Redis 探究底层存储结构
来源:互联网 发布:网店的营销策略数据 编辑:程序博客网 时间:2024/05/21 19:29
我们都知道Redis有五种数据类型,分别是字符串String,列表List,集合Sort,有序集合Sorted Set和散列表Hash,这些其实是Redis封装好的数据类型,Redis底层是用C语言编写的(大法好),所以用这边博客记录下这五种数据结构的底层是如何实现的。
字符串类型
C语言中字符串都是采用字符数组char[]来实现的,在Redis中是将字符数组封装成一个SDS结构体[Simple Dynamic String],SDS也是Redis的最小存储单元。
我们打开src目录下的sds.h文件
typedef char *sds;/* Note: sdshdr5 is never used, we just access the flags byte directly. * However is here to document the layout of type 5 SDS strings. */struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[];};struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};可以看到分别有8位,16位,32位和64位的sds,他们的内部结构大致都是相同的
- len 记录char[] buf字符数组的长度
- alloc 除去头部和终止符所占的长度
- flags 三种类型 下面会详细说
- buf[] 字符数组
然而仅仅使用封装的字符数组SDS并不能表示所有的五大类型,因此Redis在此之上继续进行封装,所以也就有了下面的RedisObject对象
在server.h中找到了redisObject结构体
#define LRU_BITS 24#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */#define OBJ_SHARED_REFCOUNT INT_MAXtypedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits decreas time). */ int refcount; void *ptr;} robj;可以看到封装的几个属性
- type 表示redisObject是哪种类型
- #define REDIS_STRING 0
- #define REDIS_LIST 1
- #define REDIS_SET 2
- #define REDIS_ZSET 3
- #define REDIS_HASH 4
- *ptr 指针类型 指向的就是SDS类型
因此当我们运行下面的命令
127.0.0.1:6379> set name heqianqianOK127.0.0.1:6379> get name"heqianqian"存储了一个name=”heqianqian”的字符串,这里实际创建了两个redisObject对象,类型都是REDIS_STRING类型,底层的SDS保存的分别就是”name”和”heqianqian”两个字符串了。
一般键都是字符串类型,而值的话就可以有五种类型了
列表类型
Redis的List有点像双端队列,两头都可进可出
看一下adlist.h中是如何定义的
typedef struct listNode { struct listNode *prev; struct listNode *next; void *value;} listNode;typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len;} list;- listNode:有一个前驱节点和一个后继节点,还有一个value指针指向SDS类型
- list
- tail:存放尾节点
- head:存放头节点
- len:列表长度
有这三个属性的话,操作表头表尾和统计长度的时间复杂度都可以是O(1)了

哈希类型
打开dict.h源码
typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */} dict;哈希的底层结构,有五个属性
- dictType
typedef struct dictType { uint64_t (*hashFunction)(const void *key); void *(*keyDup)(void *privdata, const void *key); void *(*valDup)(void *privdata, const void *obj); int (*keyCompare)(void *privdata, const void *key1, const void *key2); void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj);} dictType;- dictht ht[2]
/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used;} dictht;根据注释可以看到是用来表示哈希扩容的,至于这个属性为啥是个两个元素的数组,是因此哈希扩容可以有一次性扩容和渐进性扩容,所谓的渐进性扩容就是扩容的同时不影响前端的CURD,我慢慢的把数据从ht[0]转移到ht[1]中,同时rehashindex来记录转移的情况,当全部转移完成之后,将ht[1]改成ht[0]使用
dictht里也有四个属性
- size:数组大小
- sizemask:用来进行数组取模
- used:记录已使用大小
- dictEntry
dictEntry的结构如下
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next;} dictEntry;有三个属性
key对应哈希表中的键,value对应哈希表中的值。next指针就是使用链表解决哈希冲突
因此哈希结构大概如下所示
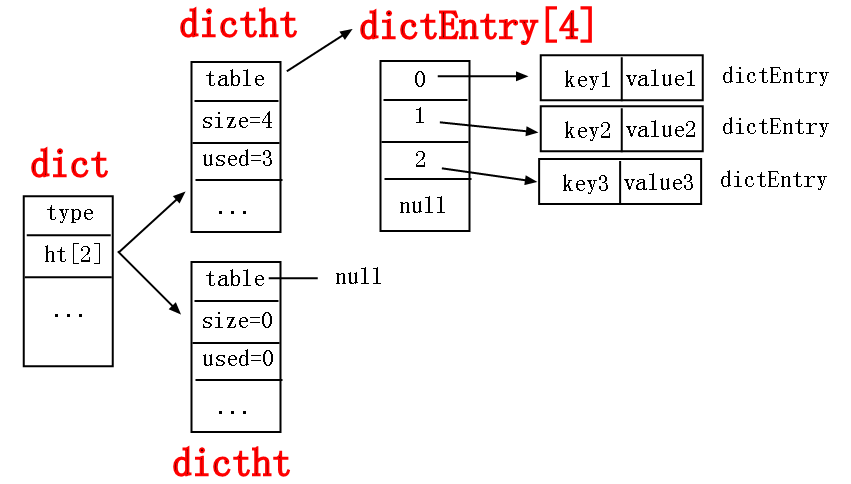
//TODO 待完善
- Redis 探究底层存储结构
- Docker底层存储结构
- Redis 内存存储结构
- Redis之存储结构
- Redis 内存存储结构
- redis的存储结构
- Redis存储结构
- redis存储结构
- iOS的结构体存储内存探究
- SQLServer2012 表IAM存储结构探究
- Redis内存存储结构分析
- Redis内存存储结构分析
- Redis内存存储结构分析
- Redis内存存储结构分析
- Redis内存存储结构分析 .
- Redis内存存储结构分析
- 1 Redis 内存存储结构
- Redis内存存储结构分析
- 95
- 皮尔逊相关度
- 小程序相对于传统推广的优势所在
- LinkedList、ArrayList、 Vector的区别和详解
- LeetCode70.Climbing Stairs
- Redis 探究底层存储结构
- ubuntu 14.04 安装cuda
- OpenCV-将图像缩放并显示
- CircleImageView 圆形imageView(转载)
- 第四周项目5(2)--- 循环双链表应用
- mongodb sparse &unique
- MySQL添加函数或存储过程,步骤
- 斐波那契数
- Linux硬件信息命令大全


