647. Palindromic Substrings 回文子串
来源:互联网 发布:知乎经典回复 编辑:程序博客网 时间:2024/06/05 10:31
Given a string, your task is to count how many palindromic substrings in this string.
The substrings with different start indexes or end indexes are counted as different substrings even they consist of same characters.
给定一字符串,统计其含有的回文子串的数量。
Example 1:
Input: "abc"Output: 3Explanation: Three palindromic strings: "a", "b", "c".Example 2:
Input: "aaa"Output: 6Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".Note:
- The input string length won't exceed 1000.
思路
【回文中心法】
定义当前扫描点i为扫描的回文中心,向两端发散扫描并统计有效的回文串个数。
此种从中间到两边的扫描判定避免了将aaa、aba、区别对待的情形,但是要注意考虑回文串长度为奇数(aaa)和偶数(aaaa)的情况。
时间复杂度O(n^2)。
public class Solution {
int count = 0;
public int countSubstrings(String s) {
if (s == null || s.length() == 0) return 0;
for (int i = 0; i < s.length(); i++) { // i is the mid point
extendPalindrome(s, i, i); // odd length;
extendPalindrome(s, i, i + 1); // even length
}
return count;
}
private void extendPalindrome(String s, int left, int right) {
while (left >=0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
count++; left--; right++;
}
}
}
int count = 0;
public int countSubstrings(String s) {
if (s == null || s.length() == 0) return 0;
for (int i = 0; i < s.length(); i++) { // i is the mid point
extendPalindrome(s, i, i); // odd length;
extendPalindrome(s, i, i + 1); // even length
}
return count;
}
private void extendPalindrome(String s, int left, int right) {
while (left >=0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
count++; left--; right++;
}
}
}
class Solution(object):
def countSubstrings(self, s):
"""
:type s: str
:rtype: int
"""
n=len(s)
ans=0
for center in xrange(2*n-1):
left=center/2
right=left+(center%2)
while left>=0 and right<n and s[left]==s[right]:
ans+=1
left-=1
right+=1
return ans
【Manacher's Algorithm 马拉车算法】
时间复杂度O(n).
由于回文串的长度可奇可偶,比如"bob"是奇数形式的回文,"noon"就是偶数形式的回文,马拉车算法的第一步是预处理,做法是在每一个字符的左右都加上一个特殊字符,比如加上'#',那么
bob --> #b#o#b#
noon --> #n#o#o#n#
这样做的好处是不论原字符串是奇数还是偶数个,处理之后得到的字符串的个数都是奇数个,这样就不用分情况讨论了,而可以一起搞定。接下来我们还需要和处理后的字符串t等长的数组p,其中p[i]表示以t[i]字符为中心的回文子串的半径,若p[i] = 1,则该回文子串就是t[i]本身,那么我们来看一个简单的例子:
# 1 # 2 # 2 # 1 # 2 # 2 #
1 2 1 2 5 2 1 6 1 2 3 2 1
由于第一个和最后一个字符都是#号,且也需要搜索回文,为了防止越界,我们还需要在首尾再加上非#号字符,实际操作时我们只需给开头加上个非#号字符,结尾不用加的原因是字符串的结尾标识为'\0',等于默认加过了。通过p数组我们就可以找到其最大值和其位置,就能确定最长回文子串了,那么下面我们就来看如何求p数组,需要新增两个辅助变量mx和id,其中id为最大回文子串中心的位置,mx是回文串能延伸到的最右端的位置,这个算法的最核心的一行如下:
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
可以这么说,这行要是理解了,那么马拉车算法基本上就没啥问题了,那么这一行代码拆开来看就是
如果mx > i, 则 p[i] = min(p[2 * id - i], mx - i)
否则, p[i] = 1
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
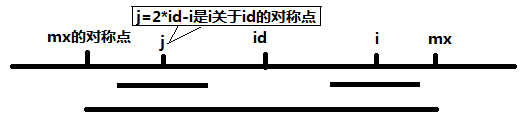
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
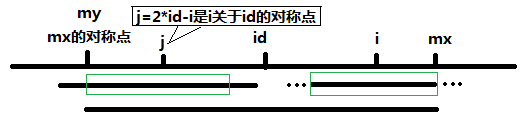
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
阅读全文
0 0
- 647. Palindromic Substrings 回文子串
- Leetcode 647. Palindromic Substrings 回文子串 解题报告
- LeetCode 647. Palindromic Substrings--回文子串个数
- leetcode 647. Palindromic Substrings 回文子串的数量
- 647. Palindromic Substrings(回文子字符串)
- 647. Palindromic Substrings
- 647. Palindromic Substrings
- [leetcode]647. Palindromic Substrings
- leetcode 647. Palindromic Substrings
- [LeetCode]647. Palindromic Substrings
- leetcode 647. Palindromic Substrings
- [LeetCode] 647. Palindromic Substrings
- 647. Palindromic Substrings
- 【LeetCode】647. Palindromic Substrings
- 647. Palindromic Substrings
- 647. Palindromic Substrings
- Leetcode 647. Palindromic Substrings
- 647. Palindromic Substrings
- 关于IDEA idea .java文件 右下角有个红色j,解决方法
- Android使用Gson解析JSON数据
- java 判断日期是否是节假日
- 自勉
- python 连接数据库执行sql 查询
- 647. Palindromic Substrings 回文子串
- 在python上操作MySQL数据库
- 自定义ToolBar
- Leetcode 415. Add Strings
- 初始化与清理
- Git本地项目添加到远程代码库
- Parameter 'offset' not found. Available parameters are [arg1, arg0, param1, param2]
- html id 选择器和 class 选择器
- 30 多年的软件经验,总结出 10 个编写出更好代码的技巧


