神经网络与深度学习笔记——神经网络与梯度下降
来源:互联网 发布:如何申请淘宝小号流程 编辑:程序博客网 时间:2024/05/21 10:08
利用神经网络进行手写体识别
两种重要的人工神经网络:感知机,sigmoid神经元。
神经网络标准学习算法:sgd(随机梯度下降)
Perceptrons(感知机)
二进制输入
x1,x2,x3...
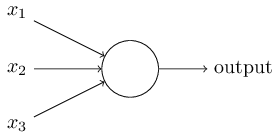
sum=∑jwj∗xj ,其中wj 是对应输入项的权重。
当我们将多个感知机级联起来,能得到一个更加丰富的函数网络,如下:
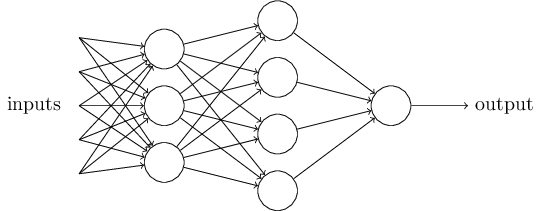
层级的关系,可以使得输入到输出的决策趋于抽象,从而在最终层得出一个抽象层次最高的决策。
当我们将感知机的公式进行简化:
f(wx+b)={0,1,if wx+b≤0if wx+b>0 x= 一条样本输入的行向量,w= 感知机权重的列向量,b=−threshold
感知机不仅可以权衡输入,还能实现电路逻辑函数。
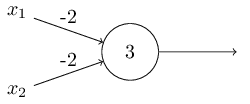
上图实现了nand(与非)逻辑运算。因此感知机网络可以像普通逻辑电路一样实现任意的函数。下图是对
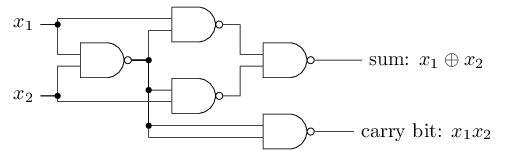
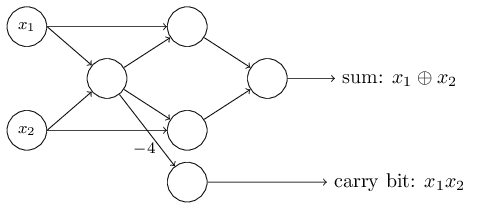
到目前为止,感知机网络似乎就是另一种形式的逻辑电路。但是,利用学习算法,我们可以借助外部的数据刺激,使网络中的参数自动地调整,以得到期望的函数结果。
Sigmoid 神经元
期待的学习算法:对参数进行细微的调整
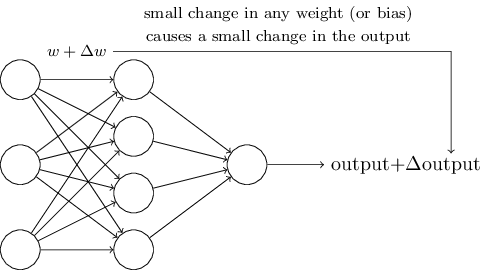
通过上述感知机的定义公式,可以发现,
我们需要一个连续的函数才能获得上述性质。
引入Sigmoid神经元:
形式上与感知机类似,而输入



由于sigmoid函数的连续性,我们可以得到:
性质
1.感知机网络中,w 和b 同时乘以c(c>0),网络的功能不改变。
2.若网络中任一神经元的输入wx+b≠0 ,在输入值x 不变,c→+∞ 的情况下,sigmoid神经网络与原感知机网络功能一致。
f(wx+b)↔f(c(wx+b))↔limc→+∞σ(c(wx+b))
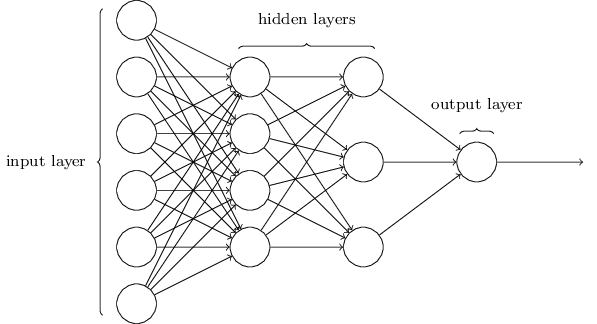
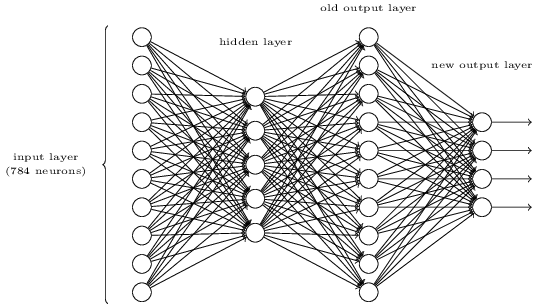
神经网络结构
MLP(sigmoid 神经元):
mnist手写字体识别:
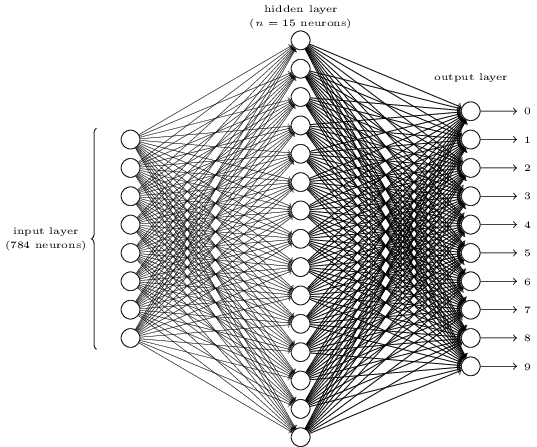
28*28的输入灰度图片
cost函数:均方误差
事实上,10分类仅仅需要4位二进制即可完全表示,但实验显示10个神经元的输出层效果优于4个神经元。这在一定程度上可以理解为神经网络在完成图像识别的基础上完成了一个编码器的工作。
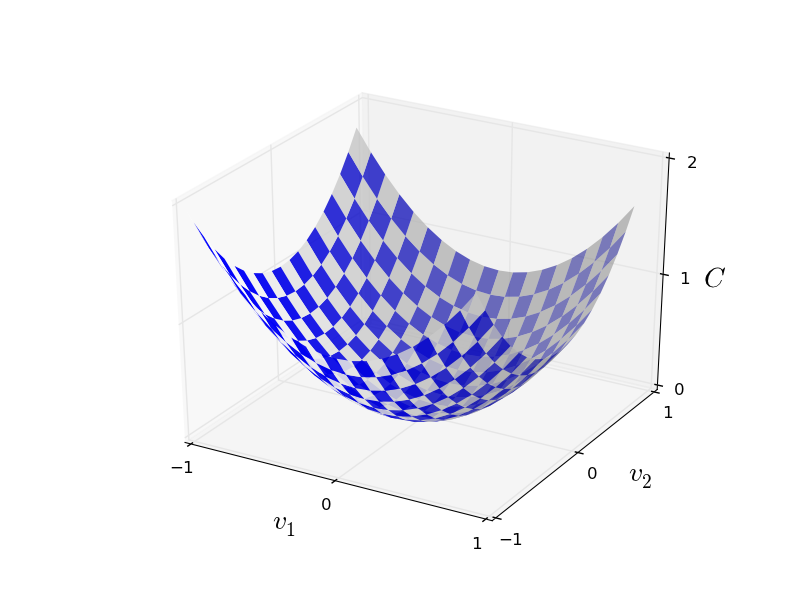
以梯度下降的方式学习
由于自变量数量众多,利用微积分求多元函数的极值方法求解最优值相对复杂,因此需要新的解决方案。
若
由多元函数的微分我们可以得到:
我们似乎能够以偏导数为标准来设定
因此,
当维度推广至多维时,上述迭代仍然成立。另外,梯度方向也是函数变化最快的方向,在相同的步长下,梯度下降是最优的。
由上述
此时,迭代公式如下:
例如训练集大小
- 神经网络与深度学习笔记——神经网络与梯度下降
- 神经网络与深度学习 笔记2 梯度下降
- 神经网络与深度学习笔记(一)梯度下降算法
- 神经网络与深度学习(一)——神经元与梯度下降算法
- 神经网络与深度学习笔记(二)python 实现随机梯度下降
- 神经网络与深度学习(2):梯度下降算法和随机梯度下降算法
- 神经网络与深度学习 1.5 使用梯度下降算法进行学习
- 神经网络:感知机与梯度下降
- 机器学习--神经网络算法系列--梯度下降与随机梯度下降算法
- 神经网络与深度学习笔记——第5章 深度神经网络为何很难训练
- [DeeplearningAI笔记]神经网络与深度学习4.深度神经网络
- 神经网络与深度学习
- 深度学习与神经网络
- 神经网络与深度学习
- 神经网络与深度学习
- 神经网络与深度学习笔记——第1章 使用神经网络识别手写数字
- 神经网络与深度学习笔记——第3章 改进神经网络的学习方法
- 深度学习与神经网络-吴恩达-第一周 梯度检查
- Oracle与mysql批量新增或修改语法
- 转载:数据库的并发控制技术深度探索
- 1005. 继续(3n+1)猜想 (25)
- Github设置添加SSH
- cf556d set<node>操作
- 神经网络与深度学习笔记——神经网络与梯度下降
- 图灵奖得主姚期智最新论文出炉!中秋人家看月亮,AI人看论文
- Hibernate的核心类和接口
- 5 Ways To Boost Typing Speed And Accuracy
- Python 窗体(tkinter)输入文本框(entry)
- 线性单元
- CentOS常用命令
- 树的遍历
- 3.基础类


