基于spark Mllib(ML)聚类实战
来源:互联网 发布:qq三国辅助软件 编辑:程序博客网 时间:2024/06/06 08:24
写在前面的话:由于spark2.0.0之后ML中才包括LDA,GaussianMixture 模型,这里k-means用的是ML模块做测试,LDA,GaussianMixture 则用的是MLlib模块
数据资料下载网站,大力推荐!!!
http://archive.ics.uci.edu/ml/datasets.html?format=&task=clu&att=&area=&numAtt=&numIns=&type=&sort=nameUp&view=table
1.Kmeans
大致思想就是把数据分为多个堆,每个堆就是一类。每个堆都有一个聚类中心(学习的结果就是获得这k个聚类中心),这个中心就是这个类中所有数据的均值,而这个堆中所有的点到该类的聚类中心都小于到其他类的聚类中心,分类的过程就是将未知数据对这k个聚类中心进行比较的过程。
spark kmeans 算法调用 数据演练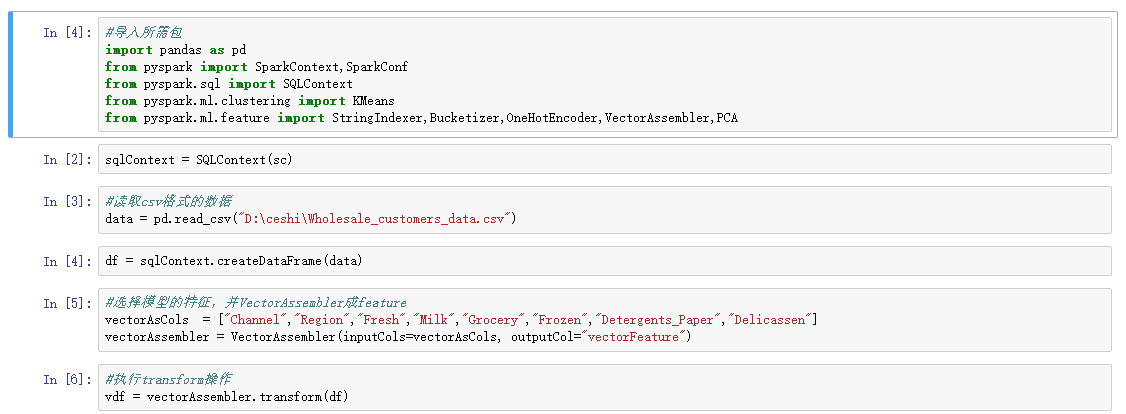
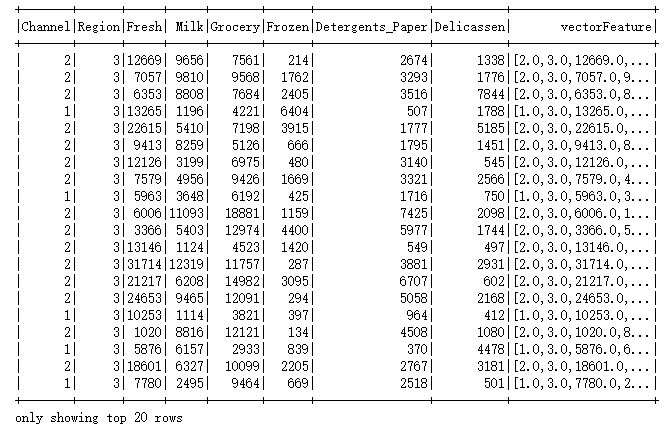

2.GMM
另外一种比较流行的聚类方法 Gaussian Mixture Model
大致思想就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个
Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
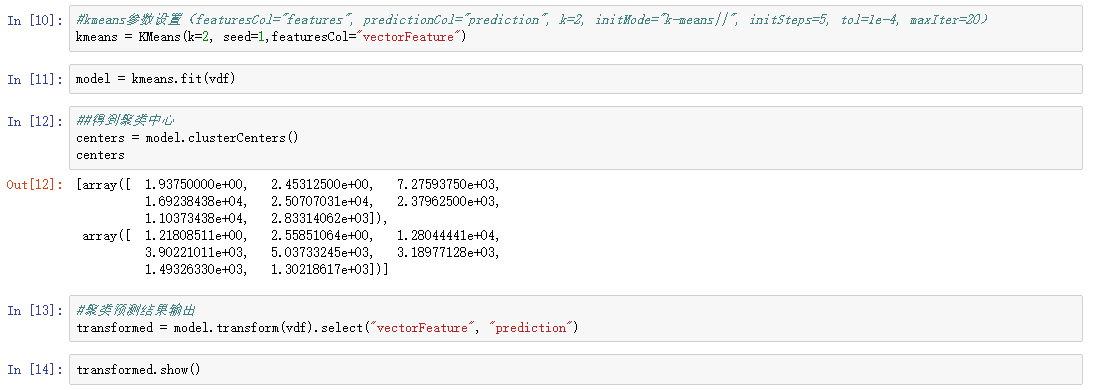
spark GMM 算法调用数据测试:

3.LDA

最后总结一下,用GMM的优点是投影后样本点不是得到一个确定的分类标记,而是得到每个类的概率,这是一个重要信息。GMM每一步迭代的计算量比较大,大于
k-means。GMM的求解办法基于EM算法,因此有可能陷入局部极值,这和初始值的选取十分相关了。GMM不仅可以用在聚类上,也可以用在概率密度估计上。
转自:http://www.cnblogs.com/zhw-080/p/5750482.html
- 基于spark Mllib(ML)聚类实战
- 基于Spark ML 聚类分析实战的KMeans
- spark mllib和ml类里面的区别
- spark mllib 实战
- Spark中ml和mllib的区别
- spark ml和mllib库的说明
- Spark MLlib聚类代码
- Spark 实战,第 6 部分: 基于 Spark ML 的文本分类
- spark MLlib、ML机器学习之Logistic回归
- 请别再问我Spark的MLlib和ML库的区别
- Spark MLlib KMeans聚类算法
- Spark MLLib从入门实战小例子
- spark厦大----KMeans聚类算法 -- spark.mllib
- spark ml 聚类源码笔记一
- spark ml 聚类源码笔记二
- 干货:基于Spark Mllib的SparkNLP库。
- 基于Spark Mllib的文本分类
- Spark入门实战系列--8.Spark MLlib(下)
- 考试总结
- HTTP 延时
- 正向代理和反向代理
- 欢迎使用CSDN-markdown编辑器
- webpack---webpack构建vue多页面框架(三、生产环境与开发环境)
- 基于spark Mllib(ML)聚类实战
- HDUOJ 1285 确定比赛名次(拓扑排序)
- C++对象 NULL
- 进程间通信-----消息队列
- Spark学习-SparkSQL--06-spark读取HBase数据报异常java.io.NotSerializableException
- 【opencv】vc6.0中opencv打开摄像头失败解决方法
- 独占锁和共享锁
- Intellij Idea 15 生成serialVersionUID的方法 默认情况下Intellij IDEA是关闭了继承了Serializable接口的类生成serialVersionUID的警
- HDU 6124-Euler theorem


