AlphaGo的原理
来源:互联网 发布:java web 异常类型 编辑:程序博客网 时间:2024/05/21 06:35
1. foreword
开宗明义。
阿尔法狗原理:深度学习网络 + 蒙特卡罗搜索树
没看论文,直接看别人的讲解,容易遇到很多生词。前后翻了好几篇博客,对比着来看,方才大略知道怎么回事。
2. 蒙特卡罗方法
2.1 蒙特卡罗随机算法
在《西瓜书》特征选择一节,有随机选择特征子集的步骤。周老师说:拉斯维加斯方法和蒙特卡罗方法是两个著名的随机化方法。这俩方法并不是某个具体的方法,而是代表两类随机算法的思想。
蒙特卡罗方法:采样的次数足够多,则越接近于最优解。强调每一步迭代都是当前的最优解。比如1筐苹果要找到最大的,先随机拿出第一个,再随机拿出一个比较,如果比第一个大,则留下,比第一个小则舍弃。每次留下的苹果的大小起码不低于上次的。只要次数足够多,就可以找到最大的。当然次数有限,找的也是次大的。即尽量找最好的,但不保证是最好的。
拉斯维加斯方法:采样的次数足够多,则越有可能找到最优解。强调直接得到最优解。比如有1扇门,100把钥匙,其中只有1把可以打开。每次随机拿出一把开门,开了就找到了,不开则舍弃再随机挑选一把。只要次数足够多,则一定可以找到最优解。
二者区别:有限采样内,拉斯维加斯或者给出最优解,或者不给出解。蒙特卡罗一定会给出解,但不一定是最优解。若无时间限制,则两者都可以给出最优解。
算法名字带有蒙特卡洛的意思在于:其对搜索空间的搜索都是随机给一个方向的。开个玩笑:开头就说了,蒙(特卡洛树)算法主要靠蒙。主要是在随机采样上计算得到近似结果,随着采样的增多,得到的结果是正确结果的概率逐渐加大。
2.2 蒙特卡罗树搜索(MCTS)
阿尔法狗中,蒙特卡罗树搜索主要是用来快速评估棋面位置价值的。
Monte Carlo methods are ways of solving the reinforcement learning problem based on averaging sample returns。
下棋其实就是一个马尔科夫决策过程(MDP):根据当前棋面状态,确定下一步动作。
该下哪步才能保证后续赢棋的概率比较大呢?最直观的想法就是:穷举之后的每一种下法,然后计算每一步赢棋的概率,选择概率最高的。如下图。
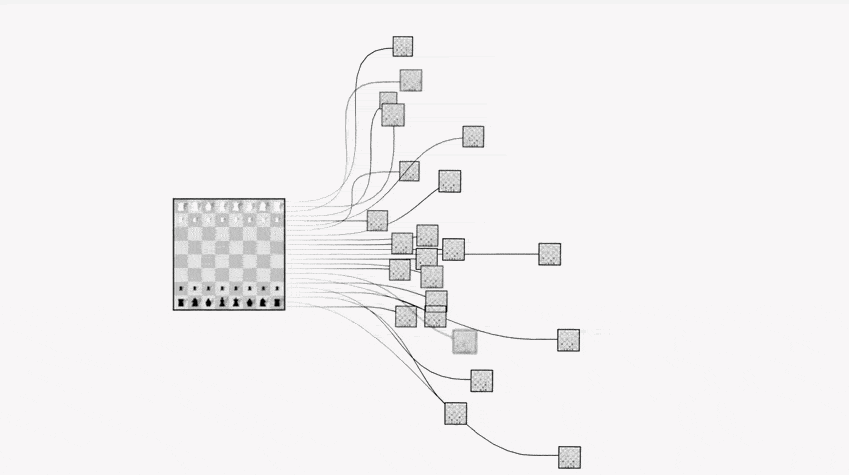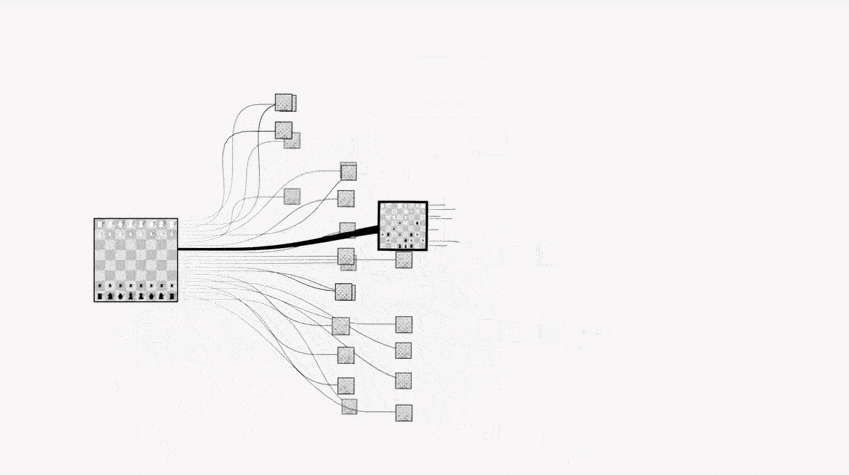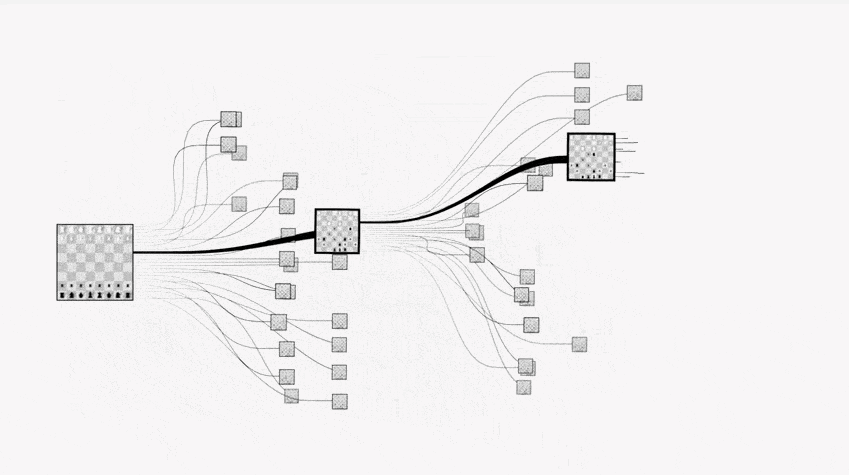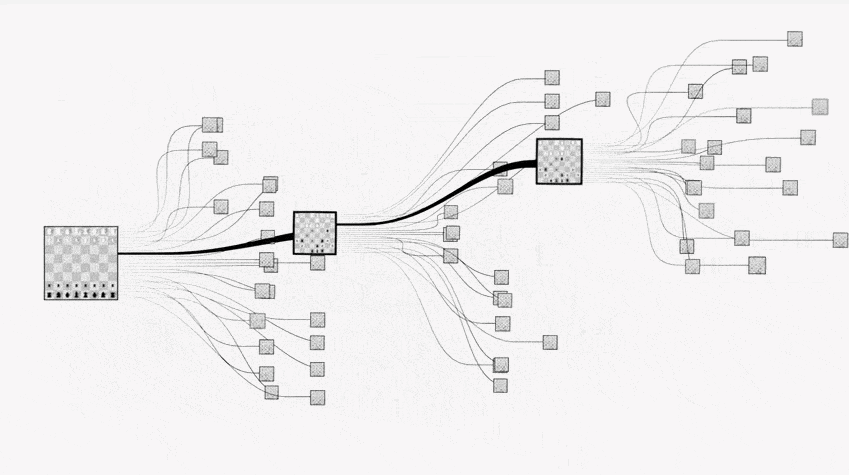
然而围棋的维度太高(19*19),状态空间是天文数字,穷举是不现实的。如下图。
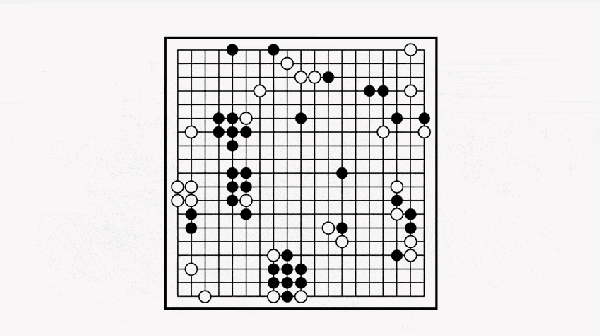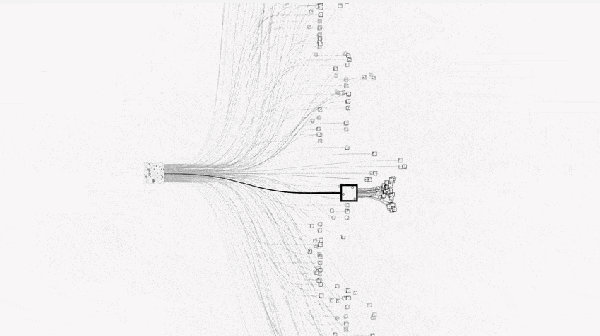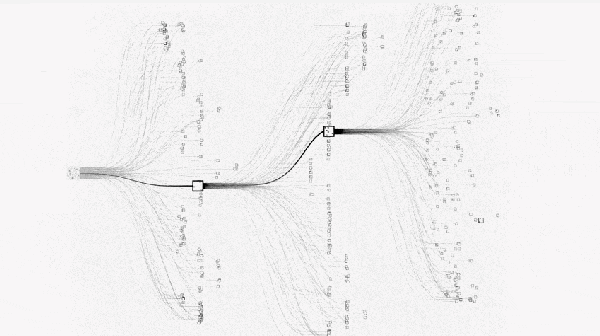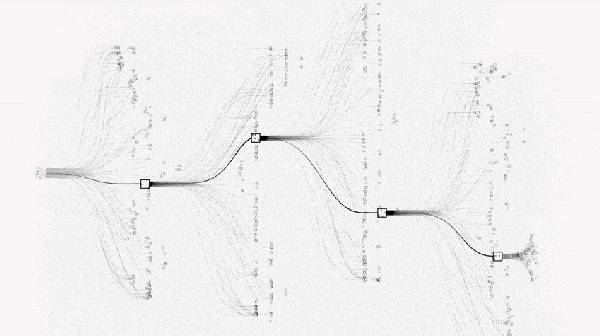
这时就要用蒙特卡罗树搜索方法:就是从给定落子位置开始,随机采样后续棋局(模拟),得到一个模拟的结果。经过 n 次随机采样模拟之后,将平均成功率返回作为该点的成功率。
简而言之:
- 当前状态的基础上,选择一个备选动作/状态;
- 从备选动作/状态开始,不需要枚举后续所有状态。只要以一定的策略(如随机策略或者AlphaGo中的快速走棋网络)一直模拟到游戏结束为止;
- 计算这次采样的回报;
- 重复几次,将几次回报求平均,以此获得该备选动作/状态的价值。
换言之,即用频率来估计概率。采样的样本数越多,频率越接近概率。从定性的角度上讲,Monte-Carlo 法就是用采样结果的频率来估计真实的概率。就相当于我们随机抛硬币,只要抛的次数足够多,那么,正面朝上的频率会无限接近于 0.5。
上面四个步骤对应着蒙特卡罗树搜索的四个步骤:

其通过随机的对游戏进行推演,来逐渐建立一棵不对称的搜索树的过程。可以看成是某种意义上的强化学习。
3. 阿尔法狗:DL+MCTS
搞清楚一些基本点,再来看阿尔法狗的实现原理。
先来张图,非常nice:

该文看后比较清楚。作者是郑宇研究员,微软亚洲研究院,现在在西电开着一门城市计算的课。以下主要来自其博文的摘录。
AlphaGo总体上包含:
- 离线学习(上图上半部分)
- 在线对弈(上图下半部分)
3.1 离线学习过程
分为三个训练阶段。
第一阶段:利用3万多幅专业棋手对局的棋谱来训练两个网络。
一个是基于全局特征和深度卷积网络(CNN)训练出来的策略网络(Policy Network),其主要作用是给定当前盘面状态作为输入,输出下一步棋在棋盘其它空地上的落子概率。
另一个是利用局部特征和线性模型训练出来的快速走棋策略(Rollout Policy)。
策略网络速度较慢,但精度较高;快速走棋策略反之。
第二阶段:自我对弈——增强式学习
利用第t轮的策略网络与先前训练好的策略网络互相对弈,利用增强式学习来修正第t轮的策略网络的参数,最终得到增强的策略网络。
这部分被很多“砖”家极大的鼓吹,但实际上应该存在理论上的瓶颈(提升能力有限)。这就好比2个6岁的小孩不断对弈,其水平就会达到职业9段?
第三阶段:先利用普通的策略网络来生成棋局的前U-1步(U是一个属于[1, 450]的随机变量),然后利用随机采样来决定第U步的位置(这是为了增加棋的多样性,防止过拟合)。
随后,利用增强的策略网络来完成后面的自我对弈过程,直至棋局结束分出胜负。此后,第U步的盘面作为特征输入,胜负作为label,学习一个价值网络(Value Network),用于判断结果的输赢概率。
价值网络其实是AlphaGo的一大创新,围棋最为困难的就是很难根据当前的局势来判断最后的结果,这点职业棋手也很难掌握。
通过大量的自我对弈,AlphaGo产生了3000万盘棋局,用作训练学习价值网络。但由于围棋的搜索空间太大,3000万盘棋局也不能帮AlphaGo完全攻克这个问题。
3.2在线对弈过程
包括以下5个关键步骤。其核心思想是在蒙特卡洛搜索树(MCTS)中嵌入深度神经网络来减少搜索空间。AlphaGo并没有具备真正的思维能力。
1、根据当前盘面已经落子的情况提取相应特征;
2、利用策略网络估计出棋盘其他空地的落子概率(用网络结果代替随机。在expansion的步骤,我们不用从零开始随机的生成一个前所未有的状态,而是用根据前人经验训练的策略网络直接生成新状态, 海量了减小了无用的搜索。 );
3、根据落子概率来计算此处往下发展的权重,初始值为落子概率本身(如0.18)。实际情况可能是一个以概率值为输入的函数,此处为了理解简便。
4、利用价值网络和快速走棋网络分别判断局势,两个局势得分相加为此处最后走棋获胜的得分。(网络来帮助估值。在Evaluation的步骤上, 我们可以不需要跑完整个比赛,而是通过深度学习的结果直接算出这个新姿势可能的回报,即估值网络的作用)
这里使用快速走棋策略是一个用速度来换取量的方法,从被判断的位置出发,快速行棋至最后,每一次行棋结束后都会有个输赢结果,然后综合统计这个节点对应的胜率。
价值网络只要根据当前的状态便可直接评估出最后的结果。两者各有优缺点、互补。
5、利用第四步计算的得分来更新之前那个走棋位置的权重(如从0.18变成了0.12);此后,从权重最大的0.15那条边开始继续搜索和更新。
这些权重的更新过程应该是可以并行的。当某个节点的被访问次数超过了一定的门限值,则在蒙特卡罗树上进一步展开下一级别的搜索。
4. AlphaGo的特点
观察到:AlphaGo倾向于只赢很少的「目」数。而且,当它处于优势地位时,它会表现得更加保守;反之,会更加具有进攻性;(甚至给人以一种让棋的错觉)
可能原因:因为训练只记录「输赢」结果,并不会记录具体「目」数。而在实际对弈过程中,两个水平相当的选手最后「目」数接近的概率很高。因此,AlphaGo 的训练数据主要集中在低「目」数输赢的情况下。
对于能够赢得高「目」数的棋局,AlphaGo 没怎么见过。当看到有机会拿到高分的棋局时,它反而可能没法继续保持高水平状态,会「选择」更加保守的策略。
AlphaGo有没有弱点?郑宇老师分析了几个:
1、攻其策略网络,加大搜索空间。
进入中盘后,职业选手如能建立起比较复杂的局面,每一步棋都牵连很多个局部棋的命运(避免单块、局部作战),则AlphaGo需要搜索空间则急剧加大,短时间内得到的解的精度就会大打折扣。
李世石九段的第四局棋就有这个意思。此处左右上下共5块黑白棋都相互关联到一起,白1下后,黑棋需要考虑很多地方。很多地方都需要在MCTS上进行更深入的搜索。为了在一定的时间内有结果,只能放弃搜索精度。
2、攻其价值网络,万劫不复。
AlphaGo的价值网络极大的提高了之前单纯依靠MCTS来做局势判断的精度,但离准确判断围棋局势还有不小的差距。神经网络还不能完全避免在某些时候出现一些怪异(甚至错误)的判断,更何况其训练样本还远远不足。这也是为什么有了价值网络,还仍然需要依靠快速走棋来判断局势。
大家都曾经怀疑过AlphaGo的打劫能力,也感觉到了AlphaGo有躲避打劫的迹象。实际上南京大学的周志华教授曾经撰文指出过打劫会让价值网络崩溃的问题,原理不再重复。总之,打劫要乘早,太晚了搜索空间变小,即便价值网络失效,还可以靠快速走棋网络来弥补。开劫应该以在刚刚进入中盘时期为好(太早劫材还不够),并切保持长时间不消劫,最好在盘面上能同时有两处以上打劫。没有了价值网络的AlphaGo其实水平也就职业3段左右。
参考资料
【1】跟着阿尔法狗理解深度强化学习
【2】一张图看懂:google AlphaGo的原理、弱点
【3】要不我也说说AlphaGo?
【4】蒙特卡罗树是什么算法?知乎
- AlphaGo的原理
- AlphaGo原理分析
- AlphaGo原理探讨
- Alphago原理浅析
- AlphaGo原理浅析
- AlphaGo Zero原理浅析
- 深度解读 AlphaGo 算法原理
- 深度解读 AlphaGo 算法原理
- AlphaGo原理、应用与意义
- AlphaGo
- 一张图解AlphaGo原理及弱点
- 一张图解AlphaGo原理及弱点
- 一张图解AlphaGo原理及弱点
- 一张图解AlphaGo原理及弱点
- 来自Google的围棋AlphaGo
- AlphaGo怎么下围棋的
- AlphaGo是如何实现的
- AlphaGo的神力来自何处?
- Android Studio新功能解析,你真的了解Instant Run吗?
- Android检查更新下载安装
- unity的触摸类touch使用
- excel下载(使用线程)
- 织梦DedeCMS简略标题
- AlphaGo的原理
- 在Ubuntu中设置samba共享可读写文件夹
- 小试4解析
- 拨开字符编码的迷雾--MySQL数据库字符编码
- 慕课网编程练习:制作一个表格,显示班级的学生信息。
- YJCocoa Gem开源库
- 软件测试学习6-动态白盒测试
- 电话程控交换机安装经验
- mysql基础1


