样本方差的与方差
来源:互联网 发布:js页面乱码怎么解决 编辑:程序博客网 时间:2024/04/29 07:54
之前做模型拟合的时候需要计算样本的方差和均值,Matlab的std函数算出来就是不对经,一看才知道matlab的给定的标准差计算公式是:
For a random variable vector A made up of N scalar observations, the standard deviation is defined as

where μ is the mean of A:

The standard deviation is the square root of the variance. Some definitions of standard deviation use a normalization factor of N instead of N-1, which you can specify by setting w to 1.
也就是分母除以N-1二不是N了,乖乖,这明显和教科书上定义不一样嘛,于是百度之,最后在知乎上得到一个比较好的解释。
作者:魏天闻
链接:https://www.zhihu.com/question/20099757/answer/26586088
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
上面有答案解释得很明确,即样本方差计算公式里分母为的目的是为了让方差的估计是无偏的。无偏的估计(unbiased estimator)比有偏估计(biased estimator)更好是符合直觉的,尽管有的统计学家认为让mean square error即MSE最小才更有意义,这个问题我们不在这里探讨;不符合直觉的是,为什么分母必须得是
而不是
才能使得该估计无偏。我相信这是题主真正困惑的地方。
要回答这个问题,偷懒的办法是让困惑的题主去看下面这个等式的数学证明:![]() .
.
但是这个答案显然不够直观(教材里面统计学家像变魔法似的不知怎么就得到了上面这个等式)。
下面我将提供一个略微更友善一点的解释。
==================================================================
===================== 答案的分割线 ===================================
==================================================================
首先,我们假定随机变量的数学期望
是已知的,然而方差
未知。在这个条件下,根据方差的定义我们有
![]()
由此可得![]() .
.
因此![]() 是方差
是方差的一个无偏估计,注意式中的分母不偏不倚正好是
!
这个结果符合直觉,并且在数学上也是显而易见的。
现在,我们考虑随机变量的数学期望
是未知的情形。这时,我们会倾向于无脑直接用样本均值
替换掉上面式子中的
。这样做有什么后果呢?后果就是,
如果直接使用![]() 作为估计,那么你会倾向于低估方差!
作为估计,那么你会倾向于低估方差!
这是因为: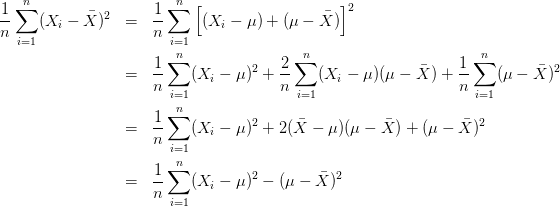
换言之,除非正好,否则我们一定有
![]() ,
,
而不等式右边的那位才是的对方差的“正确”估计!
这个不等式说明了,为什么直接使用![]() 会导致对方差的低估。
会导致对方差的低估。
那么,在不知道随机变量真实数学期望的前提下,如何“正确”的估计方差呢?答案是把上式中的分母换成
,通过这种方法把原来的偏小的估计“放大”一点点,我们就能获得对方差的正确估计了:
![]()
至于为什么分母是而不是
或者别的什么数,最好还是去看真正的数学证明,因为数学证明的根本目的就是告诉人们“为什么”;暂时我没有办法给出更“初等”的解释了。
关于公式的证明:
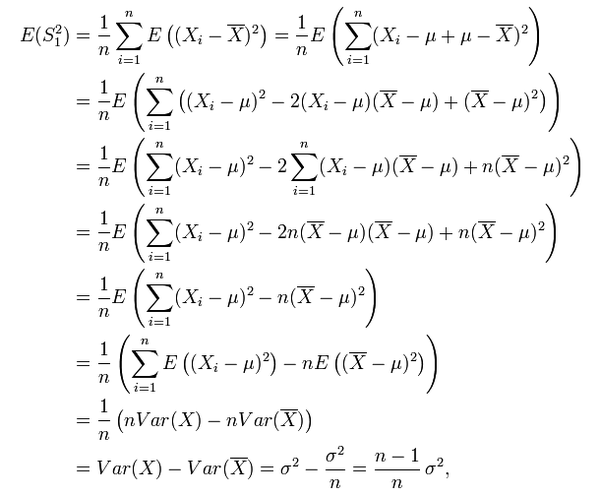
而 (n-1)/n * σ² != σ² ,所以,為了避免使用有 bias 的 estimator,我們通常使用它的修正值 S²: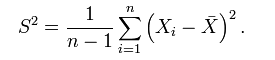
- 样本方差的与方差
- 样本方差与总体方差
- 样本方差与总体方差
- 总体方差与样本方差
- 计算样本数据的方差, 标准方差与协方差
- 方差与样本方差的区别?为什么方差是除以N,样本方差是除以N-1
- 方差与样本方差、协方差与样本协方差
- 概率统计与机器学习:期望,方差,数学期望,样本均值,样本方差之间的区别
- 样本方差公式的说明
- java实现样本方差的计算
- 如何选择样本方差的计算方法
- 样本方差的快速计算-遍历一遍样本集
- 样本方差的无偏估计与(n-1)的由来
- 样本方差的无偏估计与(n-1)的由来
- 样本方差的无偏估计与(n-1)的由来
- 样本方差的无偏估计与(n-1)的由来
- 方差
- 方差
- 仔细检查后链接和流量值
- spark mllib中的随机森林算法,实现源码以及使用介绍
- PreferenceActivity(首选项设置页)
- 在规模为n的数据元素集合中找出最大元
- 【C#】自定义数组默认初始化
- 样本方差的与方差
- 三位数的判断大小
- 【Cumputer】《第一次机房收费系统》总结六 控件MSHFlexGird
- javaweb接口安全校验预备知识——spring aop之 配置方式
- 浅谈CSRF攻击方式
- 转眼又是一年国庆节和中秋节,假日好好休息一下,不想太累!
- css定位
- HDU 1596 find the safest road
- C数据结构-线性表之单链表


