Linux Shell实现多进程并发执行
来源:互联网 发布:淘宝怎么上传工商执照 编辑:程序博客网 时间:2024/06/06 13:16
在bash中,使用后台任务来实现任务的“多进程化”。在不加控制的模式下,不管有多少任务,全部都后台执行。也就是说,在这种情况下,有多少任务就有多少“进程”在同时执行。我们就先实现第一种情况:
实例一:正常情况脚本
———————————————————————————–
#!/bin/bash
for ((i=0;i<5;i++));do
{
sleep 1;echo 1>>aa && echo ”done!”
}
done
cat aa|wc -l
rm aa
———————————————————————————–
这种情况下,程序顺序执行,每个循环3s,共需15s左右。
$ time bash test.sh
done!
done!
done!
done!
done!
5
real 0m15.030s
user 0m0.002s
sys 0m0.003s
实例二:“多进程”实现
———————————————————————————–
#!/bin/bash
for ((i=0;i<5;i++));do
{
sleep 3;echo 1>>aa && echo ”done!”
} &
done
wait
cat aa|wc -l
rm aa
———————————————————————————–
这个实例实际上就在上面基础上多加了一个后台执行&符号,此时应该是5个循环任务并发执行,最后需要3s左右时间。
$ time bash test.sh
done!
done!
done!
done!
done!
5
real 0m3.011s
user 0m0.002s
sys 0m0.004s
效果非常明显。
这里需要说明一下wait的左右。wait是等待前面的后台任务全部完成才往下执行,否则程序本身是不会等待的,这样对后面依赖前面任务结果的命令来说就可能出错。例如上面wc
-l的命令就报错:不存在aa这个文件。
以上所讲的实例都是进程数目不可控制的情况,下面描述如何准确控制并发的进程数目。
——————————————————————————————————————
#!/bin/bash
# 2006-7-12, by wwy
#———————————————————————————–
# 此例子说明了一种用wait、read命令模拟多线程的一种技巧
# 此技巧往往用于多主机检查,比如ssh登录、ping等等这种单进程比较慢而不耗费cpu的情况
# 还说明了多线程的控制
#———————————————————————————–
function a_sub { # 此处定义一个函数,作为一个线程(子进程)
sleep 3 # 线程的作用是sleep 3s
}
tmp_fifofile=”/tmp/$.fifo”
mkfifo $tmp_fifofile # 新建一个fifo类型的文件
exec 6<>$tmp_fifofile # 将fd6指向fifo类型
rm $tmp_fifofile
thread=15 # 此处定义线程数
for ((i=0;i<$thread;i++));do
echo
done >&6 # 事实上就是在fd6中放置了$thread个回车符
for ((i=0;i<50;i++));do # 50次循环,可以理解为50个主机,或其他
read -u6
# 一个read -u6命令执行一次,就从fd6中减去一个回车符,然后向下执行,
# fd6中没有回车符的时候,就停在这了,从而实现了线程数量控制
{ # 此处子进程开始执行,被放到后台
a_sub && { # 此处可以用来判断子进程的逻辑
echo ”a_sub is finished”
} || {
echo ”sub error”
}
echo >&6 # 当进程结束以后,再向fd6中加上一个回车符,即补上了read -u6减去的那个
} &
done
wait # 等待所有的后台子进程结束
exec 6>&- # 关闭df6
exit 0
——————————————————————————————————————
sleep 3s,线程数为15,一共循环50次,所以,此脚本一共的执行时间大约为12秒
即:
15×3=45, 所以 3 x 3s = 9s
(50-45=5)<15, 所以 1 x 3s = 3s
所以 9s +
3s = 12s
$ time ./multithread.sh >/dev/null
real 0m12.025s
user 0m0.020s
sys 0m0.064s
而当不使用多线程技巧的时候,执行时间为:50 x 3s = 150s。
此程序中的命令 mkfifo tmpfile和linux中的命令 mknod tmpfile p效果相同。
区别是mkfifo为POSIX标准,因此推荐使用它。该命令创建了一个先入先出的管道文件,并为其分配文件标志符6。管道文件是进程之间通信的一种方式,注意这一句很重要
exec 6<>$tmp_fifofile # 将fd6指向fifo类型
如果没有这句,在向文件$tmp_fifofile或者&6写入数据时,程序会被阻塞,直到有read读出了管道文件中的数据为止。而执行了上面这一句后就可以在程序运行期间不断向fifo类型的文件写入数据而不会阻塞,并且数据会被保存下来以供read程序读出
******************************************************************************
http://bbs.51cto.com/thread-1104907-1-1.html
根据我个人的理解, 所谓的多进程 只不过是将多个任务放到后台执行而已,很多人都用到过,所以现在讲的主要是控制,而不是实现。
先看一个小shell:
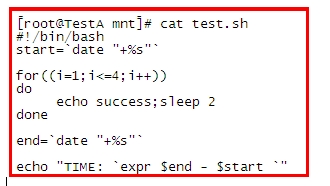
看执行结果: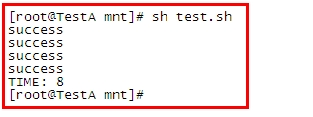
很明显是8s
=============================
这种不占处理器却有很耗时的进程,我们可以通过一种后台运行的方式
来达到节约时间的目的。看如下改进: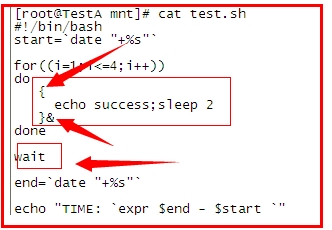
用“{}”将主执行程序变为一个块,用&放入后台,四次执行全部放入后台后,我们
需要用一个wait指令,等待所有后台进程执行结束,
不然 系统是不会等待的,直接继续执行后续指令,知道整个程序结束。
看结果: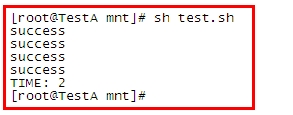
可以看到,时间已经大大缩短了!
============================
以上实验虽然达到了多线程并发的目的,但有一个缺陷,不能控制
运行在后台的进程数。
为了控制进程,我们引入了管道 和文件操作符。
无名管道: 就是我们经常使用的 例如: cat text | grep "abc"
那个“|”就是管道,只不过是无名的,可以直接作为两个进程的数据通道
有名管道: mkfilo 可以创建一个管道文件 ,例如: mkfifo fifo_file
管道有一个特点,如果管道中没有数据,那么取管道数据的操作就会停滞,直到
管道内进入数据,然后读出后才会终止这一操作,同理,写入管道的操作
如果没有读取操作,这一个动作也会停滞。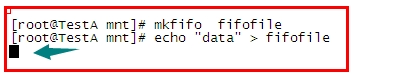
当我们试图用echo想管道文件中写入数据时,由于没有任何进程在对它做读取操作,所以
它会一直停留在那里等待读取操作,此时我们在另一终端上用cat指令做读取操作
你会发现读取操作一旦执行,写入操作就可以顺利完成了,同理,先做读取操作也是一样的:
由于没有管道内没有数据,所以读取操作一直滞留在那里等待写入的数据
一旦有了写入的数据,读取操作立刻顺利完成
以上实验,看以看到,仅仅一个管道文件似乎很难实现 我们的目的(控制后台线程数),
所以 接下来介绍 文件操作符,这里只做简单的介绍,如果不熟悉的可以自行查阅资料。
系统运行起始,就相应设备自动绑定到了 三个文件操作符 分别为 0 1 2 对应 stdin ,stdout, stderr 。
在 /proc/self/fd 中 可以看到 这三个三个对应文件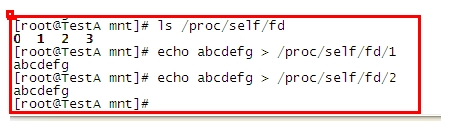
输出到这三个文件的内容都会显示出来。只是因为显示器作为最常用的输出设备而被绑定。
我们可以exec 指令自行定义、绑定文件操作符
文件操作符一般从3-(n-1)都可以随便使用
此处的n 为 ulimit -n 的定义值得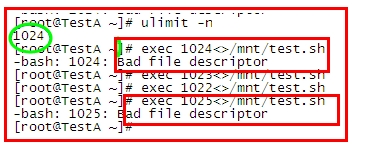
可以看到 我的 n值为1024 ,所以文件操作符只能使用 0-1023,可自行定义的 就只能是 3-1023 了。
直接上代码,然后根据代码分析每行代码的含义: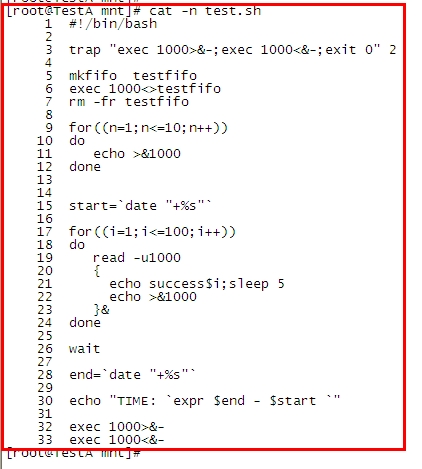
第3行: 接受信号 2 (ctrl +C)做的操作
exec 1000>&-和exec 1000<&- 是关闭fd1000的意思
我们生成做绑定时 可以用 exec 1000<>testfifo 来实现,但关闭时必须分开来写
> 读的绑定,< 标识写的绑定 <> 则标识 对文件描述符 1000的所有操作等同于对管道文件
testfifo的操作。
第5-7行: 分别为 创建管道文件,文件操作符绑定,删除管道文件
可能会有疑问,为什么不能直接使用管道文件呢?
事实上,这并非多此一举,刚才已经说明了管道文件的一个重要特性了,那就是读写必须同时存在
缺少某一种操作,另一种操作就是滞留,而绑定文件操作符 正好解决了这个问题。
(至于为什么,我还没研究明白,有知道的 还请告知,谢谢)
第9-12 行: 对文件操作符进行写入操作。 通过一个for循环写入10个空行,这个10就是我们要定义的后台线程数量。
为什么写入空行而不是10个字符呢 ?
这是因为,管道文件的读取 是以行为单位的。
当我们试图用 read 读取管道中的一个字符时,结果是不成功的,而刚才我们已经证实使用cat是可以读取的。
第17-24行: 这里假定我们有100个任务,我们要实现的时 ,保证后台只有10个进程在同步运行 。
read -u1000 的作用是:读取一次管道中的一行,在这儿就是读取一个空行。
减少操作附中的一个空行之后,执行一次任务(当然是放到后台执行),需要注意的是,这个任务在后台执行结束以后
会向文件操作符中写入一个空行,这就是重点所在,如果我们不在某种情况某种时刻向操作符中写入空行,那么结果就是:
在后台放入10个任务之后,由于操作符中没有可读取的空行,导致 read -u1000 这儿 始终停顿。
后边的 就不用解释了,贴下执行结果: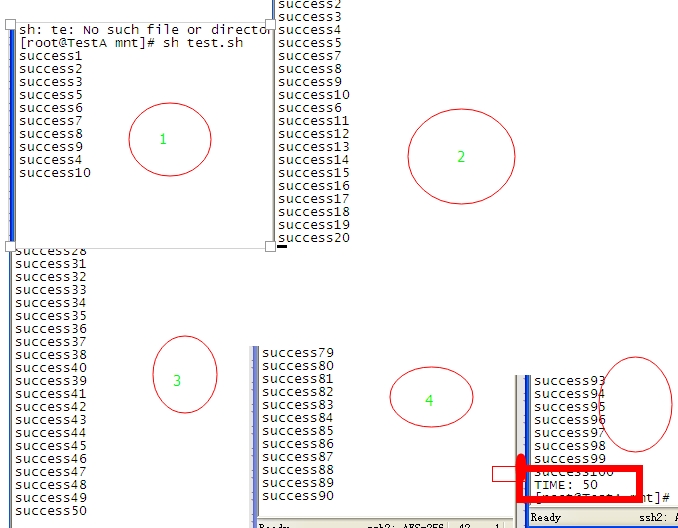
每次的停顿中都能看到 只有10个进程在运行
一共耗时50s
一共100个任务,每次10个 ,每个5s 正好50s
上边的结果图之所以这么有规律,这是因为我们所执行的100个任务耗时都是相同的,
比如,系统将第一批10个任务放入后台的过程所消耗的时间 几乎可以忽略不计,也就是说
这10个任务几乎可以任务是同时运行,当然也就可以认为是同时结束了,而按照刚才的分析,
一个任务结束时就会向文件描述符写入空行,既然是同时结束的,那么肯定是同时写入的空行,
所以下一批任务又几乎同时运行,如此循环下去的。
实际应用时,肯定不是这个样子的,比如,第一个放到后台执行的任务,是最耗时间的,
那他肯定就会是最后一个执行完毕。
所以,实际上来说,只要有一个任务完成,那么下一个任务就可以被放到后台并发执行了。
- Linux Shell实现多进程并发执行
- Linux Shell实现多进程并发执行
- Linux Shell实现模拟多进程并发执行
- Shell实现多进程并发执行
- bash shell实现并发多进程操作
- [Linux]Linux Shell多进程并发以及并发数控制
- Linux下shell并发执行
- Linux shell 监控 进程执行
- Linux shell 监控 进程执行
- [Linux]Shell多进程并发—简易版
- [Linux]shell多进程并发—详细版
- linux shell命名管道FIFO(多进程动态并发)
- shell中的多进程【并发】
- shell多进程并发控制
- shell中的多进程【并发】
- shell中的多进程【并发】
- linux shell多进程
- shell脚本并发执行
- vim指令大全
- ThinkPHP3.2.3单字母方法及部分函数汇总
- 输入一个5X5的二维数组,将数组进行排序,其中一维数组按照平均值降序,一维数组内部升序排列。
- Codeblocks自动代码格式化
- 软件测试黑马工程师---qtp自动化测试练习
- Linux Shell实现多进程并发执行
- [leetcode] 46. Permutations
- Mysql开机自启以及常见SQL语法
- java mail邮件开发基本操作
- Spring-data-redis的简单使用
- zcmu-1670
- shell脚本的几种不同执行方式的区别实验
- ECharts3笔记--使用Java快速开发ECharts图表
- 2017年8月12日提高组T1 YMW的杯子


