R语言中的初等数学计算
来源:互联网 发布:2015休闲食品销售数据 编辑:程序博客网 时间:2024/05/22 14:20
前言
1.大部分参考张丹(Conan)的R的极客理想系列文章《R语言中的数学计算》,对此表示感谢。
(http://blog.fens.me/r-mathematics/)
2.补充、解释和学习,记录并便于今后的查询。
目录
- 基本计算
- 三角函数计算
- 复数计算
- 方程计算
一、基本计算
(一)、四则运算: 加减乘除、余数、整除、绝对值、判断正负
(1)判断正负
> sign(-2:3)[1] -1 -1 0 1 1 1#sign函数用以判断数值型向量的正负,0表示向量为0,-1表示向量为负,+1表示向量为正(二)、数学计算: 幂、自然常数e的幂、平方根和对数
> a<-10;b<-5;c<-4(1)幂
> c^b;c^-b;c^(b/10)[1] 1024[1] 0.0009765625[1] 2(2)自然常数e
> exp(1)[1] 2.718282(3)自然常数e的幂
> exp(3)[1] 20.08554(4)平方根
> sqrt(c)[1] 2(5)以2为底的对数
> log2(c)[1] 2(6) 以10为底的对数
> log10(b)[1] 0.69897(7)自定义底的对数
> log(c,base = 2)[1] 2#base是底,c为所求值(8)自然常数e的对数
> log(a,base=exp(1))[1] 2.302585(9)指数对数操作
> log(a^b,base=a)[1] 5> log(exp(3))[1] 3#若省略底数base,则默认自然常数e为底(三)、比较计算: ==、>、<、!=、<=、>=、isTRUE、identical
(1)!=
> a!=b[1] TRUE#!=表示“不等于”(2)isTRUE
> isTRUE(a<b)[1] TRUE> isTRUE(a>b)[1] FALSE#判断括号内是否为True(3)identical/精确比较两个对象
> identical(1, as.integer(1))[1] FALSE> identical(NaN, -NaN)[1] TRUE> f <- function(x) x> g <- compiler::cmpfun(f)> identical(f, g)[1] TRUE##1.Numeric或者"double" 是R优先选择的存储数值的方式。需要注意的是, 有的时候认为Numeric是"integer"和"double"的统称。2.Integer是整数。一般不管有没有小数点的数字, R默认存成Numeric, 这个时候需要使用as.integer函数强制去把数存为Integer。3.NA表示缺失值,即“Missing value”,是“not available”的缩写。主要会在从文件或数据库读取数据时遇到,或者将一个向量的长度扩展会出现NA值。4.Inf和-Inf就是指正负无穷,或者除以0时会出现。5.NaN表示无意义,即“not a number”(例如Inf-Inf/0/0)。6.另外,R语言中还有一种Null对象,一般被用在函数参数中,表示该参数没有被赋予任何值,或者某些函数返回值为Null。7.compiler可以将R的程式码编译后再执行,可增加执行的速度。8.编译与解释的区别:编译:编译器会把源文件先处理一遍,生成一个目标文件,再执行(先煮火锅再吃菜,效率高)。解释:边处理源文件,边执行(边煮火锅边吃菜,效率低)。(四)、逻辑计算: &、|、&&、||、xor
> x<-c(0,1,0,1)> y<-c(0,0,1,1)(1)只比较第一个元素(&&, ||)
> x && y;x || y[1] FALSE[1] FALSE#当x和y的第一个元素均为“真”时,其结果为TRUE,否则为FALSE(2)S4对象的逻辑运算,比较所有元素(&, |)
> x & y;x | y[1] FALSE FALSE FALSE TRUE[1] FALSE TRUE TRUE TRUE(3)异或
> xor(x,y)[1] FALSE TRUE TRUE FALSE> xor(x,!y)[1] TRUE FALSE FALSE TRUE#xor为异或,两值不等为真,两值相等为假(五)、约数计算:ceiling、floor、trunc、round、signif
(1)向上取整
> ceiling(5.4)[1] 6(2)向下取整
> floor(5.8)[1] 5(3)取整数
> trunc(3.9)[1] 3(4)四舍五入
> round(5.8)(5)四舍五入,保留2位小数
> round(5.8833, 2)[1] 5.88(6)四舍五入,保留前2位整数
> signif(5990000,2)[1] 6e+06(六)、数组计算: 最大、最小、范围、求和、均值、 加权平均、连乘、差分、秩、中位数、分位数、任意数、全体数
> d<-seq(1,10,2);d[1] 1 3 5 7 9(1)加权平均
> weighted.mean(d,rep(1,5))[1] 5> weighted.mean(d,c(1,1,2,2,2))[1] 5.75(2)连乘
> prod(1:5)[1] 120(3)差分
> diff(d)[1] 2 2 2 2#1.差分:差分计算,是用向量的后一项减去前一项,所获得的差值,差分的结果反映了离散量之间的一种变化。(4)秩
> rank(d)[1] 1 2 3 4 5(5)分位数
> quantile(d)0% 25% 50% 75% 100%1 3 5 7 9(6)任意any,全体all
> e<-seq(-3,3);e[1] -3 -2 -1 0 1 2 3> any(e<0);all(e<0)[1] TRUE[1] FALSE(七)、排列组合计算: 阶乘, 组合, 排列
(1)5!阶乘
> factorial(5)[1] 120(2)组合, 从5个中选出2个
> choose(5, 2)[1] 10(3)列出从5个中选出2个的组合所有项
> combn(5,2) [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10][1,] 1 1 1 1 2 2 2 3 3 4[2,] 2 3 4 5 3 4 5 4 5 5(4)计算0:10的组合个数
> for (n in 0:10) print(choose(n, k = 0:n))[1] 1[1] 1 1[1] 1 2 1[1] 1 3 3 1[1] 1 4 6 4 1[1] 1 5 10 10 5 1[1] 1 6 15 20 15 6 1[1] 1 7 21 35 35 21 7 1[1] 1 8 28 56 70 56 28 8 1[1] 1 9 36 84 126 126 84 36 9 1[1] 1 10 45 120 210 252 210 120 45 10 1(5)排列,从5个中选出2个
> choose(5, 2)*factorial(2)[1] 20(八)、累积计算: 累加, 累乘, 最小累积, 最大累积
(1)累加
> cumsum(1:5)[1] 1 3 6 10 15(2)累乘
> cumprod(1:5)[1] 1 2 6 24 120> e<-seq(-3,3);e[1] -3 -2 -1 0 1 2 3(3)最小累积cummin
> cummin(e)[1] -3 -3 -3 -3 -3 -3 -3#新向量的增加项,为e向量中累积的最小值(4)最大累积cummax
> cummax(e)[1] -3 -2 -1 0 1 2 3#新向量的增加项,为e向量中累积的最大值(九)、两个数组计算: 交集、并集、差集、数组是相等、取唯一、查匹配元素的索引、找重复元素索引
定义两个数组向量
> x <- c(9:20, 1:5, 3:7, 0:8);x[1] 9 10 11 12 13 14 15 16 17 18 19 20 1 2 3 4 5[18] 3 4 5 6 7 0 1 2 3 4 5 6 7 8> y<- 1:10;y[1] 1 2 3 4 5 6 7 8 9 10(1)交集
> intersect(x,y)[1] 9 10 1 2 3 4 5 6 7 8(2)并集
> union(x,y) [1] 9 10 11 12 13 14 15 16 17 18 19 20 1 2 3 4 5[18] 6 7 0 8#也会剔除各自集合内重复的元素(3)差集,从x中排除y
> setdiff(x,y) [1] 11 12 13 14 15 16 17 18 19 20 0(4)判断是否相等
> setequal(x, y)[1] FALSE(5)取唯一
> unique(c(x,y)) [1] 9 10 11 12 13 14 15 16 17 18 19 20 1 2 3 4 5[18] 6 7 0 8(6)找到x在y中存在的元素的索引(下标)
> which(x %in% y) [1] 1 2 13 14 15 16 17 18 19 20 21 22 24 25 26 27 28[18] 29 30 31> which(is.element(x,y)) [1] 1 2 13 14 15 16 17 18 19 20 21 22 24 25 26 27 28[18] 29 30 31#is.element(x,y):判断x是否为y内element(元素),输出为逻辑判断值(FALSE或TRUE) (7)找到重复元素的索引(下标)
> which(duplicated(x)) [1] 18 19 20 24 25 26 27 28 29 30二、三角函数计算
(一)、三角函数
(1)三角函数画图
# 加载ggplot2的库> library(ggplot2)> library(scales)# x坐标> x<-seq(-2*pi,2*pi,by=0.01)# y坐标>s1<-data.frame(x,y=sin(x),type=rep('sin',length(x)))# 正弦>s2<-data.frame(x,y=cos(x),type=rep('cos',length(x)))# 余弦>s3<-data.frame(x,y=tan(x),type=rep('tan',length(x)))# 正切>s4<-data.frame(x,y=1/tan(x),type=rep('cot',length(x)))# 余切>s5<-data.frame(x,y=1/sin(x),type=rep('sec',length(x)))# 正割>s6<-data.frame(x,y=1/cos(x),type=rep('csc',length(x)))# 余割>df<-rbind(s1,s2,s3,s4,s5,s6)#1.type参数用以定义每个点(x,y)的类型,不同的type可以用不同的颜色进行区分2.r是row(行)的含义,rbind将s1-6沿“行”合并data.frame(形式上,像是纵向合并)。# 用ggplot2画图> g<-ggplot(df,aes(x,y))> g<-g+geom_line(aes(colour=type,stat='identity'))> g<-g+scale_y_continuous(limits=c(0, 2))> g<-g+scale_x_continuous(breaks=seq(-2*pi,2*pi,by=pi),labels=c("-2*pi","-pi","0","pi","2*pi"))> g#1.ggplot2的核心理念是将绘图与数据分离,数据相关的绘图与数据无关的绘图分离。要使用ggplot2创建图形对象,就要用到ggplot()函数。2.基本语法*图形属性(aes):图形属性决定了图形的外观,如字体大小、标签位置及刻度线;*映射(mapping):数据中的变量到图形成分的映射;*统计变换(stat):对数据进行汇总,如箱线图:stat_boxplot、线图:stat_abline、直方图:stat_bin;*标度(scale):决定了变量如何被映射到图形属性上;*几何对象(geom):用来展示数据的几何对象,如geom_point,geom_bar,geom_abline3.审美映射p+geom_line(aes(size = rating))p+geom_line(aes(colour = rating))(二)、反三角函数
反正弦asin()反余弦acos()反正切atan()三、复数计算
(一)、创建一个复数
####(1)直接创建复数> ai<-5+2i;ai[1] 5+2i> class(ai)[1] "complex"(2)通过complex()函数创建复数
> bi<-complex(real=5,imaginary=2);bi[1] 5+2i> is.complex(bi)[1] TRUE(3)实数部分
> Re(ai)[1] 5(4)虚数部分
> Im(ai)[1] 2(5)取模
> Mod(ai)[1] 5.385165 # sqrt(5^2+2^2) = 5.385165(6)取辐角
> Arg(ai)[1] 0.3805064#复数的幅角是指复数在复平面上对应的向量和正向实数轴所成的有向角。(7)取轭
> Conj(ai)[1] 5-2i#共轭复数,两个实部相等,虚部互为相反数的复数互为共轭复数(conjugate complex number)。(二)、复数四则运算
加法公式:(a+bi)+(c+di) = (a+c)+(b+d)i减法公式:(a+bi)-(c+di)= (a-c)+(b-d)i乘法公式:(a+bi)(c+di) = ac+adi+bci+bidi=ac+bdi^2+(ad+bc)i=(ac-bd)+(ad+bc)i除法公式:(a+bi)/(c+di) = ((ac+bd)+(bc-ad)i)/(c^2+d^2)(三)、复数开平方根
(1)在实数域,给-9开平方根
> sqrt(-9)[1] NaN(2)在复数域,给-9开平方根
> sqrt(complex(real=-9))[1] 0+3i四、方程计算
(一)、一元一次方程
一元一次方程:a*x+b=0,设a=5,b=10,求x?
# 定义方程函数> f1 <- function (x, a, b) a*x+b# 给a,b常数赋值> a<-5;b<-10# 在(-10,10)的区间,精确度为0.0001位,计算方程的根> result <- uniroot(f1,c(-10,10),a=a,b=b,tol=0.0001)# 打印方程的根x> result$root[1] -2#1.uniroot()函数每次只能计算一个根,而且要求输入的区间端点值必须是正负号相反的(原理是通过二分法进行求解)以图形展示方程:y = 5*x + 10
# 创建数据点> x<-seq(-5,5,by=0.01)> y<-f1(x,a,b)> df<-data.frame(x,y)# 用ggplot2来画图> g<-ggplot(df,aes(x,y))> g<-g+geom_line(col='red') #红色直线> g<-g+geom_point(aes(result$root,0),col="red",size=3) #点> g<-g+geom_hline(yintercept=0)+geom_vline(xintercept=0) #坐标轴> g<-g+ggtitle(paste("y =",a,"* x +",b))> g#1.hline水平线2.vline竖直线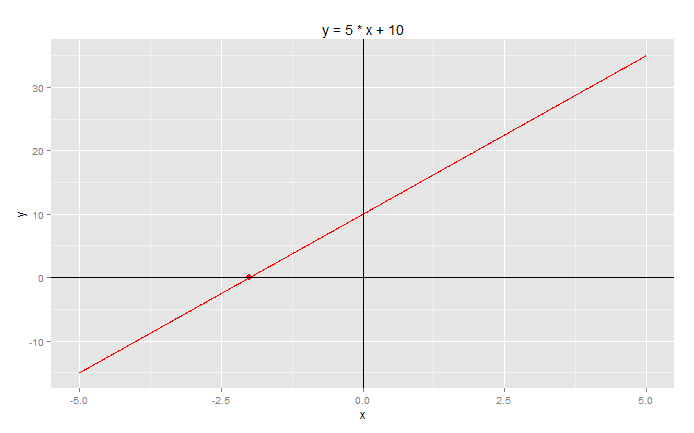
(二)、一元二次方程
一元二次方程:a*x^2+b*x+c=0,设a=1,b=5,c=6,求x?
> f2 <- function (x, a, b, c) a*x^2+b*x+c> a<-1;b<-5;c<-6> result <- uniroot(f2,c(0,-2),a=a,b=b,c=c,tol=0.0001)> result$root[1] -2> result <- uniroot(f2,c(-4,-3),a=a,b=b,c=c,tol=0.0001)> result$root[1] -3方程的两个根,一个是-2,一个是-3。
由于uniroot()函数,每次只能计算一个根,而且要求输入的区间端值,必须是正负号相反的。如果我们直接输入一个(-10,0)这个区间,那么uniroot()函数会出现错误。这应该是uniroot()为了统计计算对一元多次方程而设计的,所以为了使用uniroot()函数,我们需要取不同的区别来获得方程的根。
以图形展示方程:y = x^2 + 5*x + 6
# 创建数据点> x<-seq(-5,1,by=0.01)> y<-f2(x,a,b,c)> df<-data.frame(x,y)# 用ggplot2来画图> g<-ggplot(df,aes(x,y))> g<-g+geom_line(col='red') #红色曲线> g<-g+geom_hline(yintercept=0)+geom_vline(xintercept=0) #坐标轴> g<-g+ggtitle(paste("y =",a,"* x ^ 2 +",b,"* x +",c))> g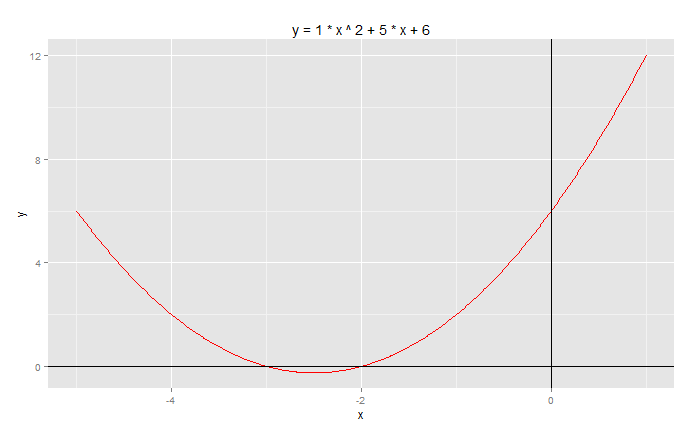
我们从图,并直接的看到了x的两个根取值范围。
(三)、一元三次方程
一元二次方程:a*x^3+b*x^2+c*x+d=0,设a=1,b=5,c=6,d=-11,求x?
> f3 <- function (x, a, b, c,d) a*x^3+b*x^2+c*x+d> a<-1;b<-5;c<-6;d<--11> result <- uniroot(f3,c(-5,5),a=a,b=b,c=c,d=d,tol=0.0001)> result$root[1] 0.9461458如果我们设置对了取值区间,那么一下就得到了方程的根。
以图形展示方程:y = x^2 + 5*x + 6
# 创建数据点> x<-seq(-5,5,by=0.01)> y<-f3(x,a,b,c,d)> df<-data.frame(x,y)# 用ggplot2画图> g<-ggplot(df,aes(x,y))> g<-g+geom_line(col='red') # 3次曲线> g<-g+geom_hline(yintercept=0)+geom_vline(yintercept=0) #坐标轴> g<-g+ggtitle(paste("y =",a,"* x ^ 3 +",b,"* x ^2 +",c,"* x + ",d))> g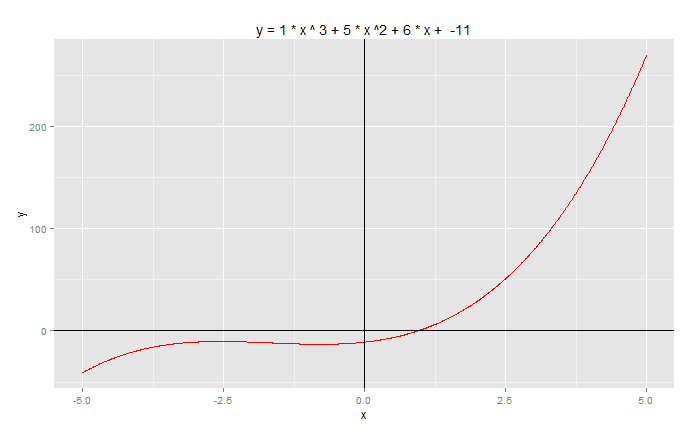
(四)、二元一次方程
R语言还可以解二次的方程组,当然计算方法,其实是利用于矩阵计算。
假设方程组:是以x1,x2两个变量组成的方程组,求x1,x2的值 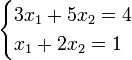
以矩阵形式,构建方程组 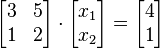
# 左矩阵> lf<-matrix(c(3,5,1,2),nrow=2,byrow=TRUE)# 右矩阵> rf<-matrix(c(4,1),nrow=2)# 计算结果> result<-solve(lf,rf)> result [,1][1,] 3[2,] -1得方程组的解,x1, x2分别为3和-1。
接下来,我们画出这两个线性方程的图。设y=X2, x=X1,把原方程组变成两个函数形式。
# 定义2个函数> fy1<-function(x) (-3*x+4)/5> fy2<-function(x) (-1*x+1)/2# 定义数据> x<-seq(-1,4,by=0.01)> y1<-fy1(x)> y2<-fy2(x)> dy1<-data.frame(x,y=y1,type=paste("y=(-3*x+4)/5"))> dy2<-data.frame(x,y=y2,type=paste("y=(-1*x+1)/2"))> df <- rbind(dy1,dy2)# 用ggplot2画图> g<-ggplot(df,aes(x,y))> g<-g+geom_line(aes(colour=type,stat='identity')) #2条直线> g<-g+geom_hline(yintercept=0)+geom_vline(xintercept=0) #坐标轴> g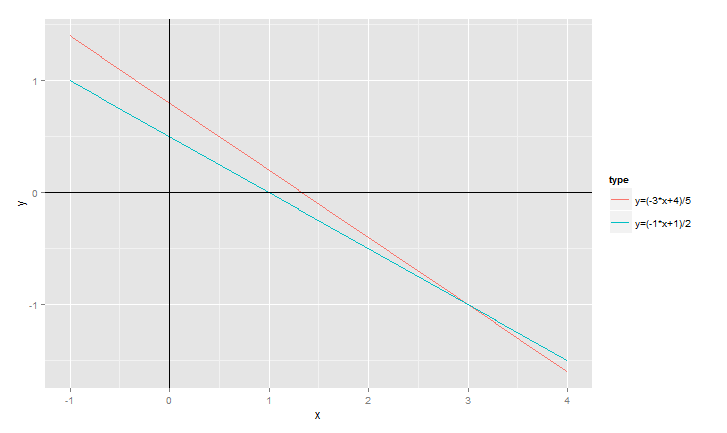
我们看到两条直线交点的坐标,就是方程组的两个根。多元一次方程,同样可以用这种方法来解得。
阅读全文
0 0
- R语言中的初等数学计算
- R语言中的数学计算(转载)
- 数学中的初等函数
- R语言中的并行计算
- R语言中的并行计算
- R语言中的并行计算
- C语言中的初等数据结构
- R数学计算
- R语言实现传统数学概念中的四舍五入
- R中的数学规划
- R语言科学计算
- 3D初等数学
- 初等数学概论
- 【学习】R语言中的并行计算:foreach,iterators, doParallel包
- 【学习】R语言中的并行计算:foreach,iterators, doParallel包
- R语言常用数学函数
- R语言常用数学函数
- R语言常用数学函数
- Java 中的特殊关键字:1.goto 2.const
- 阿里云首席科学家闵万里:我们为什么敢挑战一百年的制度,因为黑科技能为挽救生命抢来50%的可能性
- 送书 | 跟我一起学《流畅的Python》
- VirtualBox Ubuntu 16.04安装Tensorflow
- Spring + cxf 做服务
- R语言中的初等数学计算
- Java学习---10
- Easyui 搭建后台管理界面
- Redis 安装 启动 连接 配置 重启
- Android 快速发布开源项目到jcenter,出坑日记
- java编程原则
- 5 YAML 简介
- qml tableview红白间隔显示且行高可设置,并且cell 文字居中显示
- 哪些软素质互联网职场必备


