生成对抗网络简介(包含TensorFlow代码示例)【翻译】
来源:互联网 发布:kali linux配置ip地址 编辑:程序博客网 时间:2024/06/07 04:45
- 判别模型 vs. 生成模型
- 示例:近似一维高斯分布
- 提高样本多样性
- 最后的思考
- 关于GAN的一些讨论
最近,大家对生成模型的兴趣又开始出现(OpenAI关于生成模型的案例)。生成模型可以学习如何生成数据,这些数据和我们给定的数据很类似(真实数据)。我们用一个例子来描述这背后的原理,比如,我们希望构建一个模型,可以生成高质量的新闻,那么它必须先学习很多的新闻文章。或者说,模型的内部应当有一个很好的关于新闻文档的表示方式。我们希望用这个表示方式来帮助我们完成相关的任务,比如通过主题给新闻进行分类。
事实上,训练这样的一个模型并不容易,但是最近几年,此类研究进展很大。其中一个非常有名的模型就是生成对抗网络(Generative Adversarial Networks, GANs)。Facebook著名的AI研究院院长和深度学习研究专家Yann LeCun,最近将GANs称为深度学习中最为重要的发展:
“There are many interesting recent development in deep learning…The most important one, in my opinion, is adversarial training (also called GAN for Generative Adversarial Networks). This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.” – Yann LeCun
这篇博客剩下的部分就来详细描述GAN的形成,并提供一个非常简单的示例(包含一个TensorFlow代码),使用GAN来解决一个小问题。
判别模型 vs. 生成模型
GAN是一个非常有趣的想法,它首先由University of Montreal的Ian Goodfellow(现在在OpenAI)在2014年提出的。GAN背后的想法包含两个竞争性的神经网络模型。其中一个将噪音作为输入,并产生一些样本(生成器)。另一个模型(判别器)则同时接受生成器生成的数据和真实的数据,并分别出它们的来源。这两个网络坐连续的博弈,其中生成器会生成的数据应当与真实数据越来越像,而判别器则逐渐具有更好的判别能力。这两个神经网络同时训练,并最终使得生成模型生成的数据与真实数据几乎没有差异。
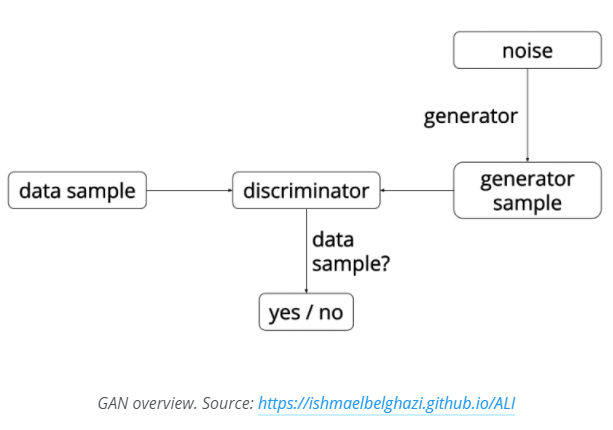
在这里,经常可以看到生成器一般被类比为伪造者尝试生产假币,而判别器被当作是警察,尝试甄别出假币。这个设定和增强学习有点像,生成器会从判别器那里接受到一个奖励信号,可以知道它生成的数据是否正确。但是增强学习和GAN最大的区别是我们可以从判别模型到生成模型反向传播梯度信息。所以生成器知道如何调整参数以更好的生成数据并骗过判别器。
目前,GANs主要运用在自然图像的建模中。他们可以完成非常棒的图像生成任务。他们可以生成比其它用极大似然作为训练目标的模型更锐利的图像。如下图,是GANs产生的一些图像示例:

Generated bedrooms. Source: “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” https://arxiv.org/abs/1511.06434v2

Generated CIFAR-10 samples. Source: “Improved Techniques for Training GANs” https://arxiv.org/abs/1606.03498
示例:近似一维高斯分布
为了更好地理解它的工作原理,我们使用一个GAN解决一个简单的问题——学习近似一个一维高斯分布。这是根据Eric Jang的一篇博客的示例。全部的演示代码见https://github.com/AYLIEN/gan-intro 。这里我们只关注我们感兴趣的代码片段。
首先,我们创建一个真实的分布,一个均值为4,标准差为0.5的高斯分布。我们可以从这个函数中得到一些该分布的样本(按值排序)。
class DataDistribution(object):def __init__(self):self.mu = 4self.sigma = 0.5def sample(self, N):samples = np.random.normal(self.mu, self.sigma, N)samples.sort()return samples
这个分布的如下图所示:

同时,我们也定义一个生成器,输入为噪音分布(样本函数与之前类似)。根据Eric Jang的例子,我们也使用分层抽样方法产生生成器的输入噪音。样本首先从一个范围中均匀抽取,并随机受到扰动。
class GeneratorDistribution(object):def __init__(self, range):self.range = rangedef sample(self, N):return np.linspace(-self.range, self.range, N) + np.random.random(N) * 0.01
我们的生成器和判别器网络非常简单。生成器用一个线性转换,通过一个非线性(a softplus function)传递,然后接着另一个线性转换:
def generator(input, hidden_size):h0 = tf.nn.softplus(linear(input, hidden_size, 'g0'))h1 = linear(h0, 1, 'g1')return h1
在这个例子中,我们发现判别器必须要比生成器厉害,否则的话它就无法区别出样本正确的来源。因此,我们使用一个更加深层的网络,维度很高。除了最终层外,使用tanh非线性。最终层是sigmoid函数。
def discriminator(input, hidden_size):h0 = tf.tanh(linear(input, hidden_size * 2, 'd0'))h1 = tf.tanh(linear(h0, hidden_size * 2, 'd1'))h2 = tf.tanh(linear(h1, hidden_size * 2, 'd2'))h3 = tf.sigmoid(linear(h2, 1, 'd3'))return h3
我们使用TensorFlow图吧这些片段连接起来。同时,我们也为每层网络定一个了一个损失函数,目标是生成器能骗过判别器。
with tf.variable_scope('G'):z = tf.placeholder(tf.float32, shape=(None, 1))G = generator(z, hidden_size)with tf.variable_scope('D') as scope:x = tf.placeholder(tf.float32, shape=(None, 1))D1 = discriminator(x, hidden_size)scope.reuse_variables()D2 = discriminator(G, hidden_size)loss_d = tf.reduce_mean(-tf.log(D1) - tf.log(1 - D2))loss_g = tf.reduce_mean(-tf.log(D2))
我们使用TensorFlow中GradientDescentOptimizer来优化每层网络。我们应当注意到找出好的优化参数需要调整好参数。
def optimizer(loss, var_list):initial_learning_rate = 0.005decay = 0.95num_decay_steps = 150batch = tf.Variable(0)learning_rate = tf.train.exponential_decay(initial_learning_rate,batch,num_decay_steps,decay,staircase=True)optimizer = GradientDescentOptimizer(learning_rate).minimize(loss,global_step=batch,var_list=var_list)return optimizervars = tf.trainable_variables()d_params = [v for v in vars if v.name.startswith('D/')]g_params = [v for v in vars if v.name.startswith('G/')]opt_d = optimizer(loss_d, d_params)opt_g = optimizer(loss_g, g_params)
为了训练好这个模型,我们从数据分布中抽取一部分数据以及噪音分布,并在优化生成器参数和判别器参数之间来回切换。
with tf.Session() as session:tf.initialize_all_variables().run()for step in xrange(num_steps):# update discriminatorx = data.sample(batch_size)z = gen.sample(batch_size)session.run([loss_d, opt_d], {x: np.reshape(x, (batch_size, 1)),z: np.reshape(z, (batch_size, 1))})# update generatorz = gen.sample(batch_size)session.run([loss_g, opt_g], {z: np.reshape(z, (batch_size, 1))})
模型动画的训练演示参考(请自备梯子):https://youtu.be/mObnwR-u8pc
在这里我们看到,开始的时候生成器的生成结果与真实数据差异很大。在迭代很多次之后(大约在750次迭代之后)就会接近真实分布了。但是在收敛之前,它一直在输入分布均值附近优化。最后的训练结果如下图所示:
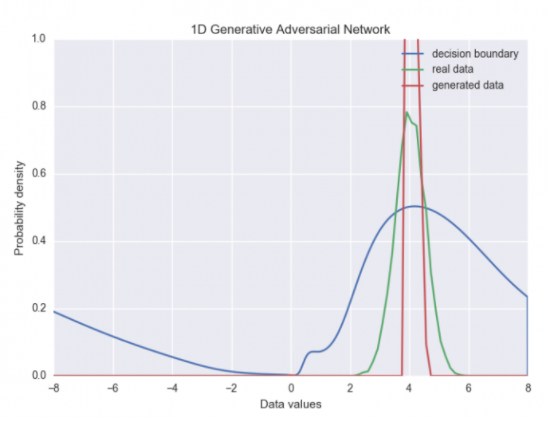
这背后的原理也容易理解。判别器是以单独的样本来看真实数据和生成器生成数据的。如果生成器能够产生真实数据均值附近的数据就能够骗过判别器。
有很多方法都能解决这个问题。在这个例子中,我们可以增加某种早期停止排序的内容,当两个分部之间的相似性达到一个阈值的时候就停止训练。然而,我们很难有一个更加泛化的方法运用在更加复杂的问题上。即便在这个简单的例子上,也很难保证在早期停止的时候生成器的分布可以达到某种程度。最好的方式是是的判别器可以同时检测多个样本。
提高样本多样性
根据Tim Salimans和他在OpenAI里的同事最近的工作,GAN的一个主要问题是生成器可能会在某个参数的环境下崩塌,并输出一个不太好的分布。他们提出了一个解决方案:运行判别器同时查看多个样本,称为minibatch discrimination。
在这篇文章中,minibatch discrimination判别被定义成任何一个方法,其判别器能够同时检测所有的样本,并决定哪些是从生成器生成的,哪些是真实样本。他们也提出了一个具体的方法,可以为一个给定的样本和其他样本之间的距离进行批建模。这些距离然后与原始的样本联结起来,并传递给判别器,因此,它在分类的时候即使用了样本也使用了距离。
这个方法可以简单地总结如下:
- 取出判别器中间层的某些输出。
- 通过一个3D张量相乘得到一个矩阵(下面代码中的of size num_kernels x kernel_dim)。
- 计算这个矩阵中行间的L1距离,并应用在一个负指数上。
- 一个样本的minibatch特征是这些指数距离的总和。
- 使用新创建的minibatch特征把原始输入和这个minibatch层联结起来,并把这个传给判别器的下一个输入。
在TensorFlow中,可以变成如下形式:
def minibatch(input, num_kernels=5, kernel_dim=3):x = linear(input, num_kernels * kernel_dim)activation = tf.reshape(x, (-1, num_kernels, kernel_dim))diffs = tf.expand_dims(activation, 3) - tf.expand_dims(tf.transpose(activation, [1, 2, 0]), 0)abs_diffs = tf.reduce_sum(tf.abs(diffs), 2)minibatch_features = tf.reduce_sum(tf.exp(-abs_diffs), 2)return tf.concat(1, [input, minibatch_features])
新的训练过程如下(请自备梯子):https://youtu.be/0r3g7-4bMYU
显然,加了minibatch之后生成器的分布更加宽了。收敛后如下图所示:
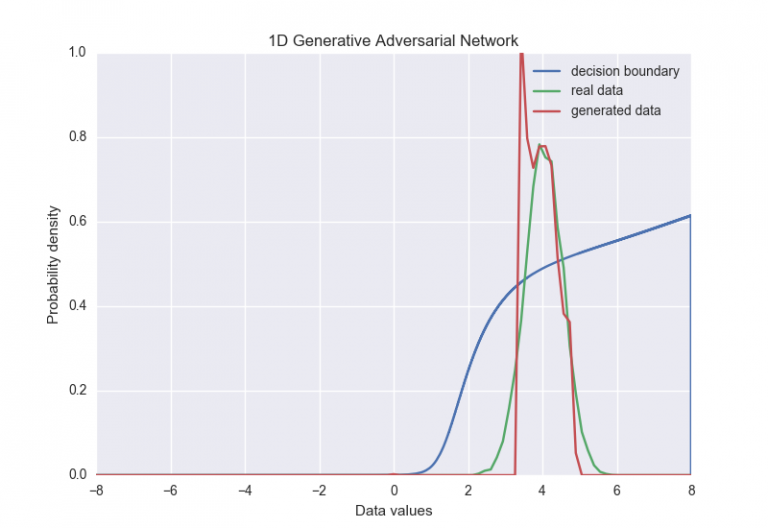
最后一点,batch大小比超参数更加重要。在我们的例子中,我们设置的比较小(小于16附近)。
最后的思考
生成对抗网络给了我们一个全新的角度来做无监督的学习。GANs的大多数成功的应用都在图像识别领域,但是我们正在把研究拓展到自然语言处理中。其中一个重要的问题是如何评价这些模型。在图像识别中我们可以通过看生成的图片来确定这些模型的好坏,尽管这不是一个好的方法。在文本领域,这没什么用处。在基于极大似然的训练模型中,我们可以基于似然产生未观测数据的度量,但是这并不在这里合适。从产生的样本中,产生基于核密度估计的GAN论文在这里有一些。但是在高维数据中并不合适。另一个解决方案是基于一些接下来的任务做评价(如分类)。
关于GAN的一些讨论
最后,我们提供一些关于GAN的讨论:
(本文原文)An introduction to Generative Adversarial Networks (with code in TensorFlow)
Ian Goodfellow关于GAN在NLP任务中应用困难的解释
从对抗样本出发解释GAN
知乎关于GAN的最新发展的讨论
Ian Goodfellow在NIPS2016上作得关于GAN的汇报
七月在线关于上述汇报的翻译
国立台湾大学李宏毅老师关于GAN的中文课程
原文地址:http://www.datalearner.com/blog/1051494816250033
- 生成对抗网络简介(包含TensorFlow代码示例)【翻译】
- 生成对抗网络的简单介绍(TensorFlow 代码)
- 生成对抗网络(GAN)原理+tensorflow代码实现
- 生成对抗网络介绍(附TensorFlow代码)
- 生成对抗网络简介
- 不要怂,就是GAN (生成式对抗网络) (六):Wasserstein GAN(WGAN) TensorFlow 代码
- 生成对抗网络DCGAN+Tensorflow代码学习笔记(一)----main.py
- 生成对抗网络DCGAN+Tensorflow代码学习笔记(二)----utils.py
- 生成对抗网络DCGAN+Tensorflow代码学习笔记(三)----ops.py
- 生成对抗网络的tensorflow实现
- TensorFlow/对抗网络DCGAN生成图片
- GAN生成对抗网络的TensorFlow实现
- 生成对抗网络GAN(一) 简介和变种
- 生成对抗网络GANs理解(附代码)
- 转:生成对抗网络GANs理解(附代码)
- Tensorflow(1.0)基于对抗生成网络生成明星脸
- TensorFlow练习24: GANs-生成对抗网络 (生成明星脸)
- 生成对抗网络(GAN)
- Redis学习之Sentinel原理详解
- 广播监听网络
- Java获取此次请求URL以及服务器根路径的方法
- android 图片大小各不一样大
- SpringMVC数据绑定流程
- 生成对抗网络简介(包含TensorFlow代码示例)【翻译】
- 如何使用PDF编辑软件在PDF文件中添加背景图片
- Android安全攻防战,反编译与混淆技术完全解析(上)
- JVM调优魔法棒-Java VisualVM
- Discuz!论坛发帖自动退出登录状态的解决办法
- xgboost调参
- ROS回顾学习(1)-----catkin_make编译
- Selenium webdriver jar包下载指南
- C++类的实例化对象的大小之sizeof()


