BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树
来源:互联网 发布:linux计划任务每分钟 编辑:程序博客网 时间:2024/06/05 08:16
数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
转载自:
Sup_Heaven:数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树)
辉之光:B树、B-树、B+树、B*树
最后基础知识:CarpenterLee/JCFInternals图画的非常贴切:
BST树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:

BST树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果BST树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变BST树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:

但BST树在经过多次插入与删除后,有可能导致不同的结构:

右边也是一个BST树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用BST树还要考虑尽可能让BST树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
AVL平衡二叉搜索树
定义:平衡二叉树或为空树,或为如下性质的二叉排序树:
(1)左右子树深度之差的绝对值不超过1;
(2)左右子树仍然为平衡二叉树.
平衡因子BF=左子树深度-右子树深度.
平衡二叉树每个结点的平衡因子只能是1,0,-1。若其绝对值超过1,则该二叉排序树就是不平衡的。
如图所示为平衡树和非平衡树示意图:

RBT 红黑树
AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多;
红黑是弱平衡的,用非严格的平衡来换取增删节点时候旋转次数的降低;
所以简单说,搜索的次数远远大于插入和删除,那么选择AVL树,如果搜索,插入删除次数几乎差不多,应该选择RB树。
红黑树上每个结点内含五个域,color,key,left,right,p。如果相应的指针域没有,则设为NIL。
一般的,红黑树,满足以下性质,即只有满足以下全部性质的树,我们才称之为红黑树:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点,即空结点(NIL)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
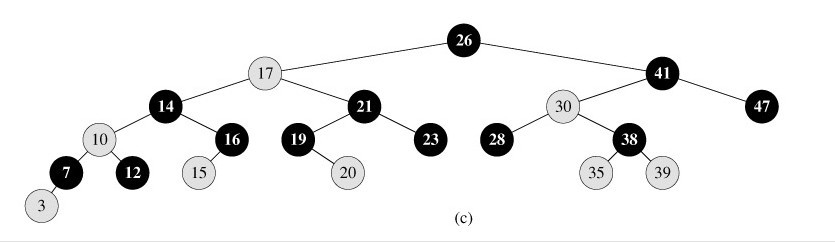
下图所示,即是一颗红黑树:
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
但B树在经过多次插入与删除后,有可能导致不同的结构:
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树
结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的
策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)

B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:

其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)

B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;

B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父
结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字
(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之
间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
基础知识
左旋
左旋的过程是将x的右子树绕x逆时针旋转,使得x的右子树成为x的父亲,同时修改相关节点的引用。旋转之后,二叉查找树的属性仍然满足。

TreeMap中左旋代码如下:
//Rotate Leftprivate void rotateLeft(Entry<K,V> p) { if (p != null) { Entry<K,V> r = p.right; p.right = r.left; if (r.left != null) r.left.parent = p; r.parent = p.parent; if (p.parent == null) root = r; else if (p.parent.left == p) p.parent.left = r; else p.parent.right = r; r.left = p; p.parent = r; }}右旋
右旋的过程是将x的左子树绕x顺时针旋转,使得x的左子树成为x的父亲,同时修改相关节点的引用。旋转之后,二叉查找树的属性仍然满足。

TreeMap中右旋代码如下:
//Rotate Rightprivate void rotateRight(Entry<K,V> p) { if (p != null) { Entry<K,V> l = p.left; p.left = l.right; if (l.right != null) l.right.parent = p; l.parent = p.parent; if (p.parent == null) root = l; else if (p.parent.right == p) p.parent.right = l; else p.parent.left = l; l.right = p; p.parent = l; }}寻找节点后继
对于一棵二叉查找树,给定节点t,其后继(树中比大于t的最小的那个元素)可以通过如下方式找到:
- t的右子树不空,则t的后继是其右子树中最小的那个元素。
- t的右孩子为空,则t的后继是其第一个向左走的祖先。
后继节点在红黑树的删除操作中将会用到。

TreeMap中寻找节点后继的代码如下:
// 寻找节点后继函数successor()static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { if (t == null) return null; else if (t.right != null) {// 1. t的右子树不空,则t的后继是其右子树中最小的那个元素 Entry<K,V> p = t.right; while (p.left != null) p = p.left; return p; } else {// 2. t的右孩子为空,则t的后继是其第一个向左走的祖先 Entry<K,V> p = t.parent; Entry<K,V> ch = t; while (p != null && ch == p.right) { ch = p; p = p.parent; } return p; }}- BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树
- BST二叉查找树、AVL平衡二叉树、RBT红黑树、B-/B+/B*树性能对比
- BST二叉排序树,AVL平衡二叉树,RBT红黑树,B-树,B+树,B*树
- 动态查找树比较: 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)的比较
- 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree)
- [面试]红黑树性质,BST(二叉搜索树)、AVL(平衡二叉搜索树)、RBT(红黑树)、B-Tree(B-树和B+树)
- 数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
- 内存管理(下)
- 高性能的给RecyclerView加上HeaderView和FooterView
- angular框架用于文本框取值
- scrapy模拟表单爬虫
- 接口和抽象类的区别
- BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树
- Eclipse Color Themes 设置
- Source Insight工程,相对路径配置
- CODE[VS]1008 选数
- 一些伪类:after和:before的用法
- 前段BUG
- jmeter 安装插件管理
- Auto-Encoding Variational Bayes
- Material Design你真的了解吗?


