机器学习归纳总结
来源:互联网 发布:网站域名申请流程 编辑:程序博客网 时间:2024/05/31 19:15
机器学习归纳总结
模型评估与选择
经验误差与过拟合
错误率 = a个样本分类错误/m个样本
精度 = 1 - 错误率
误差:学习器实际预测输出与样本的真是输出之间的差异。
训练误差:即经验误差。学习器在训练集上的误差。
泛化误差:学习器在新样本上的误差。
过拟合:学习器把训练样本学的”太好”,把不太一般的特性学到了,泛化能力下降,对新样本的判别能力差。必然存在,无法彻底避免,只能够减小过拟合风险。
欠拟合:对训练样本的一半性质尚未学好。
评估方法
用一个测试集来测试学习其对新样本的判别能力,然后以测试集上的测试误差作为泛化误差的近似。
在只有一个包含m个样例的数据集D,从中产生训练集S和测试集T。
性能度量
性能度量:衡量模型泛化能力的评价标准。
给定样例集D={(x1,y1),(x2,y2),……,(xm,ym)},yi是对xi的真实标记,要评估学习器f的性能,就要把学习器预测结果f(x)与真实标记y进行比较。
均方误差:
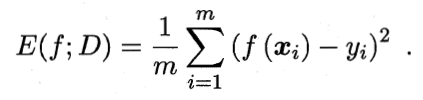
数据分布D和概率密度函数p(.),均方误差:
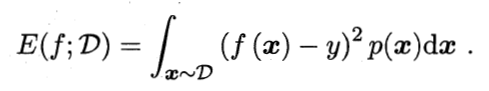
比较检验
默认以错误率为性能度量,用ε表示。
偏差与方差
偏差-方差分解:解释学习算法泛化性能的一种重要工具。
线性模型
基本形式
f(x)=wTx+b 线性回归
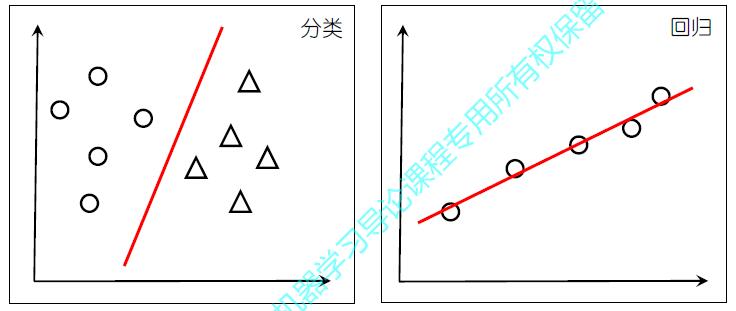
对数几率回归

线性判别分析
若将W视为一个投影矩阵,则多分类LDA将样本投影到N-1维空间,N-1通常远小于数据原有的属性数,于是,可通过这个投影来减小样本点的维数,且投影过程中使用了类别信息,因此LDA也常常被视为一种经典的监督降维技术。
多分类学习
现实中常遇到多分类学习任务,有些二分类学习方法可以直接推广到多分类,但在更多情形下,我们是基于一些基本策略,利用二分类学习器来解决多分类问题。
最经典的拆分策略:“一对一 OvO” “一对多 OvR” “多对多 MvM”
ECOC(纠错输出码) 是一种最常用的MvM技术。它是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性。
神经网络学习

RBF神经网络

BP神经网络

SOM神经网络

自组织神经网络

Hopfield神经网络

SVM
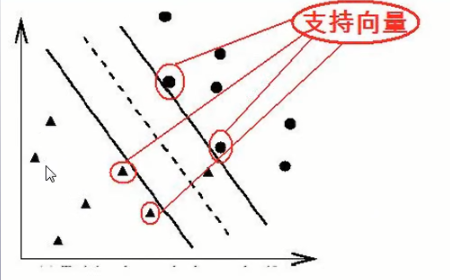
SVM 的主要思想是建立一个超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化
聚类
- 聚类指事先并不知道任何样本的类别标号,希望通过某种算法来把一组未知类别的样本划分成若干类别,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起,这在机器学习中被称作 unsupervised learning (无监督学习)
- 通常,人们根据样本间的某种距离或者相似性来定义聚类,即把相似的(或距离近的)样本聚为同一类,而把不相似的(或距离远的)样本归在其他类。
- 聚类的目标:组内的对象相互之间时相似的(相关的),而不同组中的对象是不同的(不相关的)。组内的相似性越大,组间差别越大,聚类就越好。
降维与度量学习
降维在一起图像识别过程也经常被采用的一种分类算法,例如二维数据经过投影变为一维数据,从而更好的表征数据的特征,再进行识别。在前面章节中提到过LDA(线性判别分析)也可以当做一种简单降维处理。在周老师的这章中主要讲述PCA主成分分析算法对高维数据进行降维。降维是一种解决维数灾难的重要途径。
在机器学习中,对高维数据进行降维的主要目的是希望找到一个合适的低维空间,在此空间中进行学习能比原始空间性能更好。事实上,每个空间对应了在样本属性上定义的一个距离度量,而寻找合适的空间,实质上就是在寻找一个合适的距离度量。因此我们可以尝试直接学习出一个合适的距离度量。也就是度量学习。
- 机器学习--归纳总结
- 机器学习归纳总结
- 机器学习-学习笔记 学习总结归纳(第四周)
- 机器学习-学习笔记 学习总结归纳(第五周)
- 机器学习-学习笔记 学习总结归纳(第六周)
- 机器学习-学习笔记 学习总结归纳(第七周)
- 机器学习-学习笔记 学习总结归纳(第八周)
- 机器学习-学习笔记 学习总结归纳(第九周)
- 机器学习-学习笔记 学习总结归纳(第十周)
- 机器学习-学习笔记 学习总结归纳(第十一周)
- 机器学习-学习笔记 学习总结归纳(第十二周)
- 机器学习-学习笔记 学习总结归纳(第十三周)
- 机器学习-学习笔记 学习总结归纳(第十四周)
- DFS学习归纳总结
- 机器学习(三) - - 归纳偏好
- 小结某些机器学习算法归纳偏置
- 机器学习笔记八:常见“距离”归纳
- 机器学习笔记(三)归纳偏好
- VTK环境配置中的一些问题
- 接Kafka数据比对不同hbase中数据
- 机器视觉Halcon——3. Halcon实例clip回形针方向识别
- [笔记]《操作系统精髓与设计原理》---(7)文件管理
- JAVA8新特性(一)——函数性编程
- 机器学习归纳总结
- Spring Cloud下微服务权限方案
- 【服务器】关于内存使用率的问题
- html+css 基础学习文档结构
- 移动商城第八篇【添加商品之基本属性和大字段数据(FCK文本编辑器)】
- Maven(一) 下载安装
- python
- 相关数学知识
- jQuery UI 中的 datepicker( )方法


