Bit-map空间压缩和快速排序去重
来源:互联网 发布:知乎解除手机号绑定 编辑:程序博客网 时间:2024/04/30 11:00
Bit-map是一种很巧妙的数据存储结构。所谓的Bit-map就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,可以大大节省存储空间。Bit-map在实际中也有着广泛的应用,比如快速排序,元素去重以及空间缩减等等。本文通过Bit-map的几个应用实例对Bit-map以及其扩展结构Bloom Filter进行介绍。
1. Bit-map的基本思想
32位机器上,对于一个整型数,比如int a=1 在内存中占32bit位,这是为了方便计算机的运算。但是对于某些应用场景而言,这属于一种巨大的浪费,因为我们可以用对应的32bit位对应存储十进制的0-31个数,而这就是Bit-map的基本思想。Bit-map算法利用这种思想处理大量数据的排序、查询以及去重。
2. Bit-map应用之快速排序
假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,如下图:
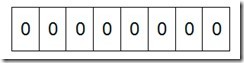
然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0x01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):
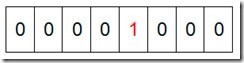
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
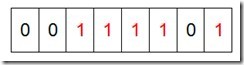
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的,时间复杂度O(n)。
Bit-map用于排序的优缺点同样明显。
优点:
1.运算效率高,不需要进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
3. Bit-map应用之快速去重
这是经常会在面试中出现的问题。比如,2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
首先,根据“内存空间不足以容纳这2.5亿个整数”我们可以快速的联想到Bit-map。下边关键的问题就是怎么设计我们的Bit-map来表示这2.5亿个数字的状态了。其实这个问题很简单,一个数字的状态只有三种,分别为不存在,只有一个,有重复。因此,我们只需要2bits就可以对一个数字的状态进行存储了,假设我们设定一个数字不存在为00,存在一次01,存在两次及其以上为11。那我们大概需要存储空间几十兆左右。
接下来的任务就是遍历一次这2.5亿个数字,如果对应的状态位为00,则将其变为01;如果对应的状态位为01,则将其变为11;如果为11,,对应的转态位保持不变。
最后,我们将状态位为01的进行统计,就得到了不重复的数字个数,时间复杂度为O(n)。
4. Bit-map应用之快速查询
同样,我们利用Bit-map也可以进行快速查询,这种情况下对于一个数字只需要一个bit位就可以了,0表示不存在,1表示存在。假设上述的题目改为,如何快速判断一个数字是够存在于上述的2.5亿个数字集合中。
同之前一样,首先我们先对所有的数字进行一次遍历,然后将相应的转态位改为1。遍历完以后就是查询,由于我们的Bit-map采取的是连续存储(整型数组形式,一个数组元素对应32bits),我们实际上是采用了一种分桶的思想。一个数组元素可以存储32个状态位,那将待查询的数字除以32,定位到对应的数组元素(桶),然后再求余(%32),就可以定位到相应的状态位。如果为1,则代表改数字存在;否则,该数字不存在。
5. Bit-map扩展——Bloom Filter
Bloom Filter:一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive),因此Bloom Filter不适合那些“零错误”的应用场合,而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
集合表示和元素查询
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注:如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。

在判断y是否属于这个集合时,对y应用k次哈希函数,若所有hi(y)的位置都是1(1≤i≤k),就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位);y2或者属于这个集合,或者刚好是一个false positive。

6. 总结
使用Bit-map的思想,我们可以将存储空间进行压缩,而且可以对数字进行快速排序、去重和查询的操作。Bloom Fliter是Bit-map思想的一种扩展,它可以在允许低错误率的场景下,大大地进行空间压缩,是一种拿错误率换取空间的数据结构。
- Bit-map空间压缩和快速排序去重
- Bit-map空间压缩和快速排序去重
- Bit-map空间压缩和快速排序去重
- 数组去重和快速排序
- java list map 去重和排序方法
- 快速排序+数组去重
- 去重和排序
- 去重和排序
- js面试题之数组去重和快速排序
- JS面试之数组去重和快速排序
- List<Map<String,Object>>去重,排序
- List<Map<String,Object>>去重,排序
- 数组快速排序、去重算法
- Javascript 实现数组去重,快速排序
- 去重和压缩:数据简缩技术
- 冒泡排序和冒泡排序去重
- java8 stream初试,map排序,list去重,统计重复元素个数,获取map的key集合和value集合
- 如何使用shell脚本快速排序和去重文件数据
- 从一杯果汁浅谈点点医生充值提现模块设计
- android存储之SQLite数据库
- 剑指Offer面试题13[在O(1)时间删除表的结点]
- B
- qt开发环境
- Bit-map空间压缩和快速排序去重
- 新建仓库和上传本地文件到github
- ALLEGRO学习之晶振布局以及布线
- hdu 6125 分组背包+状态压缩
- 8月15集训
- iOS_Runtime1_消息发送机制
- 读了几篇boosting文献的收获。。。
- Linux设备驱动之udal341声卡驱动与madplay播放器移植
- hadoop reduce 阶段遍历 Iterable 的 2 个“坑”


