前向传播和反向传播(举例说明)
来源:互联网 发布:ip域名查询 编辑:程序博客网 时间:2024/05/29 12:23
假设神经网络结构如下图所示:有2个输入单元;隐含层为2个神经元;输出层也是2个神经元,隐含层和输出层各有1个偏置。

为了直观,这里初始化权重和偏置量,得到如下效果:

----前向传播----
隐含层神经元h1的输入:
代入数据可得:
假设激励函数用logistic函数,计算得隐含层神经元h1的输出:
同样的方法,可以得到隐含层神经元h2的输出为:
对输出层神经元重复这个过程,使用隐藏层神经元的输出作为输入。这样输出层神经元O1的输出为:
代入数据:
输出层神经元O1的输出:
同样的方法,可以得到输出层神经元O2的输出为:
----统计误差----
假如误差公式为:
如上图,O1的原始输出为0.01,而神经网络的输出为0.75136507,则其误差为:
同理可得,O2的误差为:
这样,总的误差为:
----反向传播----
对于w5,想知道其改变对总误差有多少影响,得求偏导:
根据链式法则:
在这个过程中,需要弄清楚每一个部分。
首先:
其次:

最后:
把以上三部分相乘,得到:

根据梯度下降原理,从当前的权重减去这个值(假设学习率为0.5),得:
同理,可以得到:
这样,输出层的所以权值就都更新了(先不管偏置),接下来看隐含层:
对w1求偏导:

用图表来描述上述链式法则求导的路径:

接下来,又是一部分一部分的计算:
>>>>>>>> 1

上式中,第一部分前边已经计算过了:
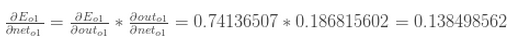
第二部分中,因为:
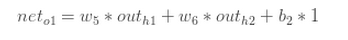
所以:
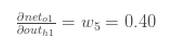
两部分相乘,得:
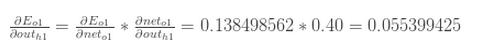
>>>>>>>> 2

>>>>>>>> 3
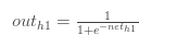
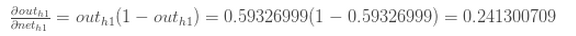
>>>>>>>> 4
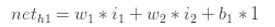
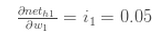
这样对W1的偏导就出来了:
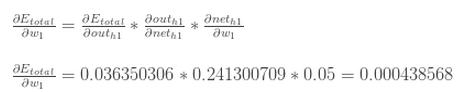
更新权值:
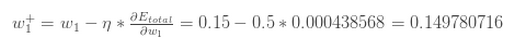
同理得到:
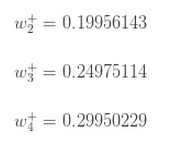
最后,更新了所有的权重! 当最初前馈传播时输入为0.05和0.1,网络上的误差是0.298371109。 在第一轮反向传播之后,总误差现在下降到0.291027924。 它可能看起来不太多,但是在重复此过程10,000次之后。例如,错误倾斜到0.000035085。
在这一点上,当前馈输入为0.05和0.1时,两个输出神经元产生0.015912196(相对于目标为0.01)和0.984065734(相对于目标为0.99)。
- 前向传播和反向传播(举例说明)
- caffe学习笔记3.2--前向传播和反向传播
- 神经网络中前向传播和反向传播解析
- 深度学习之caffe 前向传播和反向传播
- caffe学习笔记3.2--前向传播和反向传播
- Caffe源码解读:relu_layer前向传播和反向传播
- 神经网络(前向传播和反向传导)
- CNN卷积神经网络--反向传播(2,前向传播)
- 前向传播与反向传播代码
- 神经网络的前向传播和误差反向传播(NN,RNN,LSTM)(一)
- 神经网络的前向传播和误差反向传播(NN,RNN,LSTM)(二)
- 神经网络的前向传播和误差反向传播(NN,RNN,LSTM)(三)
- pooling mean max 前向和反向传播
- Batch Normalization的前向和反向传播过程
- pooling mean max 前向和反向传播
- C++从零实现深度神经网络之二——前向传播和反向传播
- 深度学习:神经网络中的前向传播和反向传播算法推导
- 前馈神经网络和反向传播算法
- Android7.0 PhoneApp的启动
- 实验一:写一个hello world小程序
- 地址转经纬度(百度)function
- 西瓜书-机器学习《一》
- %:的使用
- 前向传播和反向传播(举例说明)
- python- 路径
- LINTCODE——逆序对
- python执行sql文件
- 【网站建设】搭建简单动态网站
- 控件相对屏幕的坐标位置
- hdu2588(欧拉函数)
- 数值转换 Number() parseInt() parseFloat()
- BPI-M1P(全志A20)刷Android启动卡之后启动的过程


