机器学习-过拟合 (Overfitting)
来源:互联网 发布:极客湾淘宝店 编辑:程序博客网 时间:2024/05/14 21:57
在统计学和机器学习中,overfitting一般在描述统计学模型随机误差或噪音时用到。它通常发生在模型过于复杂的情况下,如参数过多等。overfitting会使得模型的预测性能变弱,并且增加数据的波动性。
看下图: 
绿线表示overfitting的模型,黑线表示正则化模型。虽然绿线最符合训练数据,但它太依赖于它,并且与黑线相比,新的未看见的数据可能具有更高的错误率。说白了, 就是机器学习模型于自信。 已经到了自负的阶段了。说到自负的坏处, 就是在自己的小圈子里表现非凡, 不过在现实的大圈子里却往往处处碰壁。所以在这里可以自负和过拟合画上等号。
underfitting 发生在统计模型和机器学习算法无法捕获数据的基本趋势时例如:当拟合一个线性模型到非线性数据时。就会发生underfitting,模型的预测性能就会很差了。
下图就是欠 - 均衡 - 过 拟合的对比图。 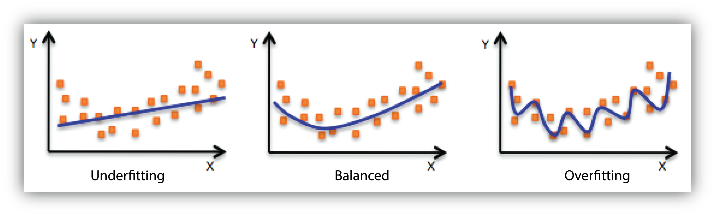
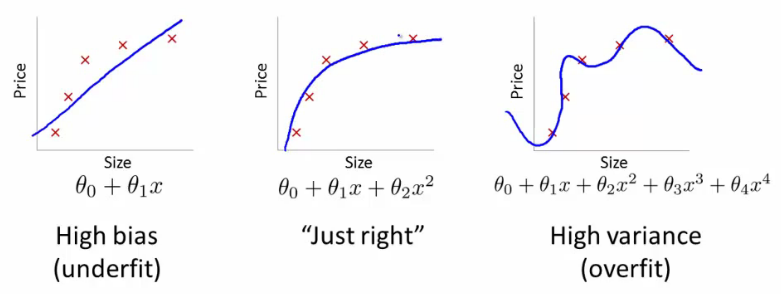
如何避免过拟合
增加数据量, 大部分过拟合产生的原因是因为数据量太少了. 如果我们有成千上万的数据, 曲线线也会慢慢被拉直, 变得没那么扭曲
运用正规化. L1, l2 regularization、交叉验证、early stopping、贝斯信息量准则、赤池信息量准则或model comparison,以指出何时会有更多训练而没有导致更好的一般化.这些方法适用于大多数的机器学习, 包括神经网络.Overfitting的概念在机器学习中很重要。通常一个学习算法是借由训练样本来训练的,在训练时会伴随着训练误差。当把该模型用到未知数据的测试时,就会相应的带来一个validation error。下面通过训练误差和验证误差来详细分析一下overfitting。如下图:
蓝色表示训练误差training error,红色表示validation error。当训练误差达到中间的那条垂直线的点时,模型应该是最优的,如果继续减少模型的训练误差,这时就会发生过拟合.

wikipedia 的overfitting解释
- 机器学习-过拟合 (Overfitting)
- 机器学习—过拟合overfitting
- NTU-Coursera机器学习:过拟合(Overfitting)与正规化(Regularization)
- 机器学习笔记05:正则化(Regularization)、过拟合(Overfitting)
- 机器学习--神经网络算法系列--过拟合(overfitting)
- 机器学习中:过拟合(overfitting)和欠拟合(underfitting)
- 听课笔记(第十三讲): 过拟合 - Overfitting (台大机器学习)
- 听课笔记(第十三讲): 过拟合 - Overfitting (台大机器学习)
- 过拟合(overfitting)
- 过拟合overfitting
- 过拟合overfitting
- 机器学习过拟合
- 机器学习过拟合
- overfitting(过拟合)的概念
- 14过拟合(Overfitting)
- [机器学习]04.多级分类(Multiclass classfication) 过度拟合(overfitting)
- 【机器学习】过拟合与欠拟合
- 机器学习--欠拟合与过拟合
- 数据库事务的四大特性
- uvalive 3708 墓地雕塑
- java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
- Java SE的复习1
- Leetcode c语言-Container With Most Water
- 机器学习-过拟合 (Overfitting)
- 简谈JAVA基础--ArrayList
- python基础教程读书笔记——第二章 列表和元组
- itchat 实现简单的微信控制电脑
- Retrofit常见注解全解析
- SQL性能优化
- LintCode 最长无重复字符的子串
- 深度学习--数据增强
- 前端测试介绍


