神经网络
来源:互联网 发布:域名贴吧 编辑:程序博客网 时间:2024/06/05 06:06
1 概念
神经网络(neural networks, NN)是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交叉反应。

2 感知机与多层网络
感知机(Perceptron)是由两层神经元组成的,输入层接受外界输入信号后传递给输出层,输出层是M-P神经元,输出,将
也看作一个1的权重,则训练学习可统一为权重的学习。感知机的学习规则很简单,对训练样本
,若当前感知机的输出为
(1)
(2)
为学习率(learning rate)。
感知机只有输出层神经元进行激活函数处理。若两类模式是县新兴可分的,则感知机的学习过程一定会收敛而求得适当的权向量;否则感知机会发生振荡(fluctuation),不能求得权重的合适解。
要解决非线性可分的问题,需要考虑多层功能神经元,输入层与输出层之间的的神经元则成为隐含层(hidden layer),隐含层和输出层都是拥有激活函数的功能神经元。
多层前馈神经网络(multi-layer feedforward neural networks)每层神经元与下一层神经元全互连,神经元之间不存在同层链接,也不存在跨层链接。
神经网络的学习过程就是根据训练数据来调整神经元之间的连接权(connection weight)以及每个功能神经元的阈值。
3 误差逆传播算法
多层网络的学习能力比单层感知机强得多,需要更强大的学习算法,误差逆传播算法(error BackPropagation,BP)算法就是其中最杰出的代表。一般所说的BP网络是指用BP算法训练的多层前反馈神经网络。
此处的神经网络内容出自:http://ufldl.stanford.edu/wiki/index.php/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
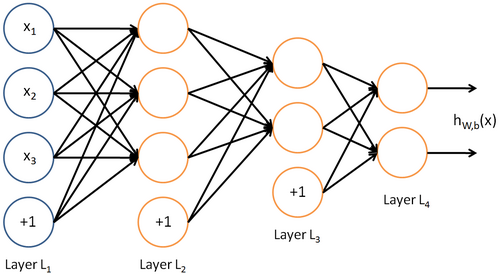
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:
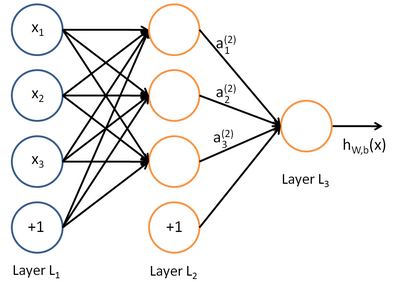
我们使用圆圈来表示神经网络的输入,标上“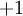 ”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
我们用 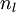 来表示网络的层数,本例中
来表示网络的层数,本例中 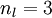 ,我们将第
,我们将第  层记为
层记为 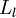 ,于是
,于是 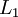 是输入层,输出层是
是输入层,输出层是 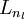 。本例神经网络有参数
。本例神经网络有参数 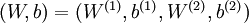 ,其中
,其中 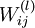 (下面的式子中用到)是第 层第
(下面的式子中用到)是第 层第  单元与第
单元与第 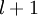 层第
层第  单元之间的联接参数(其实就是连接线上的权重,注意标号顺序),
单元之间的联接参数(其实就是连接线上的权重,注意标号顺序), 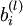 是第 层第 单元的偏置项。因此在本例中,
是第 层第 单元的偏置项。因此在本例中, 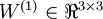 ,
, 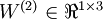 。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用
。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用 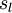 表示第 层的节点数(偏置单元不计在内)。
表示第 层的节点数(偏置单元不计在内)。
我们用 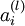 表示第 层第 单元的激活值(输出值)。当
表示第 层第 单元的激活值(输出值)。当 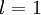 时,
时, 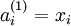 ,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合
,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合 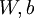 ,我们的神经网络就可以按照函数
,我们的神经网络就可以按照函数 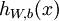 来计算输出结果。本例神经网络的计算步骤如下:
来计算输出结果。本例神经网络的计算步骤如下:
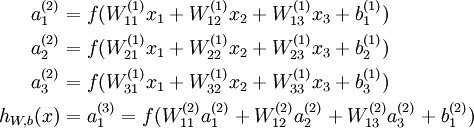
我们用 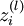 表示第 层第 单元输入加权和(包括偏置单元),比如,
表示第 层第 单元输入加权和(包括偏置单元),比如, 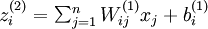 ,则
,则 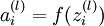 。
。
这样我们就可以得到一种更简洁的表示法。这里我们将激活函数 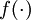 扩展为用向量(分量的形式)来表示,即
扩展为用向量(分量的形式)来表示,即 ![\textstyle f([z_1, z_2, z_3]) = [f(z_1), f(z_2), f(z_3)]](http://ufldl.stanford.edu/wiki/images/math/d/b/8/db84346dcd6187f0fbb0f6c1a72eecf8.png) ,那么,上面的等式可以更简洁地表示为:
,那么,上面的等式可以更简洁地表示为:
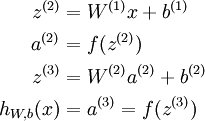
我们将上面的计算步骤叫作前向传播。回想一下,之前我们用 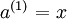 表示输入层的激活值,那么给定第 层的激活值
表示输入层的激活值,那么给定第 层的激活值 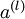 后,第 层的激活值
后,第 层的激活值 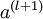 就可以按照下面步骤计算得到:
就可以按照下面步骤计算得到:
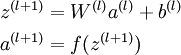
将参数矩阵化,使用矩阵-向量运算方式,我们就可以利用线性代数的优势对神经网络进行快速求解。
目前为止,我们讨论了一种神经网络,我们也可以构建另一种结构的神经网络(这里结构指的是神经元之间的联接模式),也就是包含多个隐藏层的神经网络。最常见的一个例子是 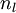 层的神经网络,第
层的神经网络,第 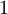 层是输入层,第 层是输出层,中间的每个层 与层 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第
层是输入层,第 层是输出层,中间的每个层 与层 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第 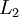 层的所有激活值,然后是第
层的所有激活值,然后是第 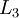 层的激活值,以此类推,直到第 层。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
层的激活值,以此类推,直到第 层。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
神经网络也可以有多个输出单元。比如,下面的神经网络有两层隐藏层: 及 ,输出层 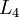 有两个输出单元。
有两个输出单元。
要求解这样的神经网络,需要样本集 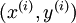 ,其中
,其中 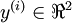 。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值
。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值 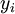 可以表示不同的疾病存在与否。)
可以表示不同的疾病存在与否。)
假设我们有一个固定样本集 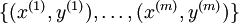 ,它包含
,它包含 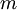 个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例
个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例 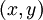 ,其代价函数为:
,其代价函数为:
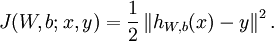
这是一个(二分之一的)方差代价函数。给定一个包含 个样例的数据集,我们可以定义整体代价函数为:
![\begin{align}J(W,b)&= \left[ \frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2 \\&= \left[ \frac{1}{m} \sum_{i=1}^m \left( \frac{1}{2} \left\| h_{W,b}(x^{(i)}) - y^{(i)} \right\|^2 \right) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/5/3/4539f5f00edca977011089b902670513.png)
以上关于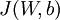 定义中的第一项是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
定义中的第一项是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
[注:通常权重衰减的计算并不使用偏置项 ,比如我们在 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数中计算MAP(极大后验)估计(而不是极大似然估计)。]
权重衰减参数 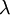 用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义:
用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义: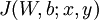 是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
以上的代价函数经常被用于分类和回归问题。在分类问题中,我们用 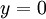 或 ,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为
或 ,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为 ![\textstyle [0,1]](http://ufldl.stanford.edu/wiki/images/math/8/4/2/84235d31ac83fe764546463aba7acc0e.png) ;如果我们使用双曲正切型激活函数,那么应该选用
;如果我们使用双曲正切型激活函数,那么应该选用 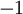 和 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是
和 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是  ),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为
),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为 ![\textstyle [-1,1]](http://ufldl.stanford.edu/wiki/images/math/8/5/a/85a1c5a07f21a9eebbfb1dca380f8d38.png) )。
)。
我们的目标是针对参数 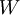 和
和 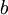 来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布
来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布 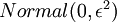 生成的随机值,其中
生成的随机值,其中 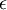 设置为
设置为 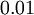 ),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为
),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为 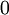 。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有 ,
。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有 ,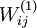 都会取相同的值,那么对于任何输入
都会取相同的值,那么对于任何输入  都会有:
都会有: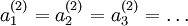 )。随机初始化的目的是使对称失效。
)。随机初始化的目的是使对称失效。
梯度下降法中每一次迭代都按照如下公式对参数 和 进行更新:
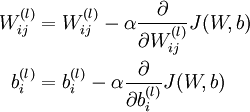
其中 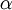 是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
我们首先来讲一下如何使用反向传播算法来计算 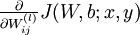 和
和 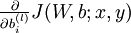 ,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
![\begin{align}\frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) &=\left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b; x^{(i)}, y^{(i)}) \right] + \lambda W_{ij}^{(l)} \\\frac{\partial}{\partial b_{i}^{(l)}} J(W,b) &=\frac{1}{m}\sum_{i=1}^m \frac{\partial}{\partial b_{i}^{(l)}} J(W,b; x^{(i)}, y^{(i)})\end{align}](http://ufldl.stanford.edu/wiki/images/math/9/3/3/93367cceb154c392aa7f3e0f5684a495.png)
以上两行公式稍有不同,第一行比第二行多出一项,是因为权重衰减是作用于 而不是 。
反向传播算法的思路如下:给定一个样例 ,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括 的输出值。之后,针对第 层的每一个节点 ,我们计算出其“残差” 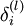 ,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为 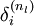 (第 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 层节点)残差的加权平均值计算 ,这些节点以 作为输入。下面将给出反向传导算法的细节:
(第 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 层节点)残差的加权平均值计算 ,这些节点以 作为输入。下面将给出反向传导算法的细节:
- 进行前馈传导计算,利用前向传导公式,得到
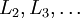 直到输出层 的激活值。
直到输出层 的激活值。 - 对于第 层(输出层)的每个输出单元 ,我们根据以下公式计算残差:
- 对
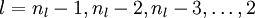 的各个层,第 层的第 个节点的残差计算方法如下:
的各个层,第 层的第 个节点的残差计算方法如下: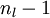 与的关系替换为与的关系,就可以得到:
与的关系替换为与的关系,就可以得到: - 计算我们需要的偏导数,计算方法如下:
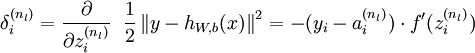
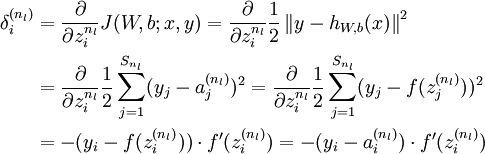
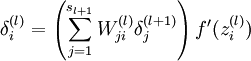
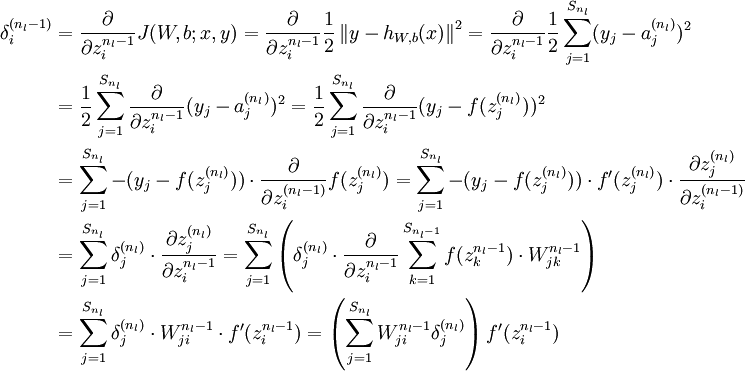
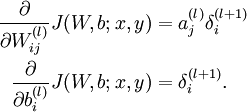
最后,我们用矩阵-向量表示法重写以上算法。我们使用“ ” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若
” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若 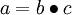 ,则
,则 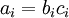 。在上一个教程中我们扩展了 的定义,使其包含向量运算,这里我们也对偏导数
。在上一个教程中我们扩展了 的定义,使其包含向量运算,这里我们也对偏导数 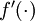 也做了同样的处理(于是又有
也做了同样的处理(于是又有 ![\textstyle f'([z_1, z_2, z_3]) = [f'(z_1), f'(z_2), f'(z_3)]](http://ufldl.stanford.edu/wiki/images/math/c/7/5/c7515c53b59e670ceee277e06c1229cb.png) )。
)。
那么,反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到 直到输出层 的激活值。
- 对输出层(第 层),计算:
- 对于 的各层,计算:
- 计算最终需要的偏导数值:
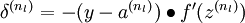
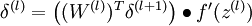
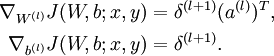
实现中应注意:在以上的第2步和第3步中,我们需要为每一个 值计算其 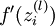 。假设
。假设 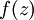 是sigmoid函数,并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的
是sigmoid函数,并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的 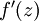 表达式,就可以计算得到
表达式,就可以计算得到 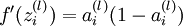 。
。
最后,我们将对梯度下降算法做个全面总结。在下面的伪代码中,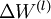 是一个与矩阵
是一个与矩阵 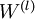 维度相同的矩阵,
维度相同的矩阵,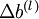 是一个与
是一个与 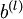 维度相同的向量。注意这里“”是一个矩阵,而不是“
维度相同的向量。注意这里“”是一个矩阵,而不是“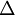 与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
- 对于所有 ,令
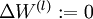 ,
, 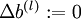 (设置为全零矩阵或全零向量)
(设置为全零矩阵或全零向量) - 对于
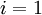 到 ,
到 ,- 使用反向传播算法计算
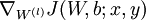 和
和 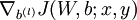 。
。 - 计算
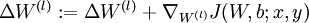 。
。 - 计算
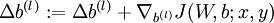 。
。
- 使用反向传播算法计算
- 更新权重参数:
![\begin{align}W^{(l)} &= W^{(l)} - \alpha \left[ \left(\frac{1}{m} \Delta W^{(l)} \right) + \lambda W^{(l)}\right] \\b^{(l)} &= b^{(l)} - \alpha \left[\frac{1}{m} \Delta b^{(l)}\right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/0/f/7/0f7430e97ec4df1bfc56357d1485405f.png)
现在,我们可以重复梯度下降法的迭代步骤来减小代价函数 的值,进而求解我们的神经网络。
有两种策略常用来环境BP网络的过拟合。1)早停(early stopping):将数据分成训练集和验证集,训练集用来计算梯度、更新参数,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的参数。2)正则化(regularization):如上文损失函数中就利用了L2正则化项。
4 全局最小与局部极小
5 其他常见的神经网络
5.1 RBF网络
5.2 ART网络
5.3 SOM网络
5.4 级联相关网络
5.5 Elman网络

5.6 Boltzmann机

6 深度学习
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- 神经网络
- bzoj 1036 树链剖分(剖点)模板题
- 求递推数列通项的特征根法
- 史上最全的机器学习资料(下)
- CodeForces 595C Warrior and Archer(贪心博弈)
- 为什么360浏览器,打开几个页面,然后不对电脑进行任何操作,等过很长时间之后,为什么内存占用会逐渐上升直到崩溃??表现为操作系统卡的不行,做什么都卡
- 神经网络
- ubuntu16.04 安装opencv3
- 欢迎使用CSDN-markdown编辑器
- PCB布线规则图解及PCB布线参考因素解析
- 要不要使用react-native技术--个人的一点看法
- Java安全学习笔记(三)--CBC方式加密
- hdu-6168 Numbers
- android开发之ListView
- Java NIO系列教程(四) Scatter/Gather


