computer vision一些术语-目标识别、目标检测、目标分割、语义分割等
来源:互联网 发布:json和jsonp的区别 编辑:程序博客网 时间:2024/05/17 22:39
转自:http://blog.csdn.net/tina_ttl/article/details/51915618
https://www.zhihu.com/question/36500536
典型的技术路线是:目标分割 ——>目标检测 ——>目标识别 ——>目标跟踪粗略的理解:目标分割:像素级的对前景与背景进行分类,将背景剔除;目标检测:定位目标,确定目标位置及大小;目标识别:定性目标,确定目标是什么;目标跟踪:追踪目标运动轨迹。举个栗子,如:需要对视频中的小明进行跟踪,处理过程将经历如下过程:(1)首先,采集第一帧视频图像,因为人脸部的肤色偏黄,因此可以通过颜色特征将人脸与背景分割出来(目标分割);
(2)分割出来后的图像有可能不仅仅包含人脸,可能还有部分环境中颜色也偏黄的物体,此时可以通过一定的形状特征将图像中所有的人脸准确找出来,确定其位置及范围(目标检测);
(3)接下来需将图像中的所有人脸与小明的人脸特征进行对比,找到匹配度最好的,从而确定哪个是小明(目标识别);
(4)之后的每一帧就不需要像第一帧那样在全图中对小明进行检测,而是可以根据小明的运动轨迹建立运动模型,通过模型对下一帧小明的位置进行预测,从而提升跟踪的效率(目标跟踪)
What is the difference between object detection, semantic segmentation and localization?
object recognition(目标识别)
- 给定一幅图像
- 检测到图像中所有的目标(类别受限于训练集中的物体类别)
- 得到检测到的目标的矩形框,并对所有检测到的矩形框进行分类
Object Recognition: In a given image you have to detect all objects (a restricted class of objects depend on your dataset), Localized them with a bounding box and label that bounding box with a label.

object detection(目标检测)
- 与object recognition目标类似
- 但只有两个类别,只需要找到目标所在的矩形框和非目标矩形框
- 例如,人脸检测(人脸为目标、背景为非目标)、汽车检测(汽车为目标、背景为非目标)
Object Detection: it’s like Object recognition but in this task you have only two class of object classification which means object bounding boxes and non-object bounding boxes. For example Car detection: you have to Detect all cars in a given image with their bounding boxes.


Object Segmentation(目标分割)
- 与object recognition相似,检测到图像中的所有目标
- 但是像素级的,需要给出属于每一类的所有像素点,而不是矩形框

Object Segmentation: Like object recognition you will recognize all objects in an image but your output should show this object classifying pixels of the image.
- object recognition:(多类目标)矩形框+类别
- object detection:(两类目标)矩形框+类别
- Object Segmentation:(多类目标)像素集+类别
Image Segmentation(图像分割)
- 将给定的图像分割为多个区域
- 每个区域为一类,但不需要给出label
Image Segmentation: In image segmentation you will segment regions of the image. your output will not label segments and region of an image that consistent with each other should be in same segment. Extracting super pixels from an image is an example of this task or foreground-background segmentation.

semantic segmentation(语义分割)
- 需要对图像的每一个像素点进行分类
- 这里的类别为:多个目标类别和多个非目标类别
Semantic Segmentation: In semantic segmentation you have to label each pixel with a class of objects (Car, Person, Dog, …) and non-objects (Water, Sky, Road, …). I other words in Semantic Segmentation you will label each region of image.

instance segmentation
- 这个还没懂,待续…..
以下转自:https://www.zhihu.com/question/36500536
------------------------------------------------------------------------------------------------------
链接:https://www.zhihu.com/question/36500536/answer/67939194
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
泻药,我基本同意楼上的答案,但想仔细地定义一下。就像我一贯认为的,对问题进行清楚的定义,往往是最重要的一步。
(1)目标分割,应该是Target Segmentation,应该是data/image segmentation的一种。这里假定数据是图像,就如楼上说的,任务是把目标对应的部分分割出来。对于一般的光学图像而言,分割像素是一个比较常见的目标,就是要提取哪一些像素是用于表述已知目标的。这种Segmentation可以是一个分类(classificatio)问题,就是把每一个pixel做labeling,提出感兴趣的那一类label的像素。也可以是clustering的问题,即是不知道label,但需要满足一些optimality,比如要cluster之间的correlation最小之类的。当然,答主也见过一些针对其他数据的目标分割,比如hyperspectral data,也需要分割哪些频率或者通道对应的是目标。比如视频流,那段时间对应是目标。
下面是一个Target Segmentation的栗子:
<img src="https://pic1.zhimg.com/50/5a767c0f13b253eedb23199b7454d0b4_hd.png" data-rawwidth="602" data-rawheight="337" class="origin_image zh-lightbox-thumb" width="602" data-original="https://pic1.zhimg.com/5a767c0f13b253eedb23199b7454d0b4_r.png">

(2)目标识别,应该是Target Recognition。这是一个基于分类(Classification)的识别(Recognition)问题,即是在所有的给定数据中,分类出哪一些sample是目标,哪一些不是。还是拿图片作为数据举例,这个分类的层面往往不是pixel,给定的一些segment,或者定义的对象(Object),或者图片本身。
下面是一个Target Recognition的栗子:
<img src="https://pic4.zhimg.com/50/7b2f4dcc46920adfef0594343dfce0c3_hd.png" data-rawwidth="1024" data-rawheight="317" class="origin_image zh-lightbox-thumb" width="1024" data-original="https://pic4.zhimg.com/7b2f4dcc46920adfef0594343dfce0c3_r.png">

(3)目标检测,应该是Target Detection。最早的detection system应该是搞雷达的人首先提出并且heavily study的,最简单的任务就是从看似随机(random)又充满干扰(interference)和噪音(noise)的信号中,抓取到有信息的特征(information-bearing pattern)。最简单的一个栗子,就是当你拿到一段随机的雷达回波,可以设置一个threshold,当高于这个threshold,就认为是探测到了高速大面积飞行器之类的高回波的目标。当然,这里面的threshold该怎么设计,涉及到False Alarm和Miss Detection之间的平衡。人们往往需要寻找最佳的transform或者domain去对信号进行分析。
下面是一个Target Detection的栗子:
<img src="https://pic4.zhimg.com/50/ba971eab1ba26ac432f78ccbfb37388b_hd.jpg" data-rawwidth="1045" data-rawheight="1035" class="origin_image zh-lightbox-thumb" width="1045" data-original="https://pic4.zhimg.com/ba971eab1ba26ac432f78ccbfb37388b_r.jpg">
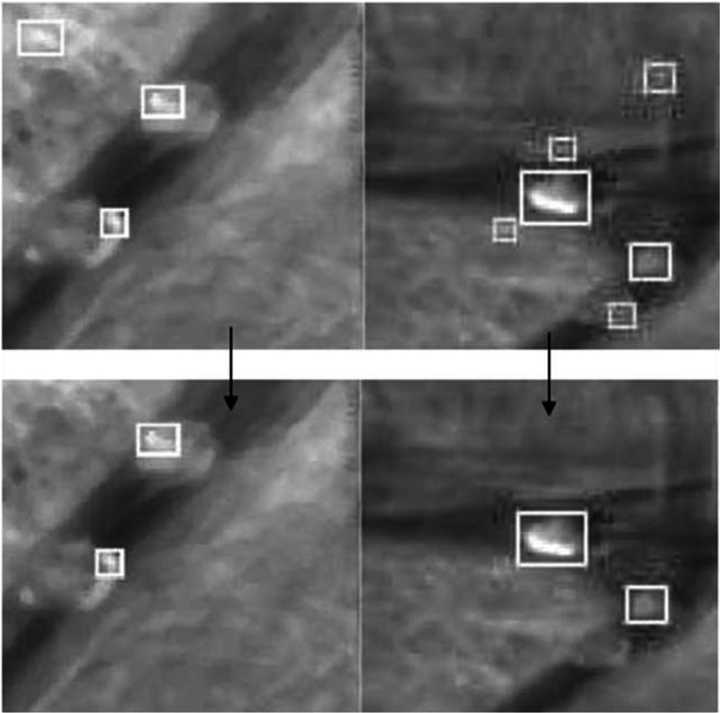
(3)目标追踪,应该是Target Tracking。这个任务很重要的第一点是目标定位(Target Locating),而且这个任务设计到的数据一般具有时间序列(Temporal Data)。常见的情况是首先Target被Identify以后,算法或者系统需要在接下来时序的数据中,快速并高效地对给定目标进行再定位。任务需要区别类似目标,需要避免不要的重复计算,充分利用好时序相关性(Temporal Correlation),并且需要对一些简单的变化Robust,必须旋转,遮盖,缩小放大,Motion Blur之类的线性或者非线性变化。
下面是一个Target Detection的栗子:
<img src="https://pic4.zhimg.com/50/cd89972dcddad9f7e7a9b760d71d7d57_hd.jpg" data-rawwidth="480" data-rawheight="360" class="origin_image zh-lightbox-thumb" width="480" data-original="https://pic4.zhimg.com/cd89972dcddad9f7e7a9b760d71d7d57_r.jpg">

典型的技术路线是:目标分割 ——>目标检测 ——>目标识别 ——>目标跟踪
粗略的理解:
目标分割:像素级的对前景与背景进行分类,将背景剔除;
目标检测:定位目标,确定目标位置及大小;
目标识别:定性目标,确定目标是什么;
目标跟踪:追踪目标运动轨迹。
(1)首先,采集第一帧视频图像,因为人脸部的肤色偏黄,因此可以通过颜色特征将人脸与背景分割出来(目标分割);
(2)分割出来后的图像有可能不仅仅包含人脸,可能还有部分环境中颜色也偏黄的物体,此时可以通过一定的形状特征将图像中所有的人脸准确找出来,确定其位置及范围(目标检测);
(3)接下来需将图像中的所有人脸与小明的人脸特征进行对比,找到匹配度最好的,从而确定哪个是小明(目标识别);
(4)之后的每一帧就不需要像第一帧那样在全图中对小明进行检测,而是可以根据小明的运动轨迹建立运动模型,通过模型对下一帧小明的位置进行预测,从而提升跟踪的效率(目标跟踪)
detection: find all objects (bounding box)
classification: classify objects
recognition: whether one is object
segmentation: cut all objects (pixel wise)
localization: find certain object (bounding box)
识别:预先获得感兴趣图片或者区域,利用机器学习方法进行分类,比如判断物体是苹果还是一本书。应用很多很多。
检测:检测有明确目的性,需要检测什么就去获取样本,然后训练得到模型,最后直接去图像上进行匹配,其实也是识别的过程。
跟踪:它不一定用到模式识别方法,最简单的运动目标时间空间匹配就能实现。当然也能用检测识别方法,这样做速度比较慢一般。
上面每个都有很多深入研究,一言两语就这样了
在图像中有多少个像素属于物体
物体是什么
物体在哪里
物体怎么运动
回答不一定准确
- computer vision一些术语-目标识别、目标检测、目标分割、语义分割等
- computer vision一些术语-目标识别、目标检测、目标分割、语义分割等
- computer vision一些术语-目标识别、目标检测、目标分割、语义分割等
- 图像识别中目标分割、目标识别、目标检测和目标跟踪方法
- 初六-目标检测-分割
- 目标分割、目标识别、目标检测和目标跟踪的区别
- Mask R-CNN(目标检测,语义分割)测试
- 图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么?+资料列表
- CNN-目标检测、定位、分割
- CNN-目标检测、定位、分割
- CNN-目标检测,定位,分割
- CNN-目标检测、定位、分割
- 目标检测分割--Mask R-CNN
- 目标检测分割算法之grabCut
- R-CNN-目标检测、定位、分割
- 目标检测与分割(二):YOLO
- 快速分割目标管道
- 粘边目标分割
- poj2485 highways 之prim解法
- 详解ImageNet 2017夺冠架构SENet
- poj2421 Constructing Roads
- 科技界的看门人—微积分
- select下拉框与input输入框相结合;正则表达式判断字符串是否未日期格式
- computer vision一些术语-目标识别、目标检测、目标分割、语义分割等
- spl 教程四 接口
- 详解vue之vuex
- 自由幻想UI之成就界面
- Html 的小误区
- virtualenv
- 操作系统-死锁
- Number of Islands
- ST表学习


