一文带你了解Linux平均负载之谜
来源:互联网 发布:朱婷 大冠军杯 知乎 编辑:程序博客网 时间:2024/06/05 05:33
转载自 极客头条 http://geek.csdn.net/news/detail/231709
原文:Linux Load Averages: Solving the Mystery
作者:Brian Cooksey
翻译:lloog
译者注:作者从介绍linux平均负载演变历史及三个关键数值开始,对比不间断任务状态的过去与现在以及如何检测,分解平均负载指标,结合其他指标,分析平均负载优劣这几个方面,多维度解释linux平均负载的含义。
平均负载是业界关键的指标 - 我的公司基于他们和其他指标花费了数百万个自动扩展云实例 - 但是在Linux上有一些谜题。 Linux平均负载不仅跟踪运行的任务,还跟踪不可中断睡眠状态中的任务。 为什么? 我从未见过解释,本文将为你解开这道谜题。
Linux平均负载是“系统平均负载”,显示系统上正在运行的线程(任务),即运行加等待线程的平均数。 这样可以测量系统性能,数值可能比系统当前处理能力要大。 大多数工具显示三个平均值,分别为1,5和15分钟:
$ uptime 16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37$ cat /proc/loadavg 25.72 23.19 23.35 42/3411 43603一些解释:
- 如果平均值为0.0,则系统空闲。
- 如果1分钟之内平均值高于5或15分钟平均值,则负载正在增加。
- 如果1分钟之内平均值低于5或15分钟平均值,则负载正在减少。
- 如果它们高于CPU的数量,那么可能会遇到性能问题。
通过这三个数值,你可以判断负载是增加还是减少,这是有用的。 当需要单一数值时,它们也是有用的,例如对于云自动缩放规则。 但是如果没有其他指标的帮助,理解它们是困难的。 单个值23 - 25,本身并不意味着什么,但如果CPU数量已知,并且如果已知是CPU-bound的工作负载,则可能意味着什么。
我不是尝试调试平均负载,而是我通常切换到其他指标。 我会在靠近结尾处的“更好的指标”部分讨论这些。
历史
原来平均负载仅显示CPU需求:正在运行的进程数量以及等待运行的进程数。 在RFC 546中有一个很好的描述,标题为“TENEX Load Averages”,1973年8月:
[1] TENEX平均负载是CPU使用的度量。平均负载是给定时间段内可运行进程数的平均值。 例如,1小时负载平均值为10,意味着(对于单个CPU系统),在1小时内的任何时候,1个进程正在运行,另外9个等待CPU准备运行(即,I / O不被阻塞)。
ietf.org上有PDF版从1973年7月以来手绘的负载平均图,图上显示已经监控了几十年:
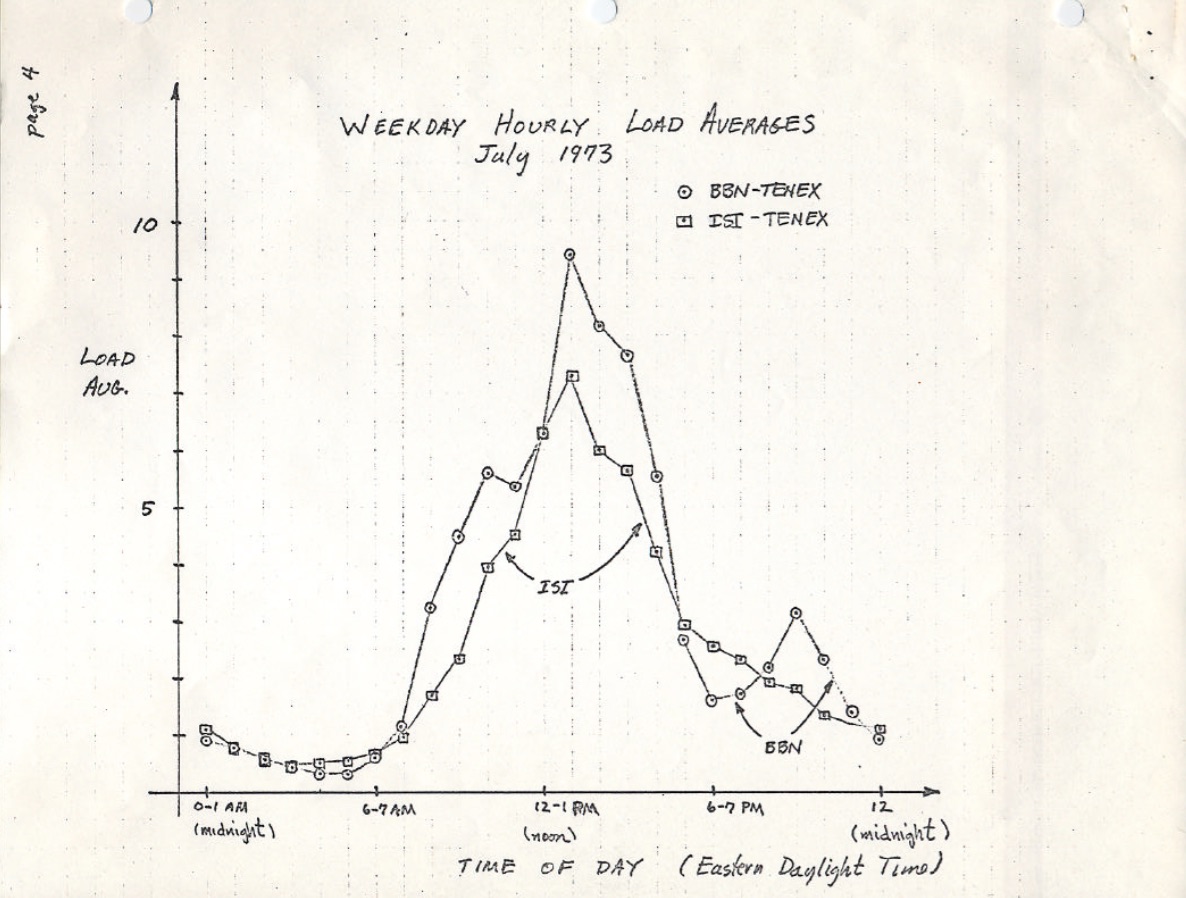
source: https://tools.ietf.org/html/rfc546
如今,老式操作系统的源代码也可以在线查找。 除了TENEX(1970年代初)SCHED.MAC的DEC宏汇编:
NRJAVS==3 ;NUMBER OF LOAD AVERAGES WE MAINTAINGS RJAV,NRJAVS ;EXPONENTIAL AVERAGES OF NUMBER OF ACTIVE PROCESSES[...];UPDATE RUNNABLE JOB AVERAGESDORJAV: MOVEI 2,^D5000 MOVEM 2,RJATIM ;SET TIME OF NEXT UPDATE MOVE 4,RJTSUM ;CURRENT INTEGRAL OF NBPROC+NGPROC SUBM 4,RJAVS1 ;DIFFERENCE FROM LAST UPDATE EXCH 4,RJAVS1 FSC 4,233 ;FLOAT IT FDVR 4,[5000.0] ;AVERAGE OVER LAST 5000 MS[...];TABLE OF EXP(-T/C) FOR T = 5 SEC.EXPFF: EXP 0.920043902 ;C = 1 MIN EXP 0.983471344 ;C = 5 MIN EXP 0.994459811 ;C = 15 MIN如下是现代linux代码
的一段摘录(include/linux/sched/loadavg.h):
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */#define EXP_5 2014 /* 1/exp(5sec/5min) */#define EXP_15 2037 /* 1/exp(5sec/15min) */Linux把1,5和15分钟固定为常数。
在老的系统中已经有类似的平均负载指标,就是具有指数调度队列平均值的Multics。
三个数字
这三个数字是1,5和15分钟的平均负载。 他们不是真的平均,也不是1,5和15分钟。 从上面的来源可以看出,这三个数字展示的是一分钟、五分钟和十五分钟内系统的负载总量平均值按照指数比例压缩得到的结果。 所得到的1,5和15分钟平均负载反映出超过1,5分钟和15分钟的负载。
如果采用空闲系统,开始一个单线程计算密集型工作负载(一个循环中的一个线程),60秒后一分钟的平均负载是多少? 如果是平均水平,那将是1.0。 这是实验绘图:
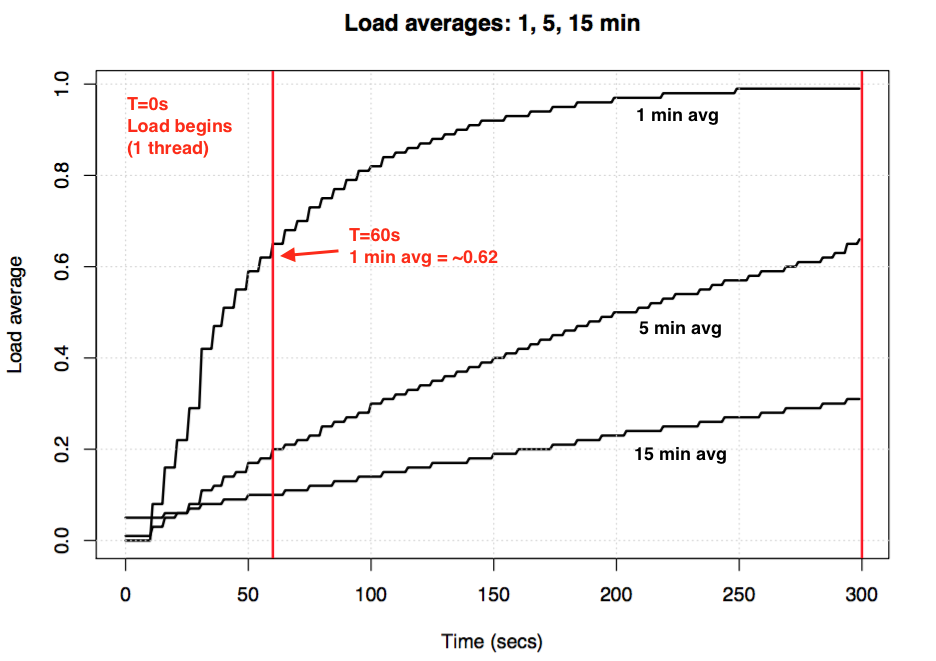
平均负载指数比例实验
所谓“一分钟平均”即一分钟左右达到0.62左右。有关方程式和类似实验的更多信息,Neil Gunther博士撰写了一篇关于平均负载的文章:它如何工作,加上loadavg.c中有许多Linux源代码块注释。
Linux不间断任务
当平均负载首次出现在Linux中时,与其他操作系统一样,它们反映了CPU的需求。但是后来的Linux改变了它们,不仅包括可运行的任务,还包括不间断状态的任务(TASK_UNINTERRUPTIBLE或nr_uninterruptible)。该状态由希望避免信号
中断的代码路径使用,其中包括被磁盘I / O锁住的任务和某些锁。您可能已经看到此状态:它在输出ps和top中显示为“D”状态。 ps(1)手册页将其称为“不可中断的睡眠状态(通常 IO 的进程)。
不间断状态意味着由于磁盘(或NFS)I / O工作负载,Linux平均负载可能会增加,而不仅仅是CPU需求。熟悉其他操作系统及其CPU负载平均的人员,对包括这个状态会很困惑。
为什么?为什么Linux完全是这样做的?
有关平均负载的无数文章,其中许多文章指出了Linux nr_uninterruptible getcha。但是我没有看到一个解释甚至是一个猜测为什么会被包括在内的猜测。我自己的猜测是,它的意图是反映更广泛的需求,而不仅仅是CPU需求。
搜索一个古老的Linux补丁
要了解为什么在Linux中改变某些东西会很简单:你可以在相关文件中读取git提交历史记录,并阅读更改说明。我检查了loadavg.c上的历史记录,但添加不间断状态的更改早于该文件,它在更早的文件中被编码创造出来。我检查了另一个文件,但是那个线索也很少
:代码本身在不同的文件穿梭。希望有快捷方式,我为整个Linux github仓库转储了“git log -p”,这是一个4 GB的文本。并为了查看代码何时出现,我开始向后阅读。这也是一个死胡同。整个Linux repo的最早的变化可以追溯到2005年,早于Linus导入Linux 2.6.12-rc2。
这有早期的Linux repos(这里和[这里]https://kernel.googlesource.com/pub/scm/linux/kernel/git/nico/archive/)),这些文件中
也没有变化描述。至少在发生这种变化的时候,我搜索了kernel.org上的tarball。在0.99.15发生了变化,而0.99.13没有。然而,0.99.14的tarball消失了。我在其他地方找到了它,并确认这个变化是在Linux 0.99 patchlevel 14,11月,1993年。我希望Linus的0.99.14的发布说明会解释这个变化,但那也没有:
“最后一次正式发行(p13)的变化太多了,甚至不记得(…)” - Linus
他提到重大变化,但不是平均负载变化。
根据日期,我查找了内核邮件列表归档以查找实际的修补程序,但是可用的最早的邮件是1995年6月,是由sysadmin写的:
“为了让工作系统使用这些邮件档案更加有效,我不小心摧毁了当前的档案(啊哎呀)。”
我的搜索很艰难。 幸运的是,我发现从服务器备份中获取到的一些较老的linux-devel邮件列表存档,,通常存储为消息的tarball。 我从98,000封电子邮件中查看了超过6,000邮件,其中30,000份来自1993年的邮件,好像失踪了。 它真的看起来好像原来的补丁描述可能会永远丢失,而“为什么”仍然是一个谜。
不间断的起源
幸运的是,我终于在oldlinux.org上找到了一个压缩的邮箱文件。 这里是:
From: Matthias Urlichs <urlichs@smurf.sub.org>Subject: Load average broken ?Date: Fri, 29 Oct 1993 11:37:23 +0200The kernel only counts "runnable" processes when computing the load average.I don't like that; the problem is that processes which are swapping orwaiting on "fast", i.e. noninterruptible, I/O, also consume resources.It seems somewhat nonintuitive that the load average goes down when youreplace your fast swap disk with a slow swap disk...Anyway, the following patch seems to make the load average much moreconsistent WRT the subjective speed of the system. And, most important, theload is still zero when nobody is doing anything. ;-)--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993+++ kernel/sched.c Fri Oct 29 10:32:51 1993@@ -414,7 +414,9 @@ unsigned long nr = 0; for(p = &LAST_TASK; p > &FIRST_TASK; --p)- if (*p && (*p)->state == TASK_RUNNING)+ if (*p && ((*p)->state == TASK_RUNNING) ||+ (*p)->state == TASK_UNINTERRUPTIBLE) ||+ (*p)->state == TASK_SWAPPING)) nr += FIXED_1; return nr; }--Matthias Urlichs \ XLink-POP N|rnberg | EMail: urlichs@smurf.sub.orgSchleiermacherstra_e 12 \ Unix+Linux+Mac | Phone: ...please use email.90491 N|rnberg (Germany) \ Consulting+Networking+Programming+etc'ing 42了解这个24年前变化背后的想法是令人惊讶的。
这证实了平均负载被有意更改是为了反映对其他系统资源的需求,而不仅仅是cpu。Linux从“CPU平均负载”改为“系统平均负载”。
他使用较慢的交换磁盘是有意义的:通过降低系统的性能,系统的需求(以运行+排队的方式来衡量)应该会增加。但是,平均负载减少,因为它们只跟踪CPU运行状态,而不是交换状态。Matthias认为这是不直观的,所以他把它修正了。
今天不间断
有时候Linux平均负载太高,会超过磁盘I / O承载能力吗?是的,我的猜测是这是因1993年不存在使用TASK_UNINTERRUPTIBLE的新代码路径。在Linux 0.99.14中,有13个直接设置TASK_UNINTERRUPTIBLE或TASK_SWAPPING的代码路径(交换状态后来从Linux中删除)。现在,在Linux 4.12中,有近400个设置TAPK_UNINTERRUPTIBLE的代码路径,包括一些锁机制。这些代码路径之一可能不应该包括在平均负载。下一次,我的平均负载值变太高,我就会看是否是这种情况,并且看是否可以修复。
我把电子邮件发送Matthias(第一次),问他关于24年后平均负载变化的想法。他在一小时内这样回复(正如我在Twitter上提到):
“平均负载”是指从人的角度来看系统的繁忙程度,TASK_UNINTERRUPTIBLE意味着(意味着)进程正在等待磁盘读取。如果TASK_RUNNING平均值只有0.1,一个重量级的磁盘系统可能非常缓慢,,这对任何人都没有帮助。“
(得到一个很快的回应,甚至只是一个回应,真的让我的一天,谢谢!)
所以Matthias仍然认为这是有道理的,至少给定TASK_UNINTERRUPTIBLE过去经常使用的含义是什么。
但如今TASK_UNITERRUPTIBLE匹配更多的东西。我们应该将平均负载改为仅仅CPU和磁盘的需求吗?计划维护者Peter Zijstra发给我探索这个的一个聪明选择:为了更符合磁盘I/O,把 task_struct-> in_iowait包括进平均负载而不是TASK_UNINTERRUPTIBLE。然而,它引出一个问题,我们真正想要什么呢?我们想要测量系统上的线程资源,还是仅仅物理资源需求?如果是前者,那么如系统上那些线程需求一样,等待不间断锁也应该被包括进来。他们不是空闲,也许Linux的平均负载已经按照我们想要的方式生效了。
为了更好地了解不间断的代码路径,我想要在实践中检验它。然后我们可以检查不同的例子,量化花费在他们的时间,看看是否有意义。
测量不间断任务
以下是来自伺服器的Off-CPU火焰图,跨越60秒,仅显示内核堆栈。我在服务器上过滤出仅包含这些内容的TASK_UNINTERRUPTIBLE状态(SVG)。 提供了不间断代码路径的许多例子:
Kernel Uninterruptible Off-CPU Flame Graph (60 secs)Reset ZoomSearchmutex_locks..sys_readwa..bit..__m..sch..ret_from..me..ret..process_..me..memcg_offl..synchroni..fin..kworker/12:1schedule_pr..w..fin..finish_ta..fin..ret_from_f..c..mem_cgrou..rcu_..r..proc_cgroup..mut..process_on..w..kworker/3:0re..worker_thr..m..sch.._rc..kworker/8:2sy..sc..b..kthreadprocess_on..kthreadfini..jbd..systemdcss_killed..fin..kth..mem_cgroup..r..process_o.._..process_on..memcg_deac..kworker/..__m..wait..__..finish_task..fi..__w..css..sc..memc..worker_t..css..ret_from_..css_kille..fin..css_fre..fin.._rcu_ba..__wait_rc..sch..kthreadout..worker_thr..me..memcg_dea..sch..cs..process..finish_..__wait_rcu..mut..wait_fo..scheduleschedule_.._r..cgr..m..jbd..schedul..me..kthreadf..mut..memcg_d..t..ret_fro..ret_from_f..css_..cgr..sch..sc..fi..k..css..entry_SYSCA..worker_t..kthreadseq_readk..release..__mutex_loc..mem_..sch..mem..mut..sch..sche..finish_tas..rel..io_..wait_for_..kworker..mem_cgr..mut..vfs_readrcu_bar..schedule_t..wait_for_c..__m..wa..sch..__m..rele..s..worker_th..schedulekworker/6:2s..rc..synchroniz..__w.._rcu..sche..m..p..memcg_off..b..cs..k..kthreadsch..process_..sch..kjo..mem..me..sch..worker_thr..sc..kworker/..sch..kthreadret_from_f..__m..schedulercu..proc_single..__vfs_readret_from..scheduleworker_..如果你刚开始用off-CPU火焰图:您可以点击框架进行放大,检查显示为帧塔的完整堆叠。 x轴尺寸与off-CPU阻塞时间成正比,排序顺序(从左到右)没有任何真正的意义。 off-CPU堆栈颜色为蓝色(我对on-CPU堆栈使用暖色),并且饱和度具有随机方差以区分帧。
我使用我的offcputime工具从bcc(这个工具需要Linux 4.8+的eBPF功能)和我的火焰图软件生成这个:
# ./bcc/tools/offcputime.py -K --state 2 -f 60 > out.stacks# awk '{ print $1, $2 / 1000 }' out.stacks | ./FlameGraph/flamegraph.pl --color=io --countname=ms > out.offcpu.svgb>我使用awk将输出从微秒更改为毫秒。 offcputime用‘–state 2’选项显示TASK_UNINTERRUPTIBLE(请参阅sched.h)。 Facebook上Josef Bacik
用他的kernelscope工具首先这样做,也使用了bcc和火焰图。 在我的示例中,我只是显示内核堆栈,但是offcputime.py也支持显示用户堆栈。
上面的火焰图:它表明在60秒内只有926毫秒花费在不间断睡眠中。 这只使我们的平均负载值增加0.015。 这表明在某些cgroup路径的时候,这个服务器没有做太多的磁盘I / O。
这有更有趣的一个,这次只有10秒(SVG):
右侧的宽塔显示在proc_pid_cmdline_read()(读/ proc / PID / cmdline)中的systemd-journal,被阻止,并为负载平均值贡献0.07。 而在左侧还有一个更宽的塔,到rwsem_down_read_failed()结束(增加0.23加载平均值)。 我使用火焰图搜索功能,用洋红色高亮突出这些功能。 这是rwsem_down_read_failed()的摘录:
/* wait to be given the lock */ while (true) { set_task_state(tsk, TASK_UNINTERRUPTIBLE); if (!waiter.task) break; schedule(); }这是一段使用TASK_UNINTERRUPTIBLE的获取锁的代码。 Linux具有的不可中断和可中断版本的mutex获取函数(例如mutex_lock()vs mutex_lock_interruptible()和down()以及down_interruptible())。可中断版本允许任务被信号中断,然后在获取锁之前唤醒处理它。不间断锁睡眠时间通常不会增加太多负载平均值。但在这种情况下,它们增加了0.30。如果这个变太高,那么值得分析一下看是否可以减少锁争用(例如,我开始挖掘systemd-journal和proc_pid_cmdline_read()!),这样可以提高性能并降低负载平均值。
这些代码路径被包含在平均负载中是否有意义?我会说是的,那些线程正在运行的中间,碰巧被锁阻塞住。它们并不空闲,它们是同样需要系统资源,尽管是软件资源而不是硬件资源。
分解Linux平均负载
Linux平均负载可以完全被分解成元素吗? 这是一个例子:在一个空闲的8 CPU系统上,我启动了tar来存档一些未缓存的文件。 它被磁盘读取阻塞了几分钟时间。 以下是从三个不同终端窗口收集的统计信息:
terma$ pidstat -p `pgrep -x tar` 60Linux 4.9.0-rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU)10:15:51 PM UID PID %usr %system %guest %CPU CPU Command10:16:51 PM 0 18468 2.85 29.77 0.00 32.62 3 tartermb$ iostat -x 60[...]avg-cpu: %user %nice %system %iowait %steal %idle 0.54 0.00 4.03 8.24 0.09 87.10Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilxvdap1 0.00 0.05 30.83 0.18 638.33 0.93 41.22 0.06 1.84 1.83 3.64 0.39 1.21xvdb 958.18 1333.83 2045.30 499.38 60965.27 63721.67 98.00 3.97 1.56 0.31 6.67 0.24 60.47xvdc 957.63 1333.78 2054.55 499.38 61018.87 63722.13 97.69 4.21 1.65 0.33 7.08 0.24 61.65md0 0.00 0.00 4383.73 1991.63 121984.13 127443.80 78.25 0.00 0.00 0.00 0.00 0.00 0.00termc$ uptime 22:15:50 up 154 days, 23:20, 5 users, load average: 1.25, 1.19, 1.05[...]termc$ uptime 22:17:14 up 154 days, 23:21, 5 users, load average: 1.19, 1.17, 1.06我也收集了一个Off-CPU火焰图,仅用于不间断状态(SVG):
最后一分钟的平均负载是1.19。让我分解一下:
- 0.33来自tar的CPU时间(pidstat)
- 0.67是从tar的不间断磁盘读取,推断(offcpu火焰图在0.69,我猜测它开始收集一点点,跨越稍微不同的时间范围)
- 0.04来自其他CPU使用者(mpstat用户+系统,从pidstat减去tar的CPU)
- 0.11来自内核不间断磁盘I / O时间,刷新磁盘写入(offcpu火焰图,左侧的两个塔)
这增加到1.15。仍然缺少0.04,其中一些可能是四舍五入和测量间隔偏移误差,但更可能是由于平均负载被指数比例压缩,而我正在使用的其他平均值(pidstat,iostat)是正常平均值。在1.19之前,一分钟平均为1.25,所以那些因素会导致平均值变高多少?从我以前的图表中,在一分钟的时间里,62%的指标是从那一刻开始的,其余的要早些。所以0.62×1.15 + 0.38×1.25 = 1.18。这是接近1.19的。
这个系统上一个线程(tar)加上(内核工作线程中的一些时间)正在工作,而Linux显示平均负载值为1.19。如果是测量“CPU平均负载”,则系统将报告0.37(从mpstat的摘要推断),这仅对CPU资源是正确的,但是忽略了一个线程工作的需求的事实。
我希望这个例子表明,这些数字真的意义(CPU +不间断的),你可以分解它们并计算出来。
了解Linux平均负载
我在平均负载意味着CPU平均负载的OSes环境下,Linux版本一直困扰着我。 一直以来真正的问题是,“平均负载”一词与“I / O”一样不明确。 哪种类型的I / O? 磁盘I / O? 文件系统I / O? 网络I / O? …同样地,哪个平均负载? CPU平均负载? 系统平均负载? 以这种方式澄清它,让我对此有所了解:
- 在Linux上,对于整个系统,平均负载(或尝试)为“系统平均负载”,测量正在运行和等待运行的线程数(CPU,磁盘,不间断锁)。 换句话说,它衡量不完全空闲的线程数。 优势:包括对不同资源的需求。
- 在其他操作系统中,平均负载为“CPU平均负载”,用于测量运行的CPU数量+ CPU可运行线程数。 优点:可以更容易理解(仅适用于CPU)。
请注意,还有一种可能的类型:“物理资源平均负载”,其中只包括物理资源的负载(CPU +磁盘)。
也许有一天,我们将为Linux添加额外的平均负载,让用户选择他们想要使用的内容:单独的“CPU平均负载”,“磁盘平均负载”,“网络平均负载”等)或只是使用不同的 指标。
什么是“好”或“坏”平均负载?
有些人发现对于他们的系统和工作负载有价值的点:他们知道当负载超过X时,应用程序的延迟很高,消费者开始抱怨。 但是,但对此并没有真正的规则。
使用CPU平均负载,可以将该值除以CPU计数,然后如果该比率超过1.0,则运行在饱和状态,这可能会导致性能问题。 这有点模糊,因为它是一个长期的平均(至少一分钟),这可以隐藏变化。 一个比例为1.5的系统可能运行正常,然而在一分钟内突然爆发到1.5的系统可能会运行不佳。
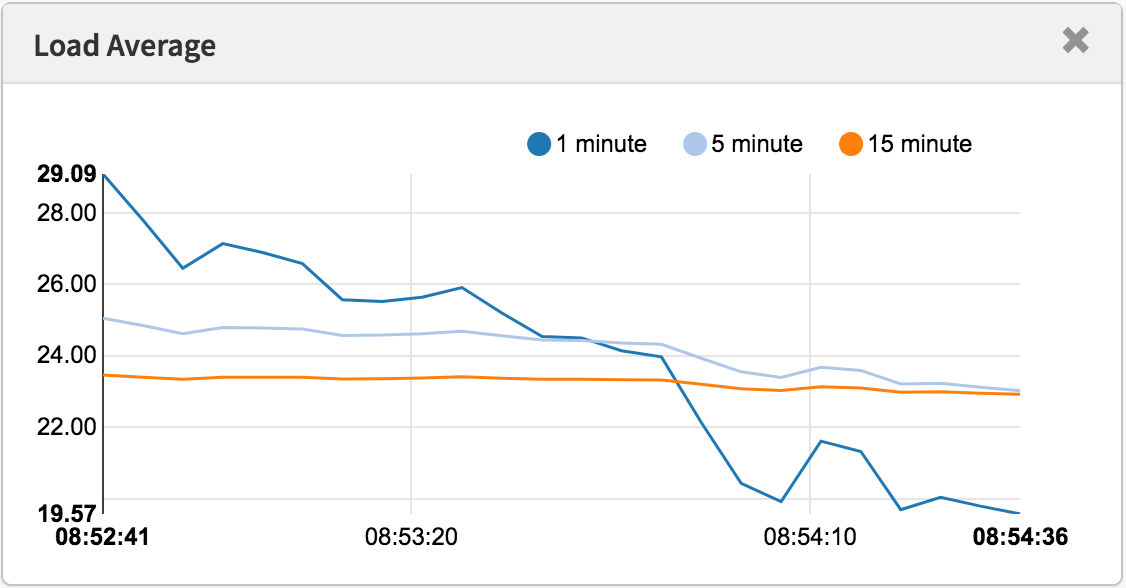
在现代工具中测量的负载平均值
我曾经管理过一个two-CPU电子邮件服务器,当时CPU平均负载值在11到16之间(比例在5.5到8之间)。 延迟是可以接受的,没有人抱怨。 这是一个极端的例子:大多数系统负载/ CPU比率只有2。
至于Linux的系统平均负载:由于它们涵盖不同的资源类型,所以它们更加模糊,所以你不能仅仅除以CPU数。 它对于相对比较更有用:如果你知道在负载为20时系统运行正常,现在为负载40,那么要使用其他指标来查看会发生什么。
更好的指标
当Linux平均负载值增加时,你知道系统对资源(CPU,磁盘和某些锁)的需求变高,但你不确定是哪个。 你可以使用其他指标来进行辨别。 例如,CPU:
- per-CPU利用率:例如,使用mpstat -P ALL 1
- per-process CPU利用率:例如,top,pidstat 1等
- per-thread 运行队列(调度程序)延迟:例如,在/ proc / PID / schedstats,delaystats,perf sched
- CPU运行队列延迟:例如,在/ proc / schedstat,perf sched,我的runqlat bcc工具。
- CPU运行队列长度:例如,使用vmstat 1和’r’列或我的runqlen bcc工具
前两个是利用率指标,最后三个是饱和指标。利用率指标对于工作负载表征有作用,饱和度指标对于识别性能问题有用。最佳CPU饱和度指标是运行队列(或调度程序)延迟的度量:任务/线程处于可运行状态的时间,但必须等待轮到自己。这些使你可以计算性能问题的大小,例如线程在调度器延迟中花费的时间百分比。测量运行队列长度可能表明存在问题,但难以估计问题大小。
schedstats facility在Linux 4.6(sysctl kernel.sched_schedstats)中成为内核可调参数,默认情况下更改为关闭。在cpustat中延迟计数显示类似于调度器延迟指标,我只是建议将其也添加到htop中,这样可以使人们更容易使用。从(未记录)/ proc / sched_debug输出中删除wait-time(调度器延迟)指标更容易:
$ awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug task PID tree-key switches prio wait-time sum-exec sum-sleep systemd 1 5028.684564 306666 120 43.133899 48840.448980 2106893.162610 0 0 /init.scope ksoftirqd/0 3 99071232057.573051 1109494 120 5.682347 21846.967164 2096704.183312 0 0 / kworker/0:0H 5 99062732253.878471 9 100 0.014976 0.037737 0.000000 0 0 / migration/0 9 0.000000 1995690 0 0.000000 25020.580993 0.000000 0 0 / lru-add-drain 10 28.548203 2 100 0.000000 0.002620 0.000000 0 0 / watchdog/0 11 0.000000 3368570 0 0.000000 23989.957382 0.000000 0 0 / cpuhp/0 12 1216.569504 6 120 0.000000 0.010958 0.000000 0 0 / xenbus 58 72026342.961752 343 120 0.000000 1.471102 0.000000 0 0 / khungtaskd 59 99071124375.968195 111514 120 0.048912 5708.875023 2054143.190593 0 0 /[...] dockerd 16014 247832.821522 2020884 120 95.016057 131987.990617 2298828.078531 0 0 /system.slice/docker.service dockerd 16015 106611.777737 2961407 120 0.000000 160704.014444 0.000000 0 0 /system.slice/docker.service dockerd 16024 101.600644 16 120 0.000000 0.915798 0.000000 0 0 /system.slice/[...]除CPU指标外,您还可以查找磁盘设备的利用率和饱和度指标。我在USE方法中关注这些指标,并且有一个Linux清单。
除CPU指标外,您还可以查找磁盘设备的利用率和饱和度指标。我在USE method 中关注这些指标,并且有一个关于这些指标的Linux清单。
虽然有更精细的指标,但这并不意味着平均负载是无用的。结合其他指标,它们成功地用于云计算微服务的扩展策略。这有助于微服务器响应不同类型的增加的负载,CPU或磁盘I / O。通过这些策略,在扩大(花钱)上犯错比不扩大(花费客户)更安全,因此需要包含更多信号。
我继续使用平均负载是由于他们的历史信息。假如我被要求在云端查看一个性能不佳的实例,然后登录并发现一分钟平均值比十五分钟的平均低得多,这表明我可能太迟以至于没看到实时性能问题。但是,在转向其他指标之前,我花了几秒钟考虑平均负载。
结论
1993年,一名Linux工程师发现了平均负载,并用three-line补丁将它们永远从“CPU平均负载”改为“系统平均负载”。他的改变是包括了不间断状态的任务,因此平均负载反映了磁盘资源的需求,而不仅仅是CPU。这些系统平均负载计算运行和等待运行的进程数(等待CPU,磁盘和不间断锁),并被归纳为一分钟、五分钟和十五分钟内系统的负载总量平均值按照指数比例压缩得到的结果,这个三元组可以让你看到负载是否在增加或减少,它们的最大值是与自身的相对比较。
不间断状态的使用已经在Linux内核中发展起来,现在包括不间断的锁机制。如果平均负载是测量运行和等待的进程(而不是严格要求硬件资源的进程)资源,那么它们正按照我们想要的方式工作了。
在这篇文章中,我挖掘出来自1993年包含作者的原始解释的Linux平均负载修补程序,这是非常难以找到的 。我也测量跟踪堆栈并还在现代Linux系统上使用bcc / eBPF将不间断状态的时间可视化为off-CPU火焰图。这种可视化的图提供了不间断睡眠的许多示例,并被生成用以解释不寻常的高平均负载。除了平均负载,我还提出了其他可用指标用于更详细地了解系统负载。
我引用计划维护者Peter Zijlstra 在Linux源代码kernel / sched / loadavg.c顶部的评论作为结束:
*此文件包含计算全局平均负载所需的魔术位数*figure。我们正经历它是一个愚蠢的数字,但人们认为它重要。 *最大的痛苦让它在大机器和tickless内核上生效。参考
- Saltzer,J.和J. Gintell。 “多仪器仪表”,CACM,1970年8月(解释指数)。
- Multics system_performance_graph命令参考(提到1分钟平均)。
- TENEX源代码(负载平均代码在SCHED.MAC中)。
- RFC 546“1973年7月的TENEX负载平均值”(说明测量CPU需求)。
- Bobrow,D.,et al。 “TENEX:用于PDP-10的分页时间共享系统”,ACM的通信,1972年3月(解释平均负载三元组)。
- Gunther,N.“UNIX平均负载第1部分:工作原理”PDF(指数计算解释)。
- Linus关于Linux 0.99 patchlevel的电子邮件14。
- 平均负载更改电子邮件位于oldlinux.org(在alan-old-funet-lists / kernel.1993.gz中,而不是在我厡先搜索的linux目录中)。
- Linux内核/ sched.c源前后平均负载变化:0.99.13,0.99.14。
- 用于Linux的Tarballs 0.99发行版在[kernel.org]https://www.kernel.org/pub/linux/kernel/Historic/v0.99/)上。
- 目前的Linux平均负载代码:loadavg.c,loadavg.h
- bcc分析工具包括我的offcputime,用于跟踪TASK_UNINTERRUPTIBLE。
- 火焰图用于可视化不间断路径。
- 一文带你了解Linux平均负载之谜
- 一文带你了解Linux平均负载之谜
- Linux服务器之平均负载
- linux平均负载
- linux平均负载
- Linux系统平均负载
- Linux平均负载
- linux系统平均负载
- 【linux】Linux平均负载查看
- Linux之uptime主机运行时间及平均负载含义
- Linux系统的平均负载
- linux系统的平均负载
- linux系统的平均负载
- linux /proc/loadavg(平均负载)
- Linux系统的平均负载
- Linux load average平均负载
- Linux系统的平均负载
- linux /proc/loadavg(平均负载)
- Discuz!教程之如果修改或删除回复别人的回帖的时候显示的引用信息
- C++ ofstream和ifstream详细用法
- C语言:实现线性表基本表示(数组元素的删除,插入,合并)
- C++ CFileFind() 查找当前路径下所有文件夹名称
- UGUI检测鼠标进入退出
- 一文带你了解Linux平均负载之谜
- C语言中宏的使用
- 【DL--16】深度学习架构清单
- /etc/fstab 参数详解及如何设置开机自动挂载
- 剑指offer60 层序打印二叉树
- Qt——开始
- opencv
- C++的static用法
- 不起眼的 z-index 却能牵扯出这么大的学问


