数据结构之散列表
来源:互联网 发布:淘宝站外推广怎么做 编辑:程序博客网 时间:2024/05/17 00:09
- 散列表哈希表
- 散列函数的构造方法
- 数字关键词的散列构造函数
- 字符串关键字的散列函数构造
- 冲突处理方法
- 开放定址法
- 线性探测法Linear Probing
- 平方探测法Quadratic Probing-二次探测
- 双散列探测法Double
- 再散列
- 分离链接法
- 开放定址法
- 散列函数的构造方法
散列表(哈希表)
“散列(Hashing)”的基本思想是
(1) 以关键字key为自变量,通过一个确定的函数 h(散列函数),计算出对应的函数值h(key),作为数据对象的存储地址。
(2)可能不同的关键字会映射到同一个散列地址上,即h(keyi) = h(keyj)(当keyi ≠keyj),称为“冲突(Collision)”。—-需要某种冲突解决策略
散列函数的构造方法
一个“好”的散列函数一般应考虑下列两个因素:
1. 计算简单,以便提高转换速度;
2. 关键词对应的地址空间分布均匀,以尽量减少冲突。
数字关键词的散列构造函数
直接定址法
取关键词的某个线性函数值为散列地址,即h(key) = a*key + b (a、 b为常数)除留余数法
散列函数为:h(key) = key mod p这里,p=Tablesize,一般p取素数.数字分析法
分析数字关键字在各位上的变化情况,取比较随机的位作为散列地址。
比如: 取11位手机号码key的后4位作为地址:
散列函数为:h(key) = atoi(key+7) (char * key)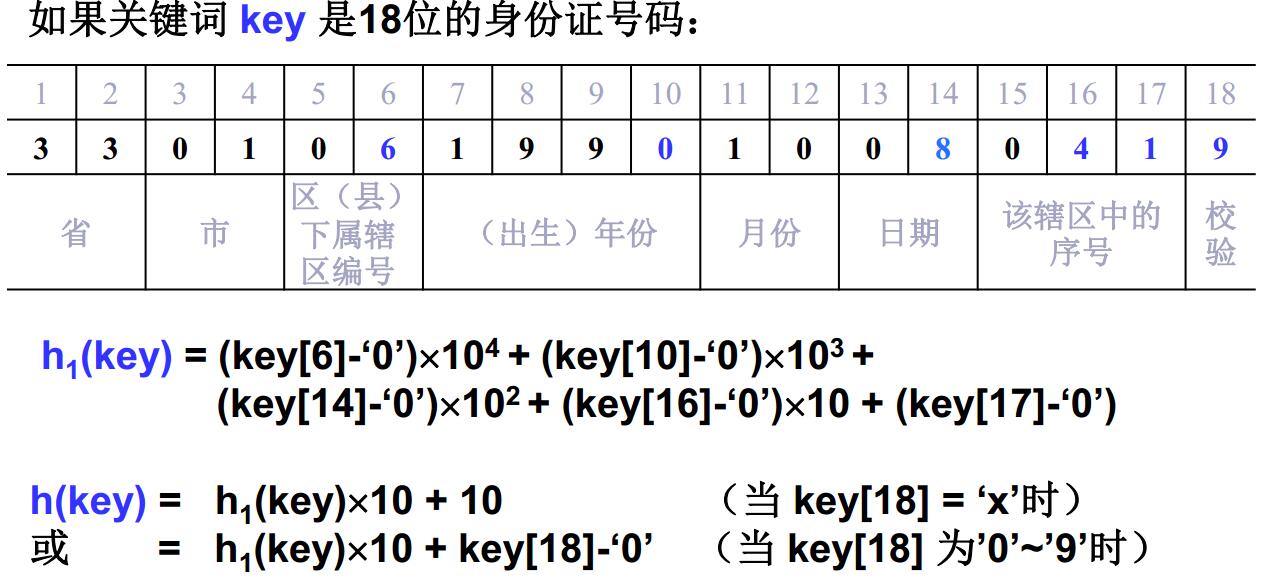
折叠法
把关键词分割成位数相同的几个部分,然后叠加
如: 56793542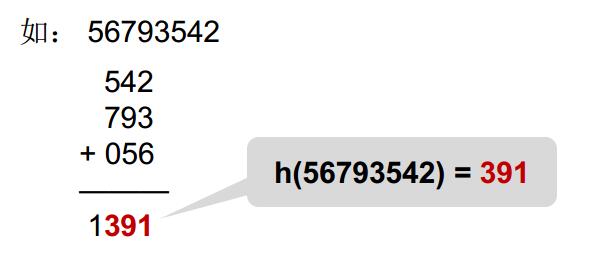
平方取中法
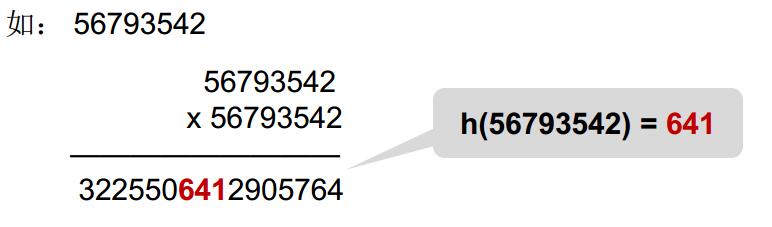
字符串关键字的散列函数构造
ASCII码加和法
h(key)=(∑key[i]) mod TableSize
问题:冲突严重前3个字符移位法
h(key)=(key[0]*27^2+key[1]*27+key[2]) mod TableSize移位法
涉及关键词所有n个字符,并且分布得很好:h(key)=(∑n−1i=0key[n−i−1]×32i) mod TableSize
如何快速计算:h("abcde")='a'*32^4+'b'*32^3+'c'*32^2+'d'*32+'e'
代码:
Index Hash ( const char *Key, int TableSize ){ unsigned int h = 0; /* 散列函数值, 初始化为0 */ while ( *Key != ‘\0’) /* 位移映射 */ h = ( h << 5 ) + *Key++; return h % TableSize;}冲突处理方法
常用处理冲突的思路:
* 换个位置: 开放地址法
* 同一个位置的冲突对象组织在一起: 链地址法
开放定址法
一旦产生了冲突(该地址已有其它元素),就按某 种规则去寻
找另一空地址.
* 若发生了第 i 次冲突,试探的下一个地址将增加di, 基本公式是: hi(key) = (h(key)+di) mod TableSize ( 1≤ i < TableSize )
*
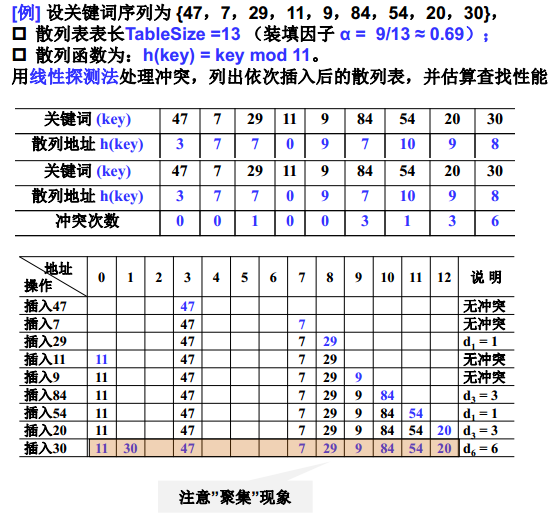
线性探测法(Linear Probing)
- 线性探测法: 以增量序列 1, 2, ……,(TableSize -1)循环试探下一个存储地址。
平方探测法(Quadratic Probing)-二次探测
- 平方探测法: 以增量序列
12,−12,22,−22,……,q2,−q2 且q ≤ |TableSize/2| 循环试探下一个存储地址。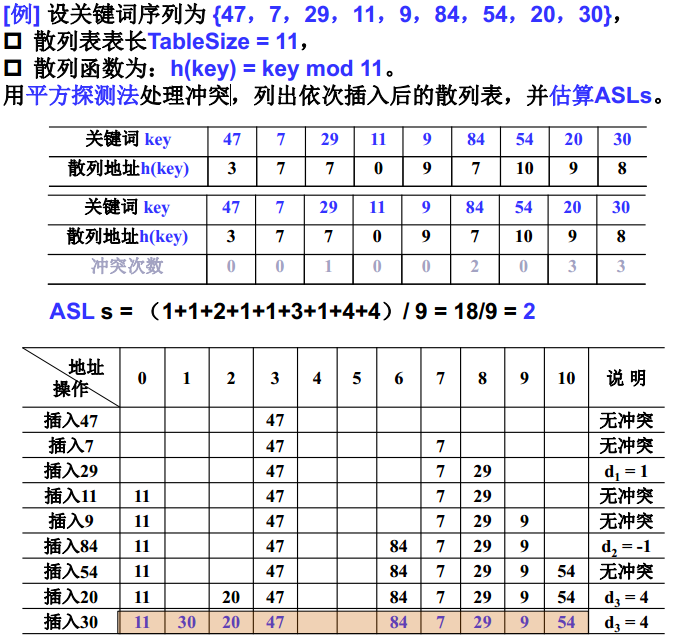
是否有空间,平方探测(二次探测)就能找得到?

有定理显示:如果散列表长度TableSize是某个
4k+3(k是正整数)形式的素数时, 平方探测法就可以探查到整个散列表空间。在开放地址散列表中, 删除操作要很小心。通常只能“懒惰删除” ,即需要增加一个“删除标记(Deleted)” ,而并不是真正删除它。以便查找时不会“断链”。其空间可以在下次插入时重用。
双散列探测法(Double)
双散列探测法:
探测序列成:
对任意的key,
探测序列还应该保证所有的散列存储单元都应该能够被探测到。
选择以下形式有良好的效果:
其中: p < TableSize, p、 TableSize都是素数。
再散列
当散列表元素太多(即装填因子 α太大)时, 查找效率会下降;
实用最大装填因子一般取 0.5 <= α<= 0.85
当装填因子过大时,解决的方法是加倍扩大散列表,这个过程叫
做“再散列(Rehashing)”
分离链接法
将相应位置上冲突的所有关键词存储在同一个单链表中

- 数据结构之散列表
- 数据结构之散列表
- 数据结构之散列表
- 数据结构之散列表
- 《数据结构》之(散列表)
- 《数据结构导论之散列表》
- 数据结构之---散列表(hash table)
- 数据结构之散列表冲突的解决方法
- 深入理解数据结构之散列表
- 算法及数据结构之散列表
- 数据结构之哈希表(散列表查找)
- 数据结构与算法分析之散列表
- 数据结构之散列表(哈希表)
- Python之列表数据结构
- python数据结构之列表
- 数据结构之列表
- redis数据结构之压缩列表
- 数据结构之双向列表实现
- 阿里在线编程测验——兔子繁衍问题
- linux top显示的各个符号参数意义详解
- Java中的异常处理机制《转载》
- 登录脚本重构Element
- C
- 数据结构之散列表
- sso单点登录系统(解决session共享)
- 查找html元素的方法、修改html输入流、属性和样式
- 隔离光耦驱动 IGBT 或 Power MOSFE 常见问题
- JQuery入门
- JavaMail 发送邮件
- P1219 八皇后
- HDU6080(很水的计算几何+floyd)
- 文件与目录管理


