Tensorflow 处理结构
来源:互联网 发布:企业对网络的需求分析 编辑:程序博客网 时间:2024/06/06 19:09
Tensorflow 首先要定义神经网络的结构, 然后再把数据放入结构当中去运算和 training. 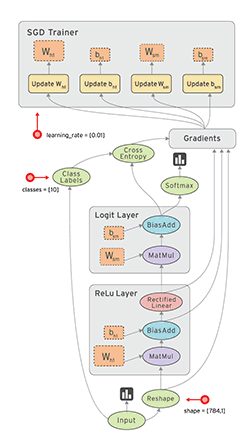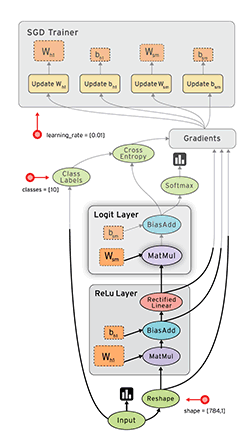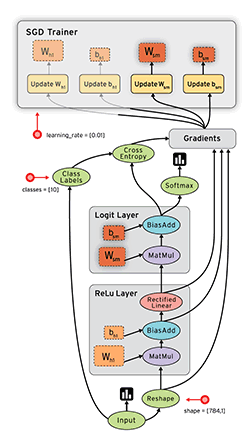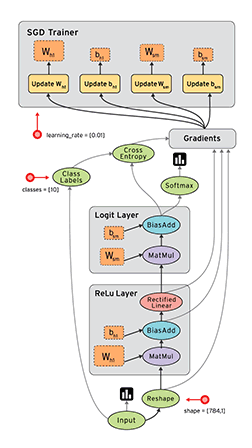
tensorflow的中文翻译就是向量在这个结构里面飞.因为TensorFlow是采用数据流图(data flow graphs)来计算, 所以首先我们得创建一个数据流流图, 然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算. 节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor). 训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来.
张量(tensor)
张量有多种.
- 零阶张量为 纯量或标量 (scalar) 也就是一个数值. 比如 [1]
- 一阶张量为 向量 (vector), 比如 一维的 [1, 2, 3]
- 二阶张量为 矩阵 (matrix), 比如 二维的 [[1, 2, 3],[4, 5, 6],[7, 8, 9]]
以此类推, 还有 三阶 三维的
Tensorflow 是非常重视结构的, 我们得建立好了神经网络的结构, 才能将数字放进去, 运行这个结构.
例子
下面这个例子将简单的阐述 tensorflow 当中如何用代码来运行我们搭建的结构.
预测一个线性的直线:y = 0.5x+0.7. 想要显示每次训练之后输出的权重和偏执参数是多少
实例代码:
#-*- coding:utf-8 -*-import tensorflow as tfimport numpy as np#create some datex_data = np.random.rand(100).astype(np.float32) y_data = x_data*0.5+0.7#创建tensorflow结构开始Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0))#一维结构,随机数列的范围 -1~1biases = tf.Variable(tf.zeros([1]))#初始在为0#通过学习,W,B将不段的提升到我们接近我们的y_datay = Weights*x_data+biases#计算 y 和 y_data 的误差:loss = tf.reduce_mean(tf.square(y-y_data))#建立优化器减少误差 提升参数的准确度optimizer= tf.train.GradientDescentOptimizer(0.1)#误差传递方法是梯度下降法: Gradient Descent train = optimizer.minimize(loss) #使用 optimizer 来进行参数的更新#初始化变量init = tf.global_variables_initializer()#创建tensorflow结构结束#定义会话sess = tf.Session()sess.run(init) #激活神经网络 很重要#训练for step in range(501): #用 Session 来 run 每一次 training 的数据. 逐步提升神经网络的预测准确性. sess.run(train) if step%20 == 0: print (step,sess.run(Weights),sess.run(biases))输出
(0, array([-0.70330155], dtype=float32), array([ 0.28489518], dtype=float32))
(20, array([-0.06656488], dtype=float32), array([ 1.01636899], dtype=float32))
(40, array([ 0.06568325], dtype=float32), array([ 0.94458628], dtype=float32))
(60, array([ 0.16638607], dtype=float32), array([ 0.88788038], dtype=float32))
(80, array([ 0.24373767], dtype=float32), array([ 0.84431857], dtype=float32))
(100, array([ 0.30315456], dtype=float32), array([ 0.81085688], dtype=float32))
(120, array([ 0.34879521], dtype=float32), array([ 0.78515363], dtype=float32))
(140, array([ 0.38385361], dtype=float32), array([ 0.76540983], dtype=float32))
(160, array([ 0.41078332], dtype=float32), array([ 0.7502439], dtype=float32))
(180, array([ 0.43146914], dtype=float32), array([ 0.73859429], dtype=float32))
(200, array([ 0.44735864], dtype=float32), array([ 0.72964591], dtype=float32))
(220, array([ 0.45956409], dtype=float32), array([ 0.72277218], dtype=float32))
(240, array([ 0.46893957], dtype=float32), array([ 0.71749222], dtype=float32))
(260, array([ 0.47614124], dtype=float32), array([ 0.71343642], dtype=float32))
(280, array([ 0.48167321], dtype=float32), array([ 0.71032107], dtype=float32))
(300, array([ 0.48592243], dtype=float32), array([ 0.707928], dtype=float32))
(320, array([ 0.48918641], dtype=float32), array([ 0.70608985], dtype=float32))
(340, array([ 0.49169371], dtype=float32), array([ 0.70467776], dtype=float32))
(360, array([ 0.49361959], dtype=float32), array([ 0.70359319], dtype=float32))
(380, array([ 0.49509889], dtype=float32), array([ 0.7027601], dtype=float32))
(400, array([ 0.49623531], dtype=float32), array([ 0.70212013], dtype=float32))
(420, array([ 0.49710816], dtype=float32), array([ 0.70162857], dtype=float32))
(440, array([ 0.49777865], dtype=float32), array([ 0.70125097], dtype=float32))
(460, array([ 0.4982937], dtype=float32), array([ 0.70096087], dtype=float32))
(480, array([ 0.49868938], dtype=float32), array([ 0.70073807], dtype=float32))
(500, array([ 0.49899328], dtype=float32), array([ 0.70056695], dtype=float32))
在最后权重和偏置已经非常接近0.5和0.7了,训练的次数越多越准确.
- Tensorflow 处理结构
- tensorflow的结构
- Tensorflow结构简介
- tensorflow目录结构
- Tensorflow结构构建
- TensorFlow目录结构
- TensorFlow之基本结构
- tensorflow入门之tensorflow的运行结构
- Tensorflow 图像处理函数
- 12、TensorFlow 图像处理
- Tensorflow入门五 AlexNet结构
- TensorFlow代码结构优化tips
- Tensorflow卷积神经网络常用结构
- tensorflow如何自由处理梯度
- tensorflow用CNN 处理文本
- tensorflow.org 打不开的处理
- tensorflow学习之图像处理
- tensorflow object_dection API错误处理
- django 数据库 get_or_create函数返回值是tuple
- 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
- kea安装(数据库配置mysql)
- Dreamweaver CS6破解教程[序列号+破解补丁]
- GitChat · 区块链 | 教你如何轻松学习区块链和比特币基础技术原理
- Tensorflow 处理结构
- thinkPHP中数组应用
- 面试考察get和post的区别及应用场景
- Swift 中的类型属性
- 数据的增删改查
- Canal权限问题排查
- 哈密顿行动(黑客/安全体验游戏,服务器已恢复)
- 前端技术之iframe2
- Python的安装与配置环境变量


