卷积神经网络应用:基于Tensorflow的CNN/CRF图像分割技术
来源:互联网 发布:nginx php 500错误 编辑:程序博客网 时间:2024/05/19 10:37
卷积神经网络应用:基于Tensorflow的CNN/CRF图像分割技术
Image TensorFlow 卷积神经网络 条件随机场 后处理 图像分割 上采样
摘要: 本篇文章验证了卷积神经网络应用于图像分割领域时存在的一个问题——粗糙的分割结果。根据像素间交叉熵损失的定义,我们在简化的场景下进行了模型的训练,并使用后向传播来更新权重。我们使用条件随机场(CRFs)来解决分割结果粗糙的问题,并取得了很好的效果。本文中的代码注释详细、功能完善,也便于读者阅读。
这是一篇翻译文章。介绍了一种基于最近发布的TF-Slim库与预训练模型来进行图像分割的方法。本篇文章的内容包括基于条件随机场的模型训练与后处理过程。
引言
在之前的文章中,我们实现了上采样操作,并通过将其与scikit-image库中的对应实现作比较,以确保上采样过程的正确性。更具体地说,我们实现了论文《Fully convolutional networks for semantic segmentation》中描述的FCN-32分割网络。
在本篇文章中,我们将进行一个简单的训练:我们将从PASCAL VOC数据集中选取一张样本图像以及它的标注信息,基于样本图像与标注训练来我们的网络,并在同样的图像上测试我们训练好的网络。之所以这样做,是因为这样我们就可以使用CPU来训练模型——只需要10次迭代就能完成训练。本篇文章的另一个目的在于,证明我们这个网络(FCN-32s)的分割结果是很粗糙的——即使在用于训练的图像上进行分割,结果也同样如此。在本篇文章中,我们使用条件随机场的后处理阶段来解决这个问题,其综合考虑图像中的RGB纯色特征以及模型输出的预测概率,进而改善图像的分割效果。总的来说,我们得到了改善后的分割结果。我们刻意在文章中使用了非常简单的训练环境。类似的分割方法在Chen等人发表的论文《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》中也有所提及。请注意,本篇文章中的训练环境仅为了说明FCN-32s模型的局限,如果要在真实场景中进行训练,我们建议读者参考这篇论文《Fully convolutional networks for semantic segmentation》。
本篇文章使用Jupyter Notebook创建。在每个代码块后,你可以看到模型的评估结果。你也可以从这里获得本文对应的笔记文档。本篇文章的部分内容也借鉴了TF-Slim库的演示教程。
准备阶段
为了运行下面的代码,你需要安装Tensorflow。我使用的版本是r0.12。你可能需要使用Tensorflow的这个分支。
在这篇教程中,我也使用了scikit-imag库、numpy以及其他的一些依赖。你可以通过下载Anaconda的Python软件包来安装这些软件。
此外,你还需要按照之前几篇文章介绍的步骤来配置你的训练环境——包括如何下载VGG-16模型以及其他所有的必需操作。
上采样辅助函数与图像加载
在这一部分中,我们定义前一篇文章使用的辅助函数。如果你还记得的话,我们使用了上采样技术对我们从网络中获得的下采样预测结果进行采样。我们从VGG-16模型使用的最大值池化层中获得模型的下采样预测结果。
我们也为图像与各个实际分割区域的加载操作编写了程序。这些代码加入了足够的注释,所以不必担心无法理解它。
import numpy as npdef get_kernel_size(factor): """ 给定所需的上采样因子,确定卷积核的大小 """ return 2 * factor - factor % 2def upsample_filt(size): """ 创建一个给定(h, w) 大小的适用于上采样过程的二维双线性卷积核 """ factor = (size + 1) // 2 if size % 2 == 1: center = factor - 1 else: center = factor - 0.5 og = np.ogrid[:size, :size] return (1 - abs(og[0] - center) / factor) * \ (1 - abs(og[1] - center) / factor)def bilinear_upsample_weights(factor, number_of_classes): """ 使用双线性卷积核,为转置卷积创建权重矩阵 初始化 """ filter_size = get_kernel_size(factor) weights = np.zeros((filter_size, filter_size, number_of_classes, number_of_classes), dtype=np.float32) upsample_kernel = upsample_filt(filter_size) for i in xrange(number_of_classes): weights[:, :, i, i] = upsample_kernel return weights%matplotlib inlinefrom __future__ import divisionimport osimport sysimport tensorflow as tfimport skimage.io as ioimport numpy as npos.environ["CUDA_VISIBLE_DEVICES"] = '1'sys.path.append("/home/dpakhom1/workspace/my_models/slim/")checkpoints_dir = '/home/dpakhom1/checkpoints'image_filename = 'cat.jpg'annotation_filename = 'cat_annotation.png'image_filename_placeholder = tf.placeholder(tf.string)annotation_filename_placeholder = tf.placeholder(tf.string)is_training_placeholder = tf.placeholder(tf.bool)feed_dict_to_use = {image_filename_placeholder: image_filename, annotation_filename_placeholder: annotation_filename, is_training_placeholder: True}image_tensor = tf.read_file(image_filename_placeholder)annotation_tensor = tf.read_file(annotation_filename_placeholder)image_tensor = tf.image.decode_jpeg(image_tensor, channels=3)annotation_tensor = tf.image.decode_png(annotation_tensor, channels=1)# 对于每个类别,将其设置为1而不是一个数字——我们在后续计算# 交叉熵时会用到。有的时候,实际分割区域的掩码可以有很多值,# 不仅仅为0和1class_labels_tensor = tf.equal(annotation_tensor, 1)background_labels_tensor = tf.not_equal(annotation_tensor, 1)#将布尔值转换为浮点数——这样才能正确地计算交叉熵损失bit_mask_class = tf.to_float(class_labels_tensor)bit_mask_background = tf.to_float(background_labels_tensor)combined_mask = tf.concat(concat_dim=2, values=[bit_mask_class, bit_mask_background])# 调整输入数据的大小,使其与tf.softmax_cross_entropy_with_logits中# [batch_size, num_classes]的要求保持一致flat_labels = tf.reshape(tensor=combined_mask, shape=(-1, 2))损失函数定义与基于Adam优化算法的训练
在这一部分中,我们把准备好的所有东西整合到一起:为我们的网络添加上采样层,定义可微分求导的损失函数,并进行模型的训练。
参照论文《Fully convolutional networks for semantic segmentation》,我们将模型的损失定义为像素间的交叉熵。我们之所以这样定义,是因为在上采样后我们可以得到与输入图像尺寸相同的预测结果,进而我们可以将获得的分割结果与实际的各个分割区域进行比较:
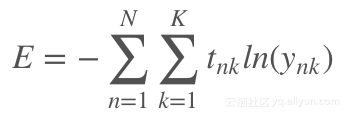
其中,N表示像素的数量,K表示类别的数量,变量Tnk表示第n个像素对应的实际分割区域,实际区域以1至K的数字表示,变量Ynk为我们模型的预测结果(使用softmax函数来规范输出)。
对于这种情况,由于Adam优化器仅调整较少的参数就能使模型取得很好的效果,我们将其应用到了模型的训练当中。
在这个特殊的情况下,我们使用一张图像来训练模型并评估模型的效果——与真实场景相比,这种训练方式非常简单。我们这样做是为了展示这种方法的不足——只为了说明这种方法糟糕的定位能力。如果在这种简单场景下这种方法的效果尚且如此,那么在未训练的图像上,这种方法只会产生类似的更糟糕的结果。
import numpy as npimport tensorflow as tfimport sysimport osfrom matplotlib import pyplot as pltfig_size = [15, 4]plt.rcParams["figure.figsize"] = fig_sizeimport urllib2slim = tf.contrib.slimfrom nets import vggfrom preprocessing import vgg_preprocessing# 加载像素均值以及为每个像素进行减法运算的函数from preprocessing.vgg_preprocessing import (_mean_image_subtraction, _R_MEAN, _G_MEAN, _B_MEAN)upsample_factor = 32number_of_classes = 2log_folder = '/home/dpakhom1/tf_projects/segmentation/log_folder'vgg_checkpoint_path = os.path.join(checkpoints_dir, 'vgg_16.ckpt')# 在与像素均值做差前,将图像转换至float32类型image_float = tf.to_float(image_tensor, name='ToFloat')# 将每个像素的具体数值与像素均值做差mean_centered_image = _mean_image_subtraction(image_float, [_R_MEAN, _G_MEAN, _B_MEAN])processed_images = tf.expand_dims(mean_centered_image, 0)upsample_filter_np = bilinear_upsample_weights(upsample_factor, number_of_classes)upsample_filter_tensor = tf.constant(upsample_filter_np)# 定义将要使用的模型——指定在最后一层仅使用两个类别with slim.arg_scope(vgg.vgg_arg_scope()): logits, end_points = vgg.vgg_16(processed_images, num_classes=2, is_training=is_training_placeholder, spatial_squeeze=False, fc_conv_padding='SAME')downsampled_logits_shape = tf.shape(logits)# 计算上采样数据的输出大小upsampled_logits_shape = tf.pack([ downsampled_logits_shape[0], downsampled_logits_shape[1] * upsample_factor, downsampled_logits_shape[2] * upsample_factor, downsampled_logits_shape[3] ])# 进行上采样处理upsampled_logits = tf.nn.conv2d_transpose(logits, upsample_filter_tensor, output_shape=upsampled_logits_shape, strides=[1, upsample_factor, upsample_factor, 1])# 展开预测结果,以便于我们计算每个像素的交叉熵,并获得交叉熵的总和flat_logits = tf.reshape(tensor=upsampled_logits, shape=(-1, number_of_classes))cross_entropies = tf.nn.softmax_cross_entropy_with_logits(logits=flat_logits, labels=flat_labels)cross_entropy_sum = tf.reduce_sum(cross_entropies)# 获得每个像素的最终预测结果——请注意,在这种情况下我们并不需要# 使用softmax,因为我们只需要得到最终的决策。如果我们还需要各# 个类别的概率,那么我们必须应用softmaxpred = tf.argmax(upsampled_logits, dimension=3)probabilities = tf.nn.softmax(upsampled_logits)# 在这里我们定义了一个优化器,并添加了所有将要创建至命名# 空间'adam_vars'下的变量。这样做有利于我们后续轻松地访问# 它们。这些变量供adam优化器使用,并且与vgg模型中的变量无关# 我们还获得了每个变量的梯度数据# 这样,我们可以在tensorboard中可视化这些变量# optimizer.compute_gradients与optimizer.apply_gradients# 等价于执行:# train_step = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(cross_entropy_sum)with tf.variable_scope("adam_vars"): optimizer = tf.train.AdamOptimizer(learning_rate=0.0001) gradients = optimizer.compute_gradients(loss=cross_entropy_sum) for grad_var_pair in gradients: current_variable = grad_var_pair[1] current_gradient = grad_var_pair[0] # 替换原始变量名中的一些字符 # tensorboard不支持':'符号 gradient_name_to_save = current_variable.name.replace(":", "_") # 得到每一层的梯度直方图,并随后在tensorboard中可视化这些数据 tensorboard tf.summary.histogram(gradient_name_to_save, current_gradient) train_step = optimizer.apply_gradients(grads_and_vars=gradients)# 在这里,我们定义了一个函数,调用时会从VGG模型检查点中读取权重数据,并加载至变量中。# 我们从负责类别预测的最后一层中剔除了权重。我们这样做是因为我们将有不同数量的# 类别进行预测,我们不能在初始化时使用原先的类别。vgg_except_fc8_weights = slim.get_variables_to_restore(exclude=['vgg_16/fc8', 'adam_vars'])# 这里我们得到了网络中最后一层的权重变量# 正如我们看到的,VGG最初训练的类别数量与我们实际的类别数量# 并不相同——在我们的情况下,总共只有两类vgg_fc8_weights = slim.get_variables_to_restore(include=['vgg_16/fc8'])adam_optimizer_variables = slim.get_variables_to_restore(include=['adam_vars'])# 为模型损失添加一个summary OP——以便我们可以在tensorboard中看到它tf.summary.scalar('cross_entropy_loss', cross_entropy_sum)# 将所有summary OP合并至一个OP总# 在运行程序时生成字符串merged_summary_op = tf.summary.merge_all()# 创建一个summary writer——用于将所有日志写入到一个特定文件中# 这个文件后续可以由tensorboard读取summary_string_writer = tf.summary.FileWriter(log_folder)# 如果日志文件夹尚未存在,则创建一个新的文件夹if not os.path.exists(log_folder): os.makedirs(log_folder)# 创建一个OP,对VGG模型中各权重变量进行初始化操作read_vgg_weights_except_fc8_func = slim.assign_from_checkpoint_fn( vgg_checkpoint_path, vgg_except_fc8_weights)# 针对新的fc8层权重数据的初始化器——仅包括两类vgg_fc8_weights_initializer = tf.variables_initializer(vgg_fc8_weights)# adam变量的初始化器optimization_variables_initializer = tf.variables_initializer(adam_optimizer_variables)with tf.Session() as sess: # 运行初始化器 read_vgg_weights_except_fc8_func(sess) sess.run(vgg_fc8_weights_initializer) sess.run(optimization_variables_initializer) train_image, train_annotation = sess.run([image_tensor, annotation_tensor], feed_dict=feed_dict_to_use) f, (ax1, ax2) = plt.subplots(1, 2, sharey=True) ax1.imshow(train_image) ax1.set_title('Input image') probability_graph = ax2.imshow(np.dstack((train_annotation,)*3)*100) ax2.set_title('Input Ground-Truth Annotation') plt.show() # 执行10次迭代 for i in range(10): loss, summary_string = sess.run([cross_entropy_sum, merged_summary_op], feed_dict=feed_dict_to_use) sess.run(train_step, feed_dict=feed_dict_to_use) pred_np, probabilities_np = sess.run([pred, probabilities], feed_dict=feed_dict_to_use) summary_string_writer.add_summary(summary_string, i) cmap = plt.get_cmap('bwr') f, (ax1, ax2) = plt.subplots(1, 2, sharey=True) ax1.imshow(np.uint8(pred_np.squeeze() != 1), vmax=1.5, vmin=-0.4, cmap=cmap) ax1.set_title('Argmax. Iteration # ' + str(i)) probability_graph = ax2.imshow(probabilities_np.squeeze()[:, :, 0]) ax2.set_title('Probability of the Class. Iteration # ' + str(i)) plt.colorbar(probability_graph) plt.show() print("Current Loss: " + str(loss)) feed_dict_to_use[is_training_placeholder] = False final_predictions, final_probabilities, final_loss = sess.run([pred, probabilities, cross_entropy_sum], feed_dict=feed_dict_to_use) f, (ax1, ax2) = plt.subplots(1, 2, sharey=True) ax1.imshow(np.uint8(final_predictions.squeeze() != 1), vmax=1.5, vmin=-0.4, cmap=cmap) ax1.set_title('Final Argmax') probability_graph = ax2.imshow(final_probabilities.squeeze()[:, :, 0]) ax2.set_title('Final Probability of the Class') plt.colorbar(probability_graph) plt.show() print("Final Loss: " + str(final_loss))summary_string_writer.close()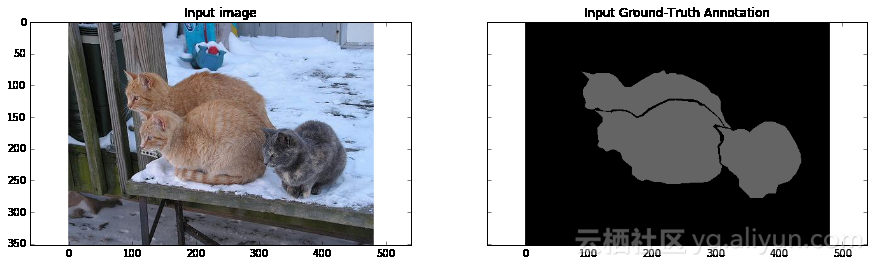
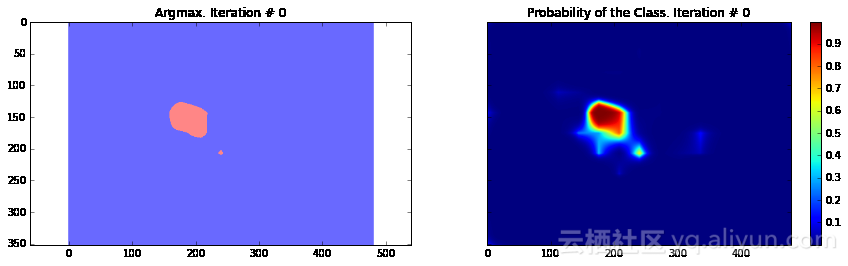
Current Loss: 201433.0
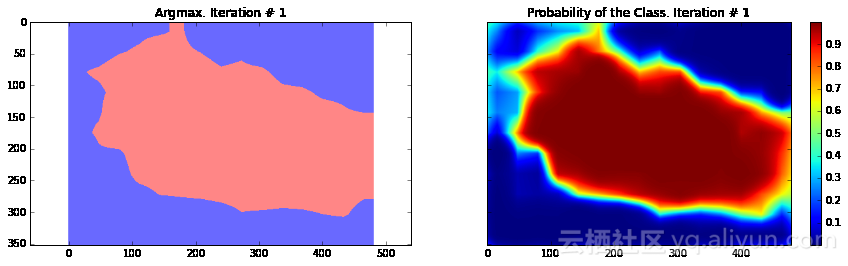
Current Loss: 245565.0
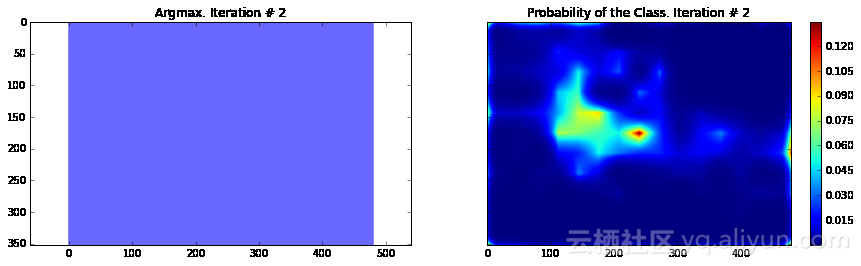
Current Loss: 135906.0
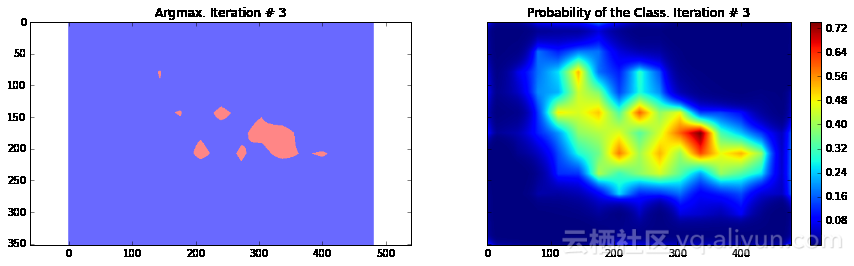
Current Loss: 183353.0
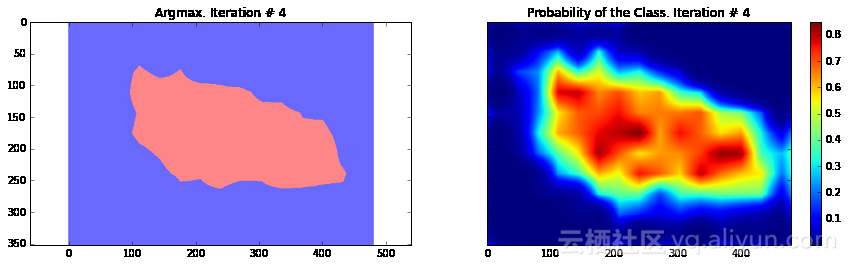
Current Loss: 48563.9
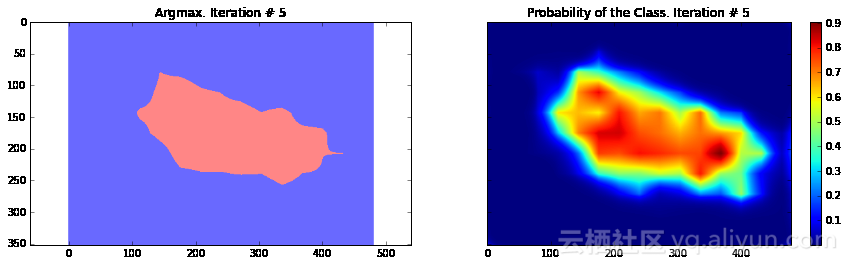
Current Loss: 37925.8
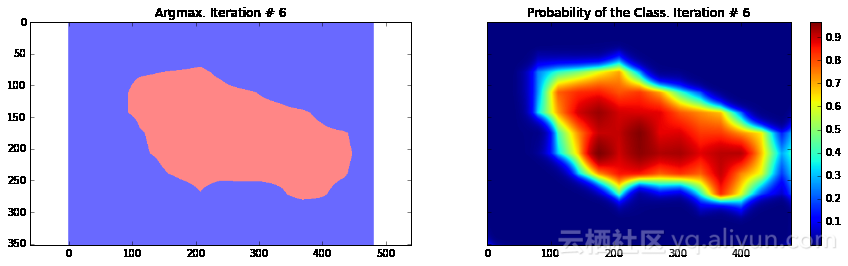
Current Loss: 33199.1
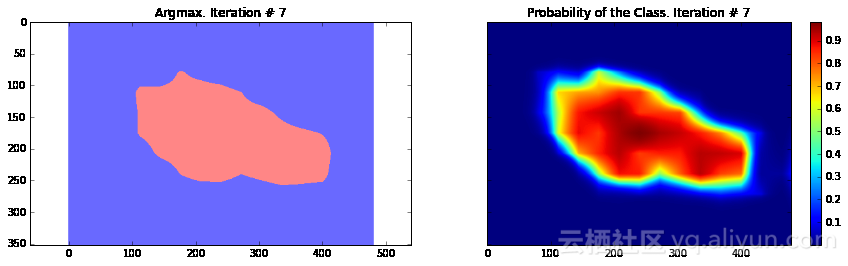
Current Loss: 26540.3
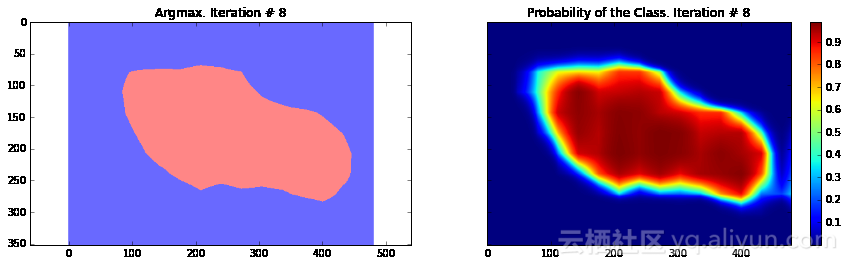
Current Loss: 23658.0
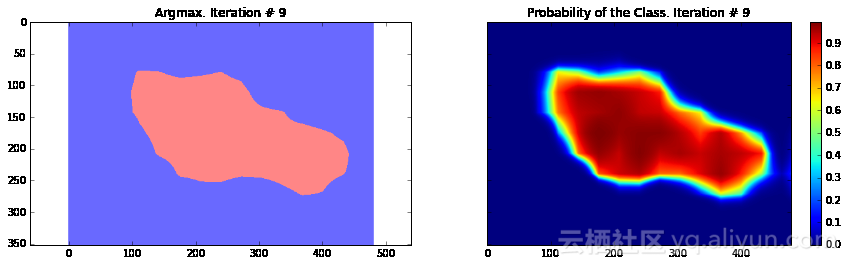
Current Loss: 29404.9
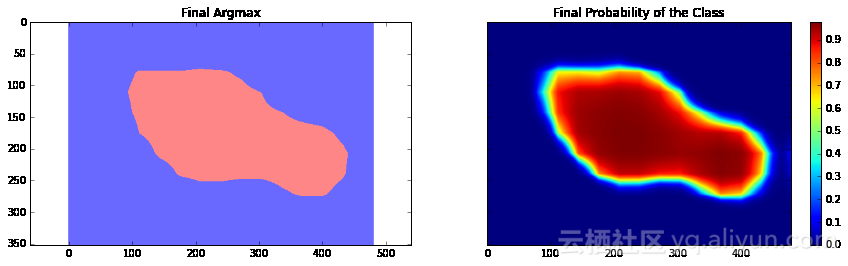
Final Loss: 18177.5
正如你所看到的,结果非常粗糙——而且,这还是我们使用模型训练同一张图像来运行网络预测的结果。这在图像分割中一个非常常见的问题——分割结果通常很粗糙。有几种不同的方法可以解决此类问题——其中之一便是使用跳跃连接。主要思路是根据融合网络中不同层的预测结果来确定模型的最终预测结果。由于在网络较靠前的层次中下采样因子较小,所以,可以根据这些层来确定预测结果,进而取得更好的定位效果。Long等人发表的论文《Fully convolutional networks for semantic segmentation》介绍了这种方法。基于这种方法,研究人员设计了FCN-16s与FCN-8s架构。
另一种方法则基于带孔卷积与全连接条件随机场。Chen等人发表的论文《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》介绍了这种方法。在本篇文章中,我们将仅使用条件随机场后处理阶段来展示它对模型效果的提高。
还有一点需要注意的是,当前模型训练时在全连接层(我们映射到卷积层的全连接层)中应用了Dropout技术,这种方法在Srivastava等人发表的论文《Dropout: a simple way to prevent neural networks from overfitting》中有所提及。Dropout是一种用于模型训练的正则化技术。它有一个非常优秀的理论描述,而且实现起来也非常简单:我们只需要在每个训练步骤中随机地选择一定数量的神经元,仅根据这些神经元来进行推断并后向传播。但是,从理论角度来看,Dropout可以看作是通过权重共享来训练一个稀疏网络的集合,每个网络仅进行很少次数的训练。在测试阶段,我们对所有这些网络的预测结果求均值。在论文中作者表明,Dropout在线性回归情况下预期能够取得与岭回归相同的效果。在我们的具体情况中,Dropout仅用于全连接层(我们映射到卷积层的全连接层)。这也解释了为什么最终模型的损失几乎比最后一次迭代的损失小了两倍——因为在最后的推断中,我们使用了损失的均值。
上面提供的代码用于处理单张图像,但你可以很容易地在整个数据集上运行这些程序。唯一需要调整的是,在每个迭代步骤中提供不同的图像。这种训练方式与论文《Fully convolutional networks for semantic segmentation》的做法完全一致,其中,论文作者采用了数量为1的批处理进行训练。
总的来说,我们可以看到我们的分割结果仍然很粗糙,需要执行一些额外的处理步骤。在下一节,我们将应用条件随机场的后处理步骤使模型的分割粒度更细。
条件随机场后处理
条件随机场是图模型的一种特定类型。在我们的应用场景中,条件随机场有助于根据网络的预测以及图像原生的RGB特征估计模型预测结果的后验分布。它通过最小化用户定义的能量函数来实现这一点。在我们的应用场景中,其效果与双边滤波器非常接近,双边滤波器综合考虑了图像中像素的空间邻近性以及在RGB特征空间(强度空间)中的相似性。
在一个非常简单的层面上,这种方法使用RGB特征来使图像分割结果更加精准——例如,边界通常表示为极大的强度变化——这是一个关键因素,位于该边界两侧的物体属于不同的类别。这种方法也同样对小的分割区域进行惩罚——例如,20像素或50像素大小的小区域通常不可能是一个正确的分割区域。物体通常由大的空间相邻的区域表示。
下面你可以看到这个后处理步骤是如何影响我们的分割结果的。我们使用了论文《fully connected crfs with gaussian edge potentials》有效性推断章节中描述的全连接条件随机场对分割结果进行调整。
在这部分中,我使用了一个版本稍微有些老的全连接条件随机场的实现,你可以在这里找到它。
import syspath = "/home/dpakhom1/dense_crf_python/"sys.path.append(path)import pydensecrf.densecrf as dcrffrom pydensecrf.utils import compute_unary, create_pairwise_bilateral, \ create_pairwise_gaussian, softmax_to_unaryimport skimage.io as ioimage = train_imagesoftmax = final_probabilities.squeeze()softmax = processed_probabilities.transpose((2, 0, 1))# 输入数据应为概率值的负对数# 你可以在softmax_to_unary函数的定义中找到更多信息unary = softmax_to_unary(processed_probabilities)# 输入数据应为C-连续的——我们使用了Cython封装器unary = np.ascontiguousarray(unary)d = dcrf.DenseCRF(image.shape[0] * image.shape[1], 2)d.setUnaryEnergy(unary)# 潜在地对空间上相邻的小块分割区域进行惩罚——促使产生更多空间连续的分割区域feats = create_pairwise_gaussian(sdims=(10, 10), shape=image.shape[:2])d.addPairwiseEnergy(feats, compat=3, kernel=dcrf.DIAG_KERNEL, normalization=dcrf.NORMALIZE_SYMMETRIC)# 这将创建与颜色相关的图像特征——因为我们从卷积神经网络中得到的分割结果非常粗糙,# 我们可以使用局部的颜色特征来改善分割结果feats = create_pairwise_bilateral(sdims=(50, 50), schan=(20, 20, 20), img=image, chdim=2)d.addPairwiseEnergy(feats, compat=10, kernel=dcrf.DIAG_KERNEL, normalization=dcrf.NORMALIZE_SYMMETRIC)Q = d.inference(5)res = np.argmax(Q, axis=0).reshape((image.shape[0], image.shape[1]))cmap = plt.get_cmap('bwr')f, (ax1, ax2) = plt.subplots(1, 2, sharey=True)ax1.imshow(res, vmax=1.5, vmin=-0.4, cmap=cmap)ax1.set_title('Segmentation with CRF post-processing')probability_graph = ax2.imshow(np.dstack((train_annotation,)*3)*100)ax2.set_title('Ground-Truth Annotation')plt.show()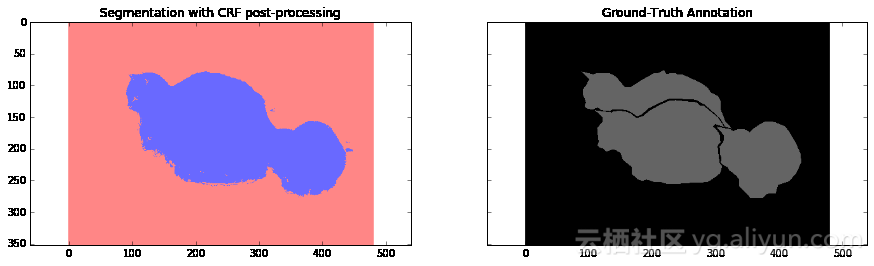
结论与讨论
在本篇教程中,我们看到了卷积神经网络应用于图像分割领域时的一个缺陷——粗糙的分割结果。我们可以看到,这种情况是由于在VGG-16网络架构中使用最大值池化层所导致的。
根据像素间交叉熵损失的定义,我们在简化的场景下进行了模型的训练,并使用后向传播来更新权重。
我们使用条件随机场(CRFs)来解决分割结果粗糙的问题,并取得了很好的效果。
以下为译文
**本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
原标题《Image Segmentation with Tensorflow using CNNs and Conditional Random Fields》,作者:Daniil,译者:6816816151**
文章为简译,更为详细的内容,请查看原文
- 卷积神经网络应用:基于Tensorflow的CNN/CRF图像分割技术
- 基于卷积神经网络的图像语义分割
- 【TensorFlow】TensorFlow 的卷积神经网络 CNN
- tensorflow CNN卷积神经网络
- tensorflow CNN卷积神经网络
- 用于图像分割的卷积神经网络:从R-CNN到Mask R-CNN
- 卷积神经网络应用之图像分割
- TensorFlow实现卷积神经网络CNN
- TensorFlow学习--卷积神经网络CNN
- TensorFlow搭建CNN卷积神经网络
- TensorFlow实现卷积神经网络CNN
- TensorFlow -- 实现CNN卷积神经网络
- 【TensorFlow】TensorFlow 的卷积神经网络 CNN - 无TensorBoard版
- FCN(全卷积神经网络)+CRF+分割图
- TensorFlow在MNIST中的应用-卷积神经网络CNN
- 卷积神经网络LeNet5,基于TensorFlow的实现
- 卷积神经网络在图像分割中的进化史:从R-CNN到Mask R-CNN
- 【Tensorflow】实现简单的卷积神经网络CNN实际代码
- 欢迎使用CSDN-markdown编辑器
- 顺序链表 : 在任意位置添加节点
- ubuntu下安装docker-compose
- Android studio 默认安装路径
- html的jQuery判断格式和从文本框获取信息放入表格
- 卷积神经网络应用:基于Tensorflow的CNN/CRF图像分割技术
- 关于同步异步、阻塞非阻塞的一些回答(简明扼要,准确精辟)
- 单源最短路(dijkstra)
- 横向滑动
- VLC RTSP视频播放终极解决方案
- JavaScript 隐式转换
- 1、JQuery——选择器
- C++ 对象模型--1小窥
- vue中关于computed的理解及其其他扩展


