Python抓取网页图片
来源:互联网 发布:电脑控制手机桌面软件 编辑:程序博客网 时间:2024/05/21 21:38
网上的代码基本上都是python2,这里的代码使用的是python3注意没有urllib2这个库了。
要先做几个个准备工作:
①找到有图片的网站
②指定电脑保存路径
③利用浏览器工具查看网页代码中图片的保存路径(非常重要,如果错误可能抓取不到)
下面给出代码:
注意看注释
import reimport urllib.request # Python2中使用的是urllib2import urllibimport osdef getHtml(url): '获取网站地址' page = urllib.request.urlopen(url) html = page.read() return html.decode('UTF-8')def getImg(html): '图片地址注意要从浏览器中查看网页源代码找出图片路径' # 要加括号,作为元组返回 #reg = r'src="(.+?\.jpg)" pic_ext' # 某个贴吧的图片 reg = r'data-progressive="(.+?\.jpg)" ' # Bing壁纸合集抓取地址 # reg = r'src="(.+?\.jpg)" ' # 我的网站图片地址 # reg = r'zoomfile="(.+?\.jpg)" ' # 威锋网手机壁纸 imgre = re.compile(reg) imglist = imgre.findall(html) x = 0 path = 'E:\\Temporary\\new' # 输入保存文件的目录地址 if not os.path.isdir(path): os.makedirs(path) # 检查是否存在地址,如果不存在将自动创建文件夹目录 paths = path + '\\' # 保存在test路径下 for imgurl in imglist: urllib.request.urlretrieve(imgurl, '{}{}.jpg'.format(paths, x)) x = x + 1if __name__ == '__main__': # html = getHtml("http://bbs.feng.com/read-htm-tid-10616371.html") # 威锋网手机壁纸 # html = getHtml("http://www.omegaxyz.com/") # 我的网站图片地址 html = getHtml("https://bing.ioliu.cn/ranking") # Bing壁纸合集抓取地址 # html = getHtml("http://tieba.baidu.com/p/2460150866") # 某个贴吧的图片 getImg(html)注意以上代码在pycharm python3.6.2环境运行
效果截图: 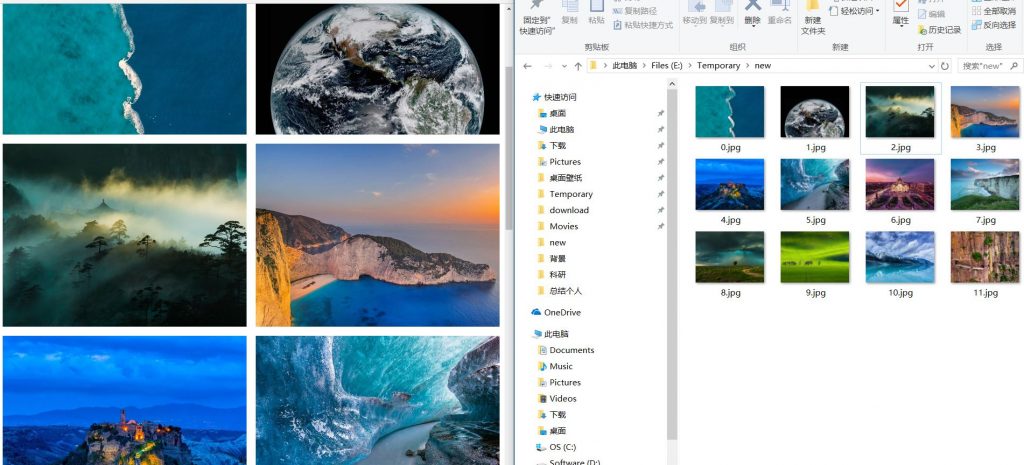
阅读全文
0 0
- python抓取网页图片
- python抓取网页图片
- Python抓取网页图片
- python抓取网页图片
- Python抓取网页图片
- Python爬虫抓取网页图片
- Python爬虫抓取网页图片
- python网络爬虫,抓取网页图片
- python抓取网页图片的脚本
- 用Python抓取网页上的图片
- 爬虫抓取网页图片
- 从网页抓取图片
- php抓取网页图片
- java 抓取网页图片
- 爬虫抓取网页图片
- 网页图片抓取
- Python3抓取网页图片
- 20 行python代码抓取网页中所有JPG图片
- 计算机漏洞安全相关的概念POC | EXP | VUL | CVE | 0DAY
- Gan与imitation learning,theano平台搭建(1)
- java 内存分配
- 英语关键词解析
- 为什么Winforms控件不支持半透明的背景颜色
- Python抓取网页图片
- 1008. 数组元素循环右移问题 (20)--PAT乙级
- 验证码点击无法更新处理
- 使用Explorer++批量打开多个目录
- JAVAEE之jQuery
- Leetcode 661
- 快速查找素数-0J
- mtd驱动分析-硬件驱动层
- 【util】用java实现16进制和byte,string的相互转换以及格式化16进制


