CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
来源:互联网 发布:音乐剪辑合成软件 编辑:程序博客网 时间:2024/05/24 04:49
一、深度学习:
深度学习是机器学习的一个分支。可以理解为具有多层结构的模型。
二、基本模型:
给大家总结一下深度学习里面的基本模型。我将这些模型大致分为了这几类:多层感知机模型;深度神经网络模型和递归神经网络模型。
2.1 多层感知机模型(也就是你这里说的深度神经网络):
2.1.1 Stacked Auto-Encoder堆叠自编码器
堆叠自编码器是一种最基础的深度学习模型,该模型的子网络结构自编码器通过假设输出与输入是相同的来训练调整网络参数,得到每一层中的权重。通过堆叠多层自编码网络可以得到输入信号的几种不同表征(每一层代表一种表征),这些表征就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
2.1.1.1 网络结构
堆叠自编码器的网络结构本质上就是一种普通的多层神经网络结构。
<img src="https://pic4.zhimg.com/v2-c36b05047f69408d5cd15f8eaaf4e73f_b.png" data-rawwidth="600" data-rawheight="351" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/v2-c36b05047f69408d5cd15f8eaaf4e73f_r.png">
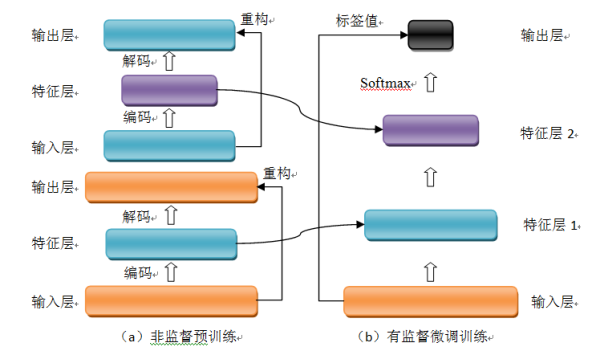
图1 自编码器网络结构
2.1.1.2 训练过程
堆叠自编码器与普通神经网络不同之处在于其训练过程,该网络结构训练主要分两步:非监督预训练和有监督微调训练。
(1)非监督预训练
自编码器通过自学习得到原始数据的压缩和分布式表征,一般用于高层特征提取与数据非线性降维。结构上类似于一个典型的三层BP神经网络,由一个输入层,一个中间隐含层和一个输出层构成。但是,输出层与输入层的神经元个数相等,且训练样本集合的标签值为输入值,即无标签值。输入层到隐含层之间的映射称为编码(Encoder),隐含层到输出层之间的映射称为解码(Decoder)。非监督预训练自编码器的中间层为特征层,在训练好第一层特征层后,第二层和第一层的训练方式相同。我们将第一层输出的特征层当成第二层的输入层,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的特征层,也就是原输入信息的第二个表征。以此类推可以训练其他特征层。
(3)有监督微调训练
经过上面的训练方法,可以得到一个多层的堆叠自编码器,每一层都会得到原始输入的不同的表达。到这里,这个堆叠自编码器还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如逻辑斯蒂回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)微调训练。
2.1.1.3 典型改进
(1)Sparse AutoEncoder稀疏自编码器
在AutoEncoder的基础上加上L1的稀疏限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源)来减小过拟合的影响,我们就可以得到稀疏自编码器。
(2)Denoising AutoEncoders降噪自编码器
降噪自动编码器是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入。因此,这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。
2.1.1.4 模型优缺点
(1)优点:
(1)、可以利用足够多的无标签数据进行模型预训练;
(2)、具有较强的数据表征能力。
(2)缺点:
(1)、因为是全连接网络,需要训练的参数较多,容易出现过拟合;深度模型容易出现梯度消散问题。
(2)、要求输入数据具有平移不变性。
2.1.2、Deep belief network 深度信念网络
2006年,Geoffrey Hinton提出深度信念网络(DBN)及其高效的学习算法,即Pre-training+Fine tuning,并发表于《Science》上,成为其后深度学习算法的主要框架。DBN是一种生成模型,通过训练其神经元间的权重,我们可以让整个神经网络按照最大概率来生成训练数据。所以,我们不仅可以使用DBN识别特征、分类数据,还可以用它来生成数据。
2.1.2.1 网络结构
深度信念网络(DBN)由若干层受限玻尔兹曼机(RBM)堆叠而成,上一层RBM的隐层作为下一层RBM的可见层。下面先介绍RBM,再介绍DBN。
(1) RBM
<img src="https://pic2.zhimg.com/v2-2e5cabab33abf12d617b9748739193c9_b.png" data-rawwidth="463" data-rawheight="226" class="origin_image zh-lightbox-thumb" width="463" data-original="https://pic2.zhimg.com/v2-2e5cabab33abf12d617b9748739193c9_r.png">
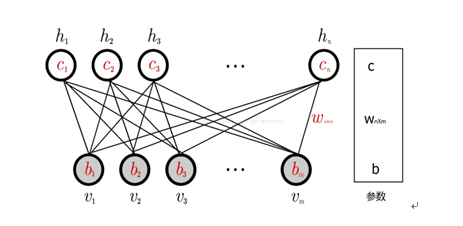
图2 RBM网络结构
一个普通的RBM网络结构如上图所示,是一个双层模型,由m个可见层单元及n个隐层单元组成,其中,层内神经元无连接,层间神经元全连接,也就是说:在给定可见层状态时,隐层的激活状态条件独立,反之,当给定隐层状态时,可见层的激活状态条件独立。这保证了层内神经元之间的条件独立性,降低概率分布计算及训练的复杂度。RBM可以被视为一个无向图模型,可见层神经元与隐层神经元之间的连接权重是双向的,即可见层到隐层的连接权重为W,则隐层到可见层的连接权重为W’。除以上提及的参数外,RBM的参数还包括可见层偏置b及隐层偏置c。
RBM可见层和隐层单元所定义的分布可根据实际需要更换,包括:Binary单元、Gaussian单元、Rectified Linear单元等,这些不同单元的主要区别在于其激活函数不同。
(2) DBN
<img src="https://pic3.zhimg.com/v2-7c1aab1d67c923094a02001c835d6b7e_b.png" data-rawwidth="415" data-rawheight="287" class="content_image" width="415">
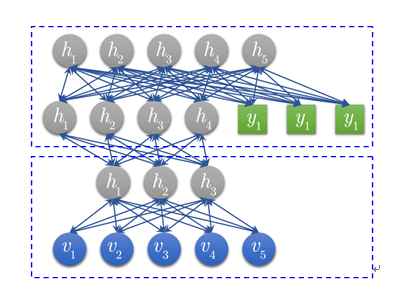
图3 DBN模型结构
DBN模型由若干层RBM堆叠而成,如果在训练集中有标签数据,那么最后一层RBM的可见层中既包含前一层RBM的隐层单元,也包含标签层单元。假设顶层RBM的可见层有500个神经元,训练数据的分类一共分成了10类,那么顶层RBM的可见层有510个显性神经元,对每一训练数据,相应的标签神经元被打开设为1,而其他的则被关闭设为0。
2.1.2.2 训练过程
DBN的训练包括Pre-training和Fine tuning两步,其中Pre-training过程相当于逐层训练每一个RBM,经过Pre-training的DBN已经可用于模拟训练数据,而为了进一步提高网络的判别性能, Fine tuning过程利用标签数据通过BP算法对网络参数进行微调。
(1) Pre-training
如前面所说,DBN的Pre-training过程相当于逐层训练每一个RBM,因此进行Pre-training时直接使用RBM的训练算法。
(2) Fine tuning
建立一个与DBN相同层数的神经网络,将Pre-training过程获得的网络参数赋给此神经网络,作为其参数的初始值,然后在最后一层后添加标签层,结合训练数据标签,利用BP算法微调整个网络参数,完成Fine tuning过程。
2.1.2.3 改进模型
DBN的变体比较多,它的改进主要集中于其组成“零件”RBM的改进,下面列举两种主要的变体。(这边的改进模型暂时没有深入研究,所以大概参考网上的内容)
(1) 卷积DBN(CDBN)
DBN并没有考虑到图像的二维结构信息,因为输入是简单的将一个图像矩阵转换为一维向量。而CDBN利用邻域像素的空域关系,通过一个称为卷积RBM(CRBM)的模型达到生成模型的变换不变性,而且可以容易得变换到高维图像。
(2) 条件RBM(Conditional RBM)
DBN并没有明确地处理对观察变量的时间联系的学习上,Conditional RBM通过考虑前一时刻的可见层单元变量作为附加的条件输入,以模拟序列数据,这种变体在语音信号处理领域应用较多。
2.1.2.4 典型优缺点
对DBN优缺点的总结主要集中在生成模型与判别模型的优缺点总结上。
(1)优点:
(1)、生成模型学习联合概率密度分布,所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度;
(2)、生成模型可以还原出条件概率分布,此时相当于判别模型,而判别模型无法得到联合分布,所以不能当成生成模型使用。
(2)缺点:
(1)、 生成模型不关心不同类别之间的最优分类面到底在哪儿,所以用于分类问题时,分类精度可能没有判别模型高;
(2)、由于生成模型学习的是数据的联合分布,因此在某种程度上学习问题的复杂性更高。
(3)、要求输入数据具有平移不变性。
2.2、Convolution Neural Networks卷积神经网络
卷积神经网络是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。
2.2.1 网络结构
卷积神经网络是一个多层的神经网络,其基本运算单元包括:卷积运算、池化运算、全连接运算和识别运算。
<img src="https://pic2.zhimg.com/v2-0f4e8cd3a940c0e3eed74b8e8d86c641_b.png" data-rawwidth="600" data-rawheight="224" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/v2-0f4e8cd3a940c0e3eed74b8e8d86c641_r.png">
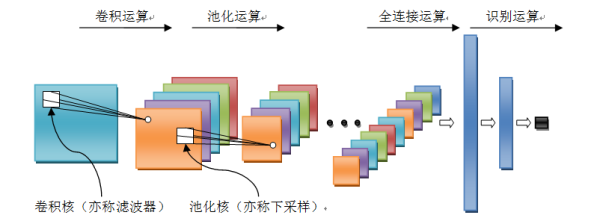
图4 卷积神经网络结构
l 卷积运算:前一层的特征图与一个可学习的卷积核进行卷积运算,卷积的结果经过激活函数后的输出形成这一层的神经元,从而构成该层特征图,也称特征提取层,每个神经元的输入与前一层的局部感受野相连接,并提取该局部的特征,一旦该局部特征被提取,它与其它特征之间的位置关系就被确定。
l 池化运算:它把输入信号分割成不重叠的区域,对于每个区域通过池化(下采样)运算来降低网络的空间分辨率,比如最大值池化是选择区域内的最大值,均值池化是计算区域内的平均值。通过该运算来消除信号的偏移和扭曲。
l 全连接运算:输入信号经过多次卷积核池化运算后,输出为多组信号,经过全连接运算,将多组信号依次组合为一组信号。
l 识别运算:上述运算过程为特征学习运算,需在上述运算基础上根据业务需求(分类或回归问题)增加一层网络用于分类或回归计算。
2.2.2 训练过程
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。卷积网络执行的是有监督训练,所以其样本集是由形如:(输入信号,标签值)的向量对构成的。
2.2.3 典型改进
卷积神经网络因为其在各个领域中取得了好的效果,是近几年来研究和应用最为广泛的深度神经网络。比较有名的卷积神经网络模型主要包括1986年Lenet,2012年的Alexnet,2014年的GoogleNet,2014年的VGG,2015年的Deep Residual Learning。这些卷积神经网络的改进版本或者模型的深度,或者模型的组织结构有一定的差异,但是组成模型的机构构建是相同的,基本都包含了卷积运算、池化运算、全连接运算和识别运算。
2.2.4 模型优缺点
(1)优点:
(1)、权重共享策略减少了需要训练的参数,相同的权重可以让滤波器不受信号位置的影响来检测信号的特性,使得训练出来的模型的泛化能力更强;
(2)、池化运算可以降低网络的空间分辨率,从而消除信号的微小偏移和扭曲,从而对输入数据的平移不变性要求不高。
(2)缺点:
(1)、深度模型容易出现梯度消散问题。
2.3、Recurrent neural network 递归神经网络
在深度学习领域,传统的多层感知机为基础的上述各网络结构具有出色的表现,取得了许多成功,它曾在许多不同的任务上——包括手写数字识别和目标分类上创造了记录。但是,他们也存在一定的问题,上述模型都无法分析输入信息之间的整体逻辑序列。这些信息序列富含有大量的内容,信息彼此间有着复杂的时间关联性,并且信息长度各种各样。这是以上模型所无法解决的,递归神经网络正是为了解决这种序列问题应运而生,其关键之处在于当前网络的隐藏状态会保留先前的输入信息,用来作当前网络的输出。
许多任务需要处理序列数据,比如Image captioning, speech synthesis, and music generation 均需要模型生成序列数据,其他领域比如 time series prediction, video analysis, and musical information retrieval 等要求模型的输入为序列数据,其他任务比如机器翻译,人机对话,controlling a robot 的模型要求输入输出均为序列数据。
2.3.1 网络结构
图4.1左侧是递归神经网络的原始结构,如果先抛弃中间那个令人生畏的闭环,那其实就是简单“输入层=>隐藏层=>输出层”的三层结构,但是图中多了一个非常陌生的闭环,也就是说输入到隐藏层之后,隐藏层还会输入给自己,使得该网络可以拥有记忆能力。我们说递归神经网络拥有记忆能力,而这种能力就是通过W将以往的输入状态进行总结,而作为下次输入的辅助。可以这样理解隐藏状态:
h=f(现有的输入+过去记忆总结)
<img src="https://pic3.zhimg.com/v2-44bb5831d640667e7d306574d95a96fe_b.png" data-rawwidth="529" data-rawheight="258" class="origin_image zh-lightbox-thumb" width="529" data-original="https://pic3.zhimg.com/v2-44bb5831d640667e7d306574d95a96fe_r.png">
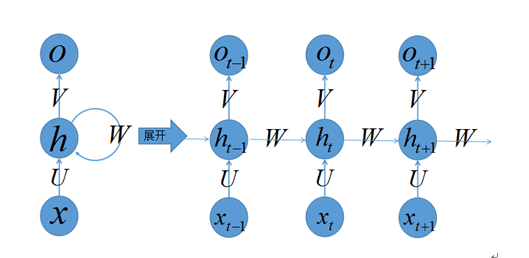
图5 递归神经网络结构图
2.3.2 训练过程
递归神经网络中由于输入时叠加了之前的信号,所以反向传导时不同于传统的神经网络,因为对于时刻t的输入层,其残差不仅来自于输出,还来自于之后的隐层。通过反向传递算法,利用输出层的误差,求解各个权重的梯度,然后利用梯度下降法更新各个权重。
2.3.3 典型改进
递归神经网络模型可以用来处理序列数据,递归神经网络包含了大量参数,且难于训练(时间维度的梯度消散或梯度爆炸),所以出现一系列对RNN优化,比如网络结构、求解算法与并行化。今年来bidirectional RNN (BRNN)与 LSTM在image captioning, language translation, and handwriting recognition这几个方向上有了突破性进展 。
2.3.4 模型优缺点
(1)优点:
(1)、模型是时间维度上的深度模型,可以对序列内容建模;
(2)缺点:
(1)、需要训练的参数较多,容易出现梯度消散或梯度爆炸问题;
(2)、不具有特征学习能力。
一、深度学习:
深度学习是机器学习的一个分支。可以理解为具有多层结构的模型。
二、基本模型:
给大家总结一下深度学习里面的基本模型。我将这些模型大致分为了这几类:多层感知机模型;深度神经网络模型和递归神经网络模型。
2.1 多层感知机模型(也就是你这里说的深度神经网络):
2.1.1 Stacked Auto-Encoder堆叠自编码器
堆叠自编码器是一种最基础的深度学习模型,该模型的子网络结构自编码器通过假设输出与输入是相同的来训练调整网络参数,得到每一层中的权重。通过堆叠多层自编码网络可以得到输入信号的几种不同表征(每一层代表一种表征),这些表征就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
2.1.1.1 网络结构
堆叠自编码器的网络结构本质上就是一种普通的多层神经网络结构。
<img src="https://pic4.zhimg.com/v2-c36b05047f69408d5cd15f8eaaf4e73f_b.png" data-rawwidth="600" data-rawheight="351" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/v2-c36b05047f69408d5cd15f8eaaf4e73f_r.png">
图1 自编码器网络结构
2.1.1.2 训练过程
堆叠自编码器与普通神经网络不同之处在于其训练过程,该网络结构训练主要分两步:非监督预训练和有监督微调训练。
(1)非监督预训练
自编码器通过自学习得到原始数据的压缩和分布式表征,一般用于高层特征提取与数据非线性降维。结构上类似于一个典型的三层BP神经网络,由一个输入层,一个中间隐含层和一个输出层构成。但是,输出层与输入层的神经元个数相等,且训练样本集合的标签值为输入值,即无标签值。输入层到隐含层之间的映射称为编码(Encoder),隐含层到输出层之间的映射称为解码(Decoder)。非监督预训练自编码器的中间层为特征层,在训练好第一层特征层后,第二层和第一层的训练方式相同。我们将第一层输出的特征层当成第二层的输入层,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的特征层,也就是原输入信息的第二个表征。以此类推可以训练其他特征层。
(3)有监督微调训练
经过上面的训练方法,可以得到一个多层的堆叠自编码器,每一层都会得到原始输入的不同的表达。到这里,这个堆叠自编码器还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如逻辑斯蒂回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)微调训练。
2.1.1.3 典型改进
(1)Sparse AutoEncoder稀疏自编码器
在AutoEncoder的基础上加上L1的稀疏限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源)来减小过拟合的影响,我们就可以得到稀疏自编码器。
(2)Denoising AutoEncoders降噪自编码器
降噪自动编码器是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入。因此,这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。
2.1.1.4 模型优缺点
(1)优点:
(1)、可以利用足够多的无标签数据进行模型预训练;
(2)、具有较强的数据表征能力。
(2)缺点:
(1)、因为是全连接网络,需要训练的参数较多,容易出现过拟合;深度模型容易出现梯度消散问题。
(2)、要求输入数据具有平移不变性。
2.1.2、Deep belief network 深度信念网络
2006年,Geoffrey Hinton提出深度信念网络(DBN)及其高效的学习算法,即Pre-training+Fine tuning,并发表于《Science》上,成为其后深度学习算法的主要框架。DBN是一种生成模型,通过训练其神经元间的权重,我们可以让整个神经网络按照最大概率来生成训练数据。所以,我们不仅可以使用DBN识别特征、分类数据,还可以用它来生成数据。
2.1.2.1 网络结构
深度信念网络(DBN)由若干层受限玻尔兹曼机(RBM)堆叠而成,上一层RBM的隐层作为下一层RBM的可见层。下面先介绍RBM,再介绍DBN。
(1) RBM
<img src="https://pic2.zhimg.com/v2-2e5cabab33abf12d617b9748739193c9_b.png" data-rawwidth="463" data-rawheight="226" class="origin_image zh-lightbox-thumb" width="463" data-original="https://pic2.zhimg.com/v2-2e5cabab33abf12d617b9748739193c9_r.png">
图2 RBM网络结构
一个普通的RBM网络结构如上图所示,是一个双层模型,由m个可见层单元及n个隐层单元组成,其中,层内神经元无连接,层间神经元全连接,也就是说:在给定可见层状态时,隐层的激活状态条件独立,反之,当给定隐层状态时,可见层的激活状态条件独立。这保证了层内神经元之间的条件独立性,降低概率分布计算及训练的复杂度。RBM可以被视为一个无向图模型,可见层神经元与隐层神经元之间的连接权重是双向的,即可见层到隐层的连接权重为W,则隐层到可见层的连接权重为W’。除以上提及的参数外,RBM的参数还包括可见层偏置b及隐层偏置c。
RBM可见层和隐层单元所定义的分布可根据实际需要更换,包括:Binary单元、Gaussian单元、Rectified Linear单元等,这些不同单元的主要区别在于其激活函数不同。
(2) DBN
<img src="https://pic3.zhimg.com/v2-7c1aab1d67c923094a02001c835d6b7e_b.png" data-rawwidth="415" data-rawheight="287" class="content_image" width="415">
图3 DBN模型结构
DBN模型由若干层RBM堆叠而成,如果在训练集中有标签数据,那么最后一层RBM的可见层中既包含前一层RBM的隐层单元,也包含标签层单元。假设顶层RBM的可见层有500个神经元,训练数据的分类一共分成了10类,那么顶层RBM的可见层有510个显性神经元,对每一训练数据,相应的标签神经元被打开设为1,而其他的则被关闭设为0。
2.1.2.2 训练过程
DBN的训练包括Pre-training和Fine tuning两步,其中Pre-training过程相当于逐层训练每一个RBM,经过Pre-training的DBN已经可用于模拟训练数据,而为了进一步提高网络的判别性能, Fine tuning过程利用标签数据通过BP算法对网络参数进行微调。
(1) Pre-training
如前面所说,DBN的Pre-training过程相当于逐层训练每一个RBM,因此进行Pre-training时直接使用RBM的训练算法。
(2) Fine tuning
建立一个与DBN相同层数的神经网络,将Pre-training过程获得的网络参数赋给此神经网络,作为其参数的初始值,然后在最后一层后添加标签层,结合训练数据标签,利用BP算法微调整个网络参数,完成Fine tuning过程。
2.1.2.3 改进模型
DBN的变体比较多,它的改进主要集中于其组成“零件”RBM的改进,下面列举两种主要的变体。(这边的改进模型暂时没有深入研究,所以大概参考网上的内容)
(1) 卷积DBN(CDBN)
DBN并没有考虑到图像的二维结构信息,因为输入是简单的将一个图像矩阵转换为一维向量。而CDBN利用邻域像素的空域关系,通过一个称为卷积RBM(CRBM)的模型达到生成模型的变换不变性,而且可以容易得变换到高维图像。
(2) 条件RBM(Conditional RBM)
DBN并没有明确地处理对观察变量的时间联系的学习上,Conditional RBM通过考虑前一时刻的可见层单元变量作为附加的条件输入,以模拟序列数据,这种变体在语音信号处理领域应用较多。
2.1.2.4 典型优缺点
对DBN优缺点的总结主要集中在生成模型与判别模型的优缺点总结上。
(1)优点:
(1)、生成模型学习联合概率密度分布,所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度;
(2)、生成模型可以还原出条件概率分布,此时相当于判别模型,而判别模型无法得到联合分布,所以不能当成生成模型使用。
(2)缺点:
(1)、 生成模型不关心不同类别之间的最优分类面到底在哪儿,所以用于分类问题时,分类精度可能没有判别模型高;
(2)、由于生成模型学习的是数据的联合分布,因此在某种程度上学习问题的复杂性更高。
(3)、要求输入数据具有平移不变性。
2.2、Convolution Neural Networks卷积神经网络
卷积神经网络是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。
2.2.1 网络结构
卷积神经网络是一个多层的神经网络,其基本运算单元包括:卷积运算、池化运算、全连接运算和识别运算。
<img src="https://pic2.zhimg.com/v2-0f4e8cd3a940c0e3eed74b8e8d86c641_b.png" data-rawwidth="600" data-rawheight="224" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/v2-0f4e8cd3a940c0e3eed74b8e8d86c641_r.png">
图4 卷积神经网络结构
l 卷积运算:前一层的特征图与一个可学习的卷积核进行卷积运算,卷积的结果经过激活函数后的输出形成这一层的神经元,从而构成该层特征图,也称特征提取层,每个神经元的输入与前一层的局部感受野相连接,并提取该局部的特征,一旦该局部特征被提取,它与其它特征之间的位置关系就被确定。
l 池化运算:它把输入信号分割成不重叠的区域,对于每个区域通过池化(下采样)运算来降低网络的空间分辨率,比如最大值池化是选择区域内的最大值,均值池化是计算区域内的平均值。通过该运算来消除信号的偏移和扭曲。
l 全连接运算:输入信号经过多次卷积核池化运算后,输出为多组信号,经过全连接运算,将多组信号依次组合为一组信号。
l 识别运算:上述运算过程为特征学习运算,需在上述运算基础上根据业务需求(分类或回归问题)增加一层网络用于分类或回归计算。
2.2.2 训练过程
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。卷积网络执行的是有监督训练,所以其样本集是由形如:(输入信号,标签值)的向量对构成的。
2.2.3 典型改进
卷积神经网络因为其在各个领域中取得了好的效果,是近几年来研究和应用最为广泛的深度神经网络。比较有名的卷积神经网络模型主要包括1986年Lenet,2012年的Alexnet,2014年的GoogleNet,2014年的VGG,2015年的Deep Residual Learning。这些卷积神经网络的改进版本或者模型的深度,或者模型的组织结构有一定的差异,但是组成模型的机构构建是相同的,基本都包含了卷积运算、池化运算、全连接运算和识别运算。
2.2.4 模型优缺点
(1)优点:
(1)、权重共享策略减少了需要训练的参数,相同的权重可以让滤波器不受信号位置的影响来检测信号的特性,使得训练出来的模型的泛化能力更强;
(2)、池化运算可以降低网络的空间分辨率,从而消除信号的微小偏移和扭曲,从而对输入数据的平移不变性要求不高。
(2)缺点:
(1)、深度模型容易出现梯度消散问题。
2.3、Recurrent neural network 递归神经网络
在深度学习领域,传统的多层感知机为基础的上述各网络结构具有出色的表现,取得了许多成功,它曾在许多不同的任务上——包括手写数字识别和目标分类上创造了记录。但是,他们也存在一定的问题,上述模型都无法分析输入信息之间的整体逻辑序列。这些信息序列富含有大量的内容,信息彼此间有着复杂的时间关联性,并且信息长度各种各样。这是以上模型所无法解决的,递归神经网络正是为了解决这种序列问题应运而生,其关键之处在于当前网络的隐藏状态会保留先前的输入信息,用来作当前网络的输出。
许多任务需要处理序列数据,比如Image captioning, speech synthesis, and music generation 均需要模型生成序列数据,其他领域比如 time series prediction, video analysis, and musical information retrieval 等要求模型的输入为序列数据,其他任务比如机器翻译,人机对话,controlling a robot 的模型要求输入输出均为序列数据。
2.3.1 网络结构
图4.1左侧是递归神经网络的原始结构,如果先抛弃中间那个令人生畏的闭环,那其实就是简单“输入层=>隐藏层=>输出层”的三层结构,但是图中多了一个非常陌生的闭环,也就是说输入到隐藏层之后,隐藏层还会输入给自己,使得该网络可以拥有记忆能力。我们说递归神经网络拥有记忆能力,而这种能力就是通过W将以往的输入状态进行总结,而作为下次输入的辅助。可以这样理解隐藏状态:
h=f(现有的输入+过去记忆总结)
<img src="https://pic3.zhimg.com/v2-44bb5831d640667e7d306574d95a96fe_b.png" data-rawwidth="529" data-rawheight="258" class="origin_image zh-lightbox-thumb" width="529" data-original="https://pic3.zhimg.com/v2-44bb5831d640667e7d306574d95a96fe_r.png">
图5 递归神经网络结构图
2.3.2 训练过程
递归神经网络中由于输入时叠加了之前的信号,所以反向传导时不同于传统的神经网络,因为对于时刻t的输入层,其残差不仅来自于输出,还来自于之后的隐层。通过反向传递算法,利用输出层的误差,求解各个权重的梯度,然后利用梯度下降法更新各个权重。
2.3.3 典型改进
递归神经网络模型可以用来处理序列数据,递归神经网络包含了大量参数,且难于训练(时间维度的梯度消散或梯度爆炸),所以出现一系列对RNN优化,比如网络结构、求解算法与并行化。今年来bidirectional RNN (BRNN)与 LSTM在image captioning, language translation, and handwriting recognition这几个方向上有了突破性进展 。
2.3.4 模型优缺点
(1)优点:
(1)、模型是时间维度上的深度模型,可以对序列内容建模;
(2)缺点:
(1)、需要训练的参数较多,容易出现梯度消散或梯度爆炸问题;
(2)、不具有特征学习能力。
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?(知呼回答)
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构的区别
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构的区别
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构区别
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的区别
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)介绍
- python的retrying模块
- Spring简介
- 29 Three.js的特殊光源THREE.RectAreaLight窗口射入光线模拟
- NYOJ题目18-The Triangle(经典dp)
- 51nod 1280 前缀后缀集合(set)
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
- Codeforces 842C
- 【半年总结】——化繁为简
- Linux下安装Mysql(yum指令)
- Python实现设计模式--07.原型模式(Prototype Pattern)
- CSS总结——2
- 【HTML5学习笔记】28:CSS3文本效果
- js获取本月开始时间和结束时间
- zoj2318 getout(计算几何)


