JDK容器学习之HashMap (二) : 读写逻辑详解
来源:互联网 发布:app p图软件 编辑:程序博客网 时间:2024/06/05 20:07
Map读写实现逻辑说明
前一篇博文 JDK容器学习之HashMap (一) : 底层存储结构分析 分析了HashMap的底层存储数据结构
通过
put(k,v)方法的分析,说明了为什么Map底层用数组进行存储,为什么Node内部有一个next节点,这篇则将集中在读写方法的具体实现上
本片博文将关注的重点:
- 通过key获取value的实现逻辑
- 新增一个kv对的实现逻辑
- table 数组如何自动扩容
- 如何删除一个kv对(删除kv对之后,数组长度是否会缩水 ?)
1. 根据key索引
get(key)作为map最常用的方法之一,根据key获取映射表中的value,通常时间复杂度为o(1)
在分析之前,有必要再把HashMap的数据结构捞出来看一下
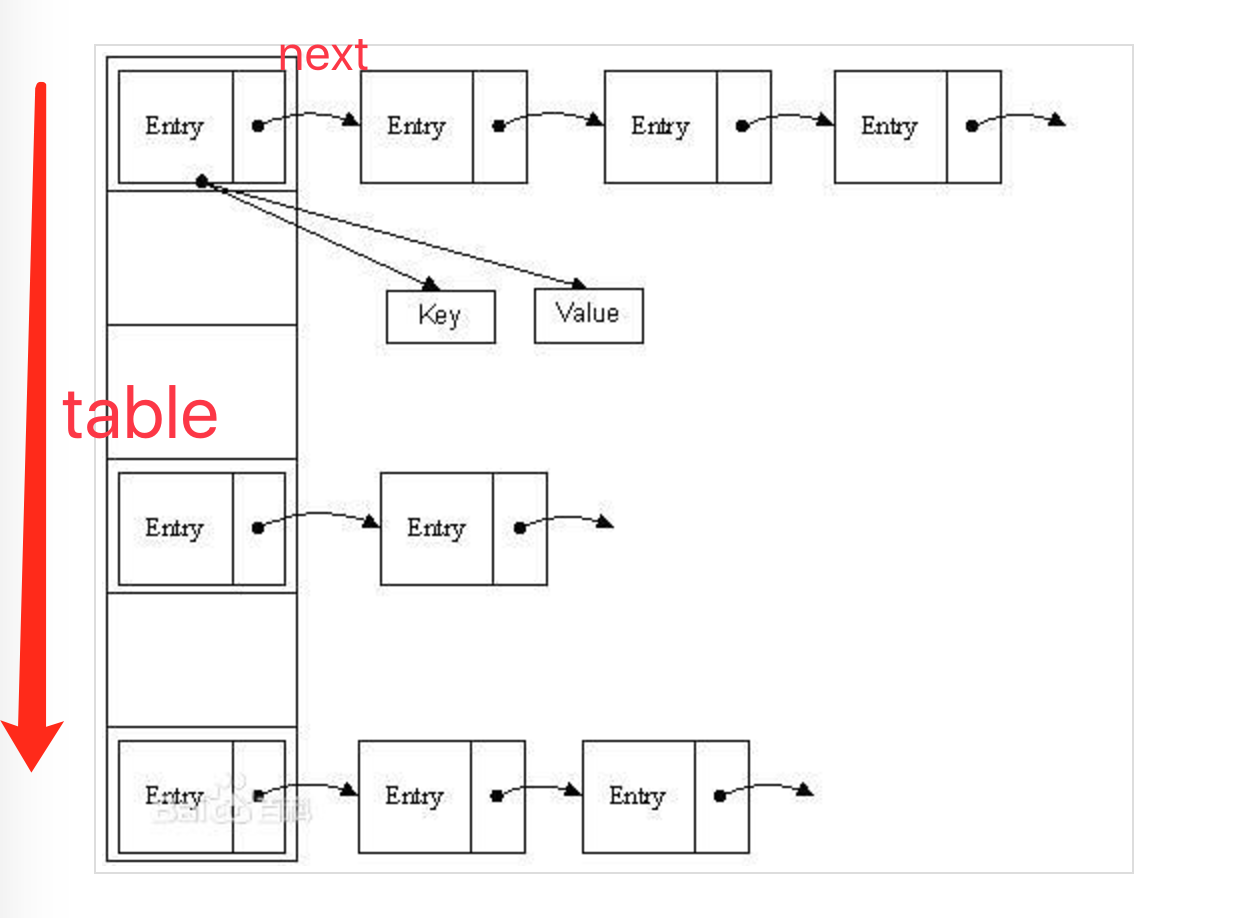
根据上面的结构,如果让我们自己来实现这个功能,对应的逻辑应该如下:
- 计算key的hash值
- 根据hash确定在
table数组中的位置 - 判断数组的Node对象中key是否等同与传入的key
- 若不是,则一次扫描
next节点的key,直到找到为止
jdk实现如下
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; // 判断条件 if 内部逻辑如下 // table 数组已经初始化(即非null,长度大于0) // 数组中根据key查到的Node对象非空 if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) // 红黑树中查找 return ((TreeNode<K,V>)first).getTreeNode(hash, key); do {// 遍历链表 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null;}上面的逻辑算是比较清晰,再简单的划一下重点
通过key定位table数组中索引的具体逻辑
hash(key) & (table.length - 1)- key的hash值与(数组长度-1)进行按位与,计算得到下标
判断Node是否为所查找的目标逻辑
node.hash == hash(key) && (node.key == key || (key!=null && key.equals(node.key))- 首先是hash值必须相等
and == or equals- key为同一个对象
- or Node的key等价于传入的key
TreeNode 是个什么鬼
上面的逻辑中,当出现hash碰撞时,会判断数组中的
Node对象是否为TreeNode,如果是则调用TreeNode.getTreeNode(hash,key)方法那么这个TreeNode有什么特殊的地方呢?
2. TreeNode 分析
TreeNode依然是HashMap的内部类, 不同于Node的是,它继承自LinkedHashMap.Entry,相比较与Node对象而言,多了两个属性before, after
1. 数据结构
TreeNode对象中,包含的数据如下(将父类中的字段都集中在下面了)
// Node 中定义的属性final int hash;final K key;V value;Node<K,V> next;// ---------------// LinkedHashMap.Entry 中的属性Entry<K,V> before, after;// ---------------// TreeNode 中定义的属性TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;2. 内部方法
方法比较多,实现也不少,但是看看方法名以及注释,很容易猜到这是个什么东西了
红黑树
具体方法实现身略(对红黑树实现有兴趣的,就可以到这里来膜拜教科书的实现方式)
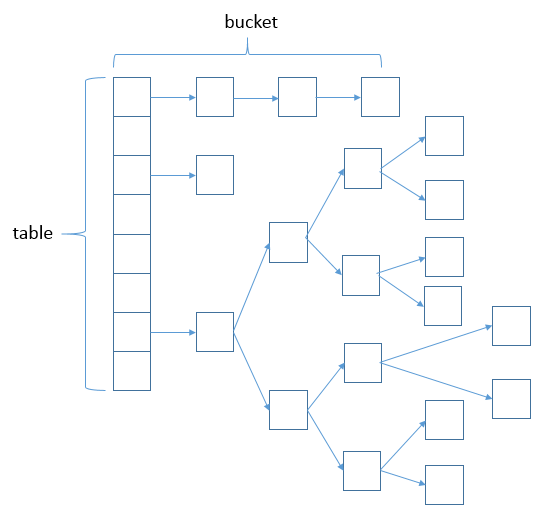
3. TreeNode 方式的HashMap存储结构
普通的Node就是一个单向链表,因此HashMap的结构就是上面哪种
TreeNode是一颗红黑树的结构,所以对上面的图走一下简单的改造,将单向链表改成红黑树即可
3. 添加kv对
博文 JDK容器学习之HashMap (一) : 底层存储结构分析 对于添加kv对的逻辑进行了说明,因此这里将主要集中在数组的扩容上
扩容的条件: 默认扩容加载因子为(0.75),临界点在当HashMap中元素的数量等于table数组长度*加载因子,长度扩为原来的2倍
数组扩容方法, 实现比较复杂,先撸一把代码,并加上必要注释
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; // 持有旧数组的一份引用 int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { // 容量超过上限,直接返回,不用再继续分配 threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) // 新的数组长度设置为原数组长度的两倍 // 新的阀值为旧阀值的两倍, newThr = oldThr << 1; // double threshold } else if (oldThr > 0) { // initial capacity was placed in threshold newCap = oldThr; } else { // 首次初始化 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float) newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { // 下面是将旧数组中的元素,塞入新的数组中 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) { // 若Node节点没有出现hash碰撞,则直接塞入新的数组 newTab[e.hash & (newCap - 1)] = e; } else if (e instanceof TreeNode) { // 对于出现hash碰撞,且红黑树结构时,需要重新分配 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); } else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { // 新的位置相比原来的新增了 oldCap if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { // 位置不变 if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab;}上面的逻辑主要划分为两块
- 新的数组长度确定,并初始化新的数组
- 将原来的数据迁移到新的数组中
- 遍历旧数组元素
- 若Node没有尾节点(Next为null),则直接塞入新的数组
- 判断Node的数据结构,红黑树和链表逻辑有区分
- 对于链表格式,新的坐标要么是原来的位置,要么是原来的位置+原数组长度,链表顺序不变
说明
这个扩容的逻辑还是比较有意思的,最后面给一个测试case,来看一下扩容前后的数据位置
4. 删除元素
删除的逻辑和上面的大致类似,显示确定节点,然后从整个数据结构中移除引用
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; // 删除的前置条件: // 1. 数组已经初始化 // 2. key对应的Node节点存在 if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) { // 数组中的Node节点即为目标 node = p; } else if ((e = p.next) != null) { // hash碰撞,目标可能在链表or红黑树中 // 便利链表or红黑树,确定目标 if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { // 找到目标节点,直接从数组or红黑树or链表中移除 // 不改变Node节点的内容 if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null;}测试
上面的几个常用方法的逻辑大致相同,核心都是在如何找到目标Node节点,其中比较有意思的一点是数组的扩容,旧元素的迁移逻辑,下面写个测试demo来演示一下
首先定义一个Deom对象,覆盖hashCode方法,确保第一次重新分配数组时,正好需要迁移
public static class Demo { public int num; public Demo(int num) { this.num = num; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Demo demo = (Demo) o; return num == demo.num; } @Override public int hashCode() { return num % 3 + 16; }}@Testpublic void testMapResize() { Map<Demo, Integer> map = new HashMap<>(); for(int i = 1; i < 12; i++) { map.put(new Demo(i), i); } // 下面这一行执行,并不会触发resize方法 map.put(new Demo(12), 12); // 执行下面这一行,会触发HashMap的resize方法 // 因为 hashCode值 & 16 == 1,所以新的位置会是原来的位置+16 map.put(new Demo(13), 13);}实际演示示意图
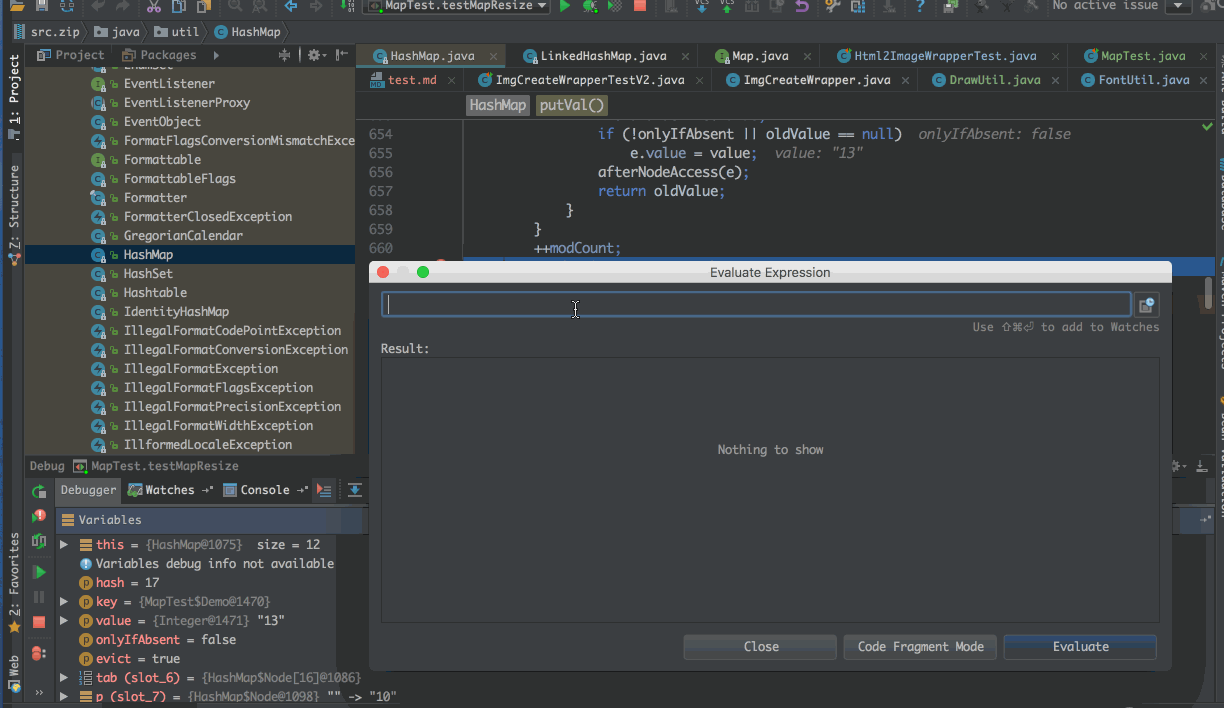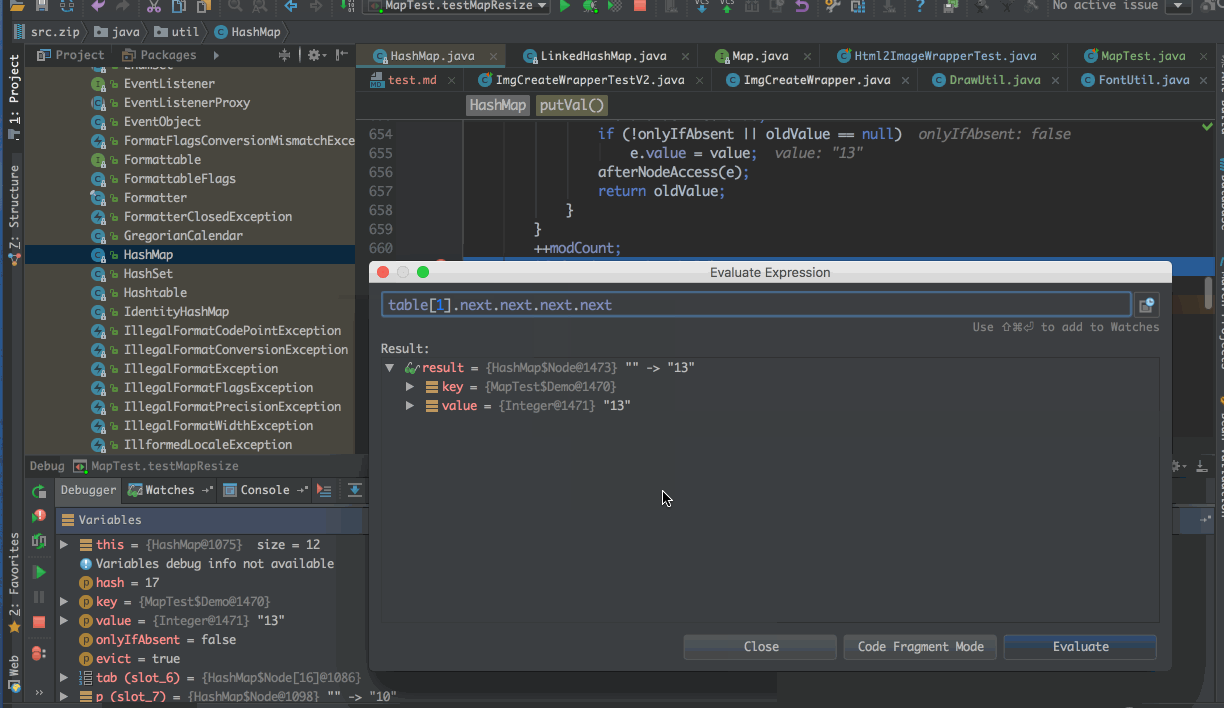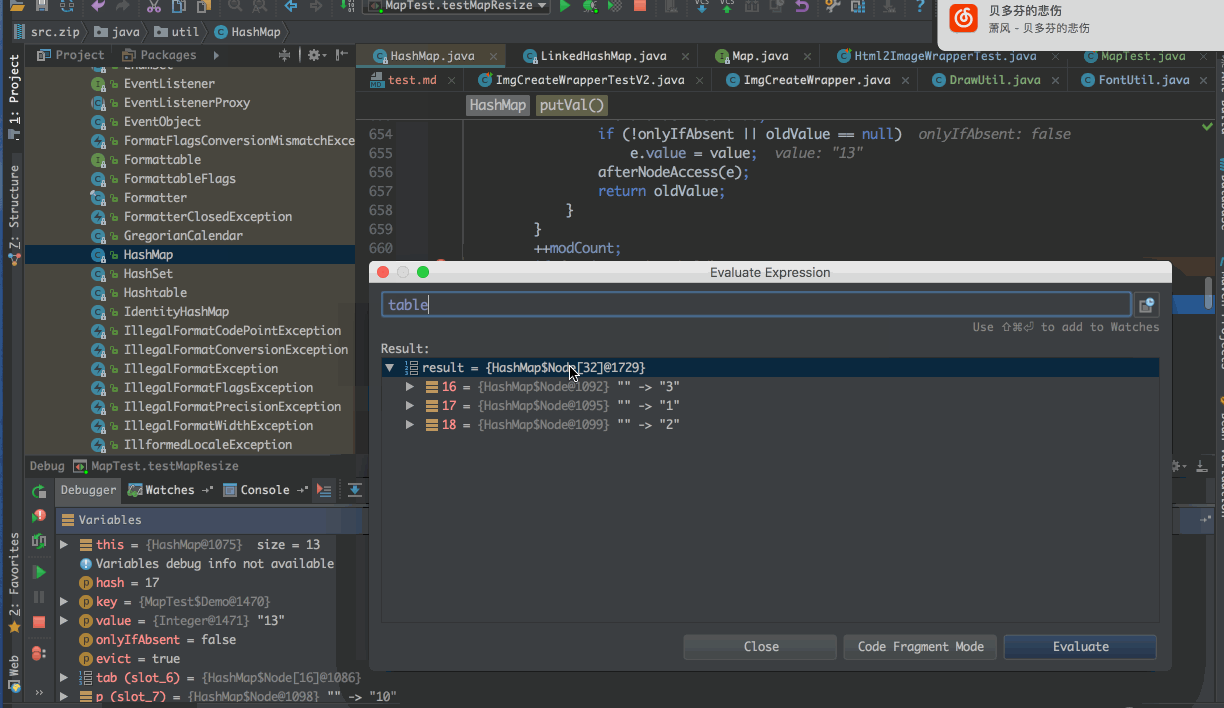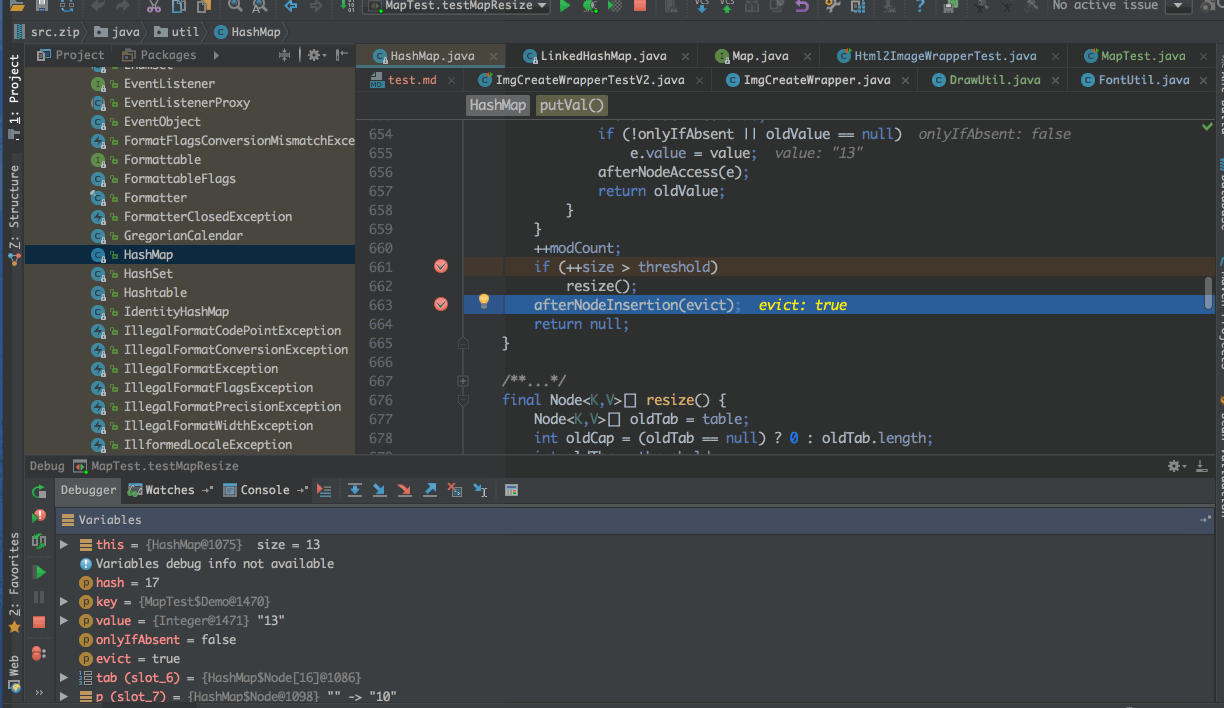
小结
1. 根据Key定位Node节点
- key计算hash,hash值对数组长度取余即为数组中的下标
- 即
hash & (len - 1) === hash % len
- 即
- 以数组中Node为链表头or红黑树根节点遍历,确认目标节点
- 判断逻辑:
- hash值相同
key1 == key2 or key1.quals(key2)
2. 扩容逻辑
- 当添加元素后,数组的长度超过阀值,实现扩容
- 初始容量为16,阀值为12
- 计算新的数组长度,并初始化
- 新的长度为原来的长度 * 2
- 新的阀值为 新的长度 *
loadFactor;loadFactory一般为 0.75
- 将原来的数据迁移到新的数组
- 原位置不变
(hash % 原长度 == 0) - 原位置 + 原数组长度
(hash % 原长度 == 1)
- 原位置不变
3. 其他
- jdk1.8 之后,当链表长度超过阀值(8)后,转为红黑树
- 新增元素,在添加完毕之后,再判断是否需要扩容
- 删除元素不会改变Node对象本身,只是将其从Map的数据结构中 摘 出来
- Map如何退化为链表
- 一个糟糕的hashCode方法即可模拟实现,如我们上面的测试用例
- 红黑树会使这种退化的效果不至于变得那么糟糕
相关博文
- JDK容器学习之HashMap (一) : 底层存储结构分析
关注更多
扫一扫二维码,关注 小灰灰blog

参考
- HashMap 在 JDK 1.8 后新增的红黑树结构
- JDK容器学习之HashMap (二) : 读写逻辑详解
- JDK容器学习之TreeMap (二) : 使用说明
- JDK容器学习之HashMap (三) : 迭代器实现
- JDK容器学习之Map : HashMap,TreeMap,LinkedHashMap对比
- JDK源码学习之HashMap
- C++学习 STL之二:vector容器用法详解
- JDK源码学习之HashMap篇
- JDK源码学习之集合框架HashMap
- JDK容器学习之LinkedHashMap(二):迭代遍历的实现方式
- 【JDK】:HashMap详解
- 顺序容器学习之二
- Java容器之HashMap
- 容器之HashMap浅谈
- JDK源码之-HashMap
- C++学习:list容器详解(二)
- C++学习:list容器详解(二)
- R机器学习之二:逻辑回归
- STL之二:vector容器用法详解
- LeetCode133.Clone Graph
- ucos-iii学习之优先级
- 西瓜书《机器学习》课后答案——chapter5_5.7
- Docker 中 openjdk 容器里无法使用 JDK 的 jmap 等命令的问题
- 给定排好序的数组A,大小为n,现给定数X,判断A中是否存在两数之和等于X
- JDK容器学习之HashMap (二) : 读写逻辑详解
- Python 3.6笔记开篇-------普通变量类型
- P2P原理简介
- CDH5.12.1版本搭建记录
- ros之真实驱动diy6自由度机械臂
- cookie&session(two)
- 运动目标检测算法相关概念
- 解最优化问题
- mybatis TypeHandler处理自定义枚举类型


