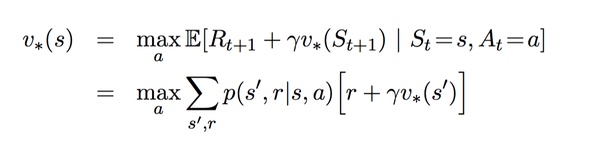
变为迭代形式:
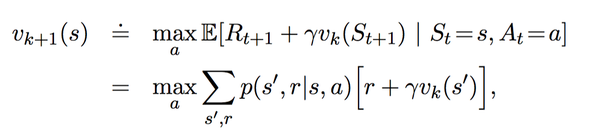
算法如下:
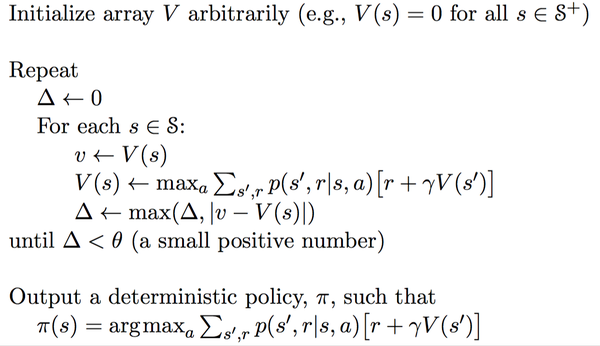
5、策略迭代和价值迭代的区别
policy iteration使用 bellman方程 来更新value,最后收敛的value 即是当前policy下的value值(所以叫做对policy进行评估),目的是为了后面的policy improvement得到新的policy。
value iteration使用 bellman 最优方程 来更新value,最后收敛得到的value即就是当前state状态下的最优的value值。因此,只要最后收敛,那么最优的policy也就得到的。因此这个方法是基于更新value的,所以叫value iteration。
从上面的分析看,value iteration较之policy iteration更直接。不过问题也都是一样,需要知道状态转移函数p才能计算。本质上依赖于模型,而且理想条件下需要遍历所有的状态,这在稍微复杂一点的问题上就基本不可能了。
上面引用的是价值函数的版本,那么如果是使用动作价值函数呢,公式基本是一样的:
每次根据新得到的reward和原来的Q值来更新现在的Q值。理论上可以证明这样的value iteration能够使Q值收敛到最优的action-value function。
- DQN从入门到放弃学习总结(2)
- DQN 从入门到放弃1 DQN与增强学习
- DQN(Deep Q-learning)从入门到放弃笔记
- 菜鸟学习从入门到放弃(二)排序算法总结与应用(附代码)
- 推送,从入门到放弃 笔记总结
- 学习PHP从入门到放弃-语法
- 深度增强学习(DRL)漫谈 - 从DQN到AlphaGo
- 深度增强学习(DRL)漫谈 - 从DQN到AlphaGo
- 从入门到放弃C语言-入门篇(2)
- 深度增强学习漫谈 从DQN到
- 从入门到放弃C语言-瞎倒腾(2)
- OpenCV3.2从入门到放弃(一)
- Java web从入门到放弃(2)
- android从入门到放弃2--ButterKnife
- Docker 从入门到放弃(一)
- 策略模式(从放弃到入门)
- 观察者模式(从放弃到入门)
- JSP--(二)从入门到放弃
- Android数据库高手秘籍(一)——SQLite命令
- 数据库的原理,一篇文章搞定
- 开挂人生的启程
- BZOJ3531: [Sdoi2014]旅行
- 机器学习入门第一天,自己对数值预测算法的理解
- DQN从入门到放弃学习总结(2)
- HNUSTOJ-1689 送外卖(TSP问题)
- Linux新建Workerman、composer、redis服务
- 《西瓜书》笔记10:降维与度量学习(三)
- HDU-Gameia
- 列表(list)
- 实现图片通过滚轮的放大缩小
- javaScript内置对象Boolean
- 180度vr直播用,鱼眼视频展开到全景


