聚类
来源:互联网 发布:erp开源软件 编辑:程序博客网 时间:2024/06/13 13:10
聚类
Models
- Nearest neighbors
- Clustering
- Mixture of Gaussians 高斯混合
- Latent Dirichlet allocation 潜在狄利克雷分布

Nearest neighbors
应用:文章相似性
需要两点:
如何描述文章
做法很简单,(用文章生成词袋),摇一摇 数数出现在其中的单词 这就是单词在该文章中出现的次数 然后,我们要算出这些单词在全部词汇中出现的次数 我们要看这个文章库,在那儿的每个文章 一种常见的计算逆文档频率的做法是 把所有文章的总数除以 包含指定单词的文章的总数加上1, 再对结果取对数 利用这个公式,我们才得以对 那些在很多很多文章中频繁出现的单词进行影响消减
现在我们有两个指标 在这两个指标之间要做一个折中
这就是词频-逆文档频率法的做法 简单的说,就是把两个指标相乘 再重复一下,采用词频-逆文档频率法来表示 文章,我们会对那些在在读文章中出现次数多、而在 全部文章中出现次数少的单词增加权重 对那些如“the”、“of”和其他 诸如此类那些,在在读文章中出现次数多、但同时 也在所有文章中出现次数多的单词降低权重 使用这种表示的文章,在进行距离计算时 那些对在读文章重要的单词 就会体现出跟多的重要性如何计算距离
我们可以考虑给维度加权 也就是说,我们可以赋权重值给词汇表中的词语,或者给其它特征。也许因为标题信息量大,我们想要给标题加更多的权重。 而正文中则有许多不可靠的噪音。而正文中则有许多不可靠的噪音。类似的,假如像科研论文一样,文章有摘要部分,摘要可能包含比正文更有效的信息 。
另一个需要为特征加权的例子, 是当某些特征在不同观测点上变化很小, 而其它特征变化很大的情况。 原因可能是某一个特征的单位和其它特征不同, 或者只是因为那个维度上的方差(Variance)很大。
研究者通常会做几件事。 这些方法都基于观测点的分布,按比例增减特征值。数据矩阵的一整列,乘以该列最大最小值的差。另一种方法是用方差的倒数乘以这个特征的所有观测值 。
1.比例扩展欧氏距离
转化成矩阵形式:
在高维时,如果单词太多时用locality sensivitive hashing, 不需要具体的知道是那个邻居,近似的邻居就可以


2.Another natural inner product measure
直接相乘


3.Cosine similarity 余弦相似度
假设这个向量统计了文章一里的词汇数 这个向量统计了文章二里的词汇数 余弦相似度求的是,两向量夹角的余弦值,与原向量长度无关 余弦相似度求的是,两向量夹角的余弦值,与原向量长度无关
关于余弦相似度,我想强调几点 一是,它并不像欧氏距离那样是某种距离的度量 因为三角不等式对它不成立 但是用于计算稀疏向量,它依然十分有效 因为你只需要考虑非零元素 因为你只需要考虑非零元素

总结一下,余弦相似度取值范围在 -1 和 1 之间 但是如果只考虑特征值全为非负的情况 比如用TF-IDF向量表示一个文档 向量不可能出现在这个位置 我们只会在第一象限 所以夹角范围是0到90度 余弦相似度范围是0到1 这是我们关注的重点

4.normalization 是否需要规则化
当长度两倍,但是内容一样时,会使相似度变大,规则化有必要


但是,也不是所有情况都希望这种结果 有些情况下我们可能希望把文章的长度要考虑进去 因为余弦相似有个问题,有时候它会把两个非常没有相似点的东西 弄的很相似 比如说,有一篇特别长的文章 ,还有一篇推文, 里面包括很少内容 。(很有可能)两篇文章的余弦相似度,但是对于一个正在阅读洪篇巨著的人来说, 我们真地要给他推荐这个推文吗? 或许不会。 因而,通常的做法是 在基于规范化的余弦相似性和完全忽略规范化的余弦相似性之间做折中, 做法是设定向量中允许出现的单词数量的最大值,
5.其他一些距离

马氏距离Mahalanobis
http://www.cnblogs.com/likai198981/p/3167928.html
曼哈顿
http://www.cnblogs.com/jiahuafu/p/4013873.html
Jaccard相似性系数
Jaccard 系数,又叫Jaccard相似性系数,用来比较样本集中的相似性和分散性的一个概率。Jaccard系数等于样本集交集与样本集合集的比值,即J = |A∩B| ÷ |A∪B|。说白了就是交集除以并集,两个文档的共同都有的词除以两个文档所有的词。
汉明距离+simhash
simhash是谷歌发明的算法,据说很nb,可以将一个文档转换成64位的字节,然后我们可以通过判断两个字节的汉明距离就知道是否相似了。
http://blog.csdn.net/www_jun/article/details/52523966
http://blog.csdn.net/chengfzy/article/details/53526089
http://www.cnblogs.com/grandyang/p/6201215.html
simhash
http://www.cnblogs.com/hxsyl/p/4518506.html
https://www.zhihu.com/question/32207097
局部敏感哈希LSH
比如文章,可以有文字方面的特性 这是我们从一开始就关注的方面 也可以包括统计某人阅读这个文章数量的特性 这是一个数量特性 这种情况下,或许我们可以使用余弦相似度 来计算文字方面的距离,以便结果不受文章长度的影响 对于阅读次数,我们肯定要使用它原始数据 而不进行规范化,这样就可以使用欧氏距离计算 而且可以更进一步,对不同属性使用不同的距离度量 同时根据自己的要求赋予不同度量相应的权重 类似加权欧氏距离的做法 只是现在,我们不用把权重局限在欧氏距离上 这些权重可以应用到任何一种形式的距离度量上 然后把加权后的距离用来计算相似性,在这个例子中,就是文章 想想我们最初做的那个关于房子的应用 有一长串房子的列表 并附有每个房子的描述 如果对于中介这些冗长的描述你根本无意去看, 想要忽略文字长度的影响,就使用余弦距离 来比较 但是,对于想房间面积大小、卧室数量、 卫生间数量等,这些数据的原始形式包含很多信息 使用欧氏距离就比较自然。 你会看到这种情况在 很多很多的应用领域里非常普遍 总结一下,到目前为止, 我们介绍了不同的表示文章的方法 不同的方法来计算文章间的距离 这些是后面要介绍的最近邻搜索算法的基础 同时 这也是一些针对具体问题可以参考的做法 更希望能给大家一个重要的信息是,要充分了解任务的特性 及任务的影响 在有些任务上,没有绝对正确的答案 重要的是要考虑清楚不管作出什么样的决定 要明白这个决定对自己的任务的意义 整个这个模块到此,好像都是在给大家一个提醒 当然,希望不止于此,希望能给你一个套工具 一套你能在 学习其他工具时能够使用的工具 [音乐 翻译:张晓刚]
1. KD-Tree

kd树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
详看 http://blog.csdn.net/silangquan/article/details/41483689
1.1 建立kdTree
建立kdTree实际上是一个不断划分的过程,首先选择最sparse的维度,然后找到该维度上的中间点,垂直该维度做第一次划分。此时k维超平面被一分为二,在两个子平面中再找最sparse的维度,依次类推知道最后一个点也被划分。那么就形了一个不断二分的树。如图所示。
(2,3), (5,4), (9,6), (4,7), (8,1), (7,2).
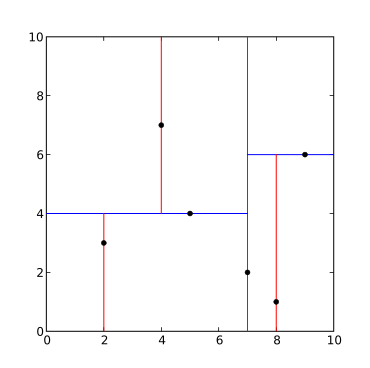

第一种选取轴点的策略是median of the most spread dimension pivoting strategy,对于所有描述子数据(特征矢量),统计他们在每个维度上的数据方差,挑选出方差中最大值,对应的维就是split域的值。数据方差大说明沿该坐标轴方向上数据点分散的比较开。这个方向上,进行数据分割可以获得最好的平衡。数据点集Data-Set按照第split维的值排序,位于正中间的那个数据点 被选为轴点。
但是问题来了,理论上空间均匀分布的点,在一个方向上分割只有,通过计算方差,下一次分割就不会出现在这个方向上了,但是一些特殊的情况中,还是会出现问题,比如(左图)


这样就会出现很多长条的分割,对于KDTree来说是很不利的。
为了避免这种情况,需要修改一下算法,纬度的选择的依据为数据范围最大的那一维作为分割纬度,之后也是选中这个纬度的中间节点作为轴点,然后进行分割,分割出来的结果是(右图)
1.2.在kdTree中查找。
基本的思路很简单:首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于就进入左子树分支,等于就进入右子树分支直到叶子结点),顺着“搜索路径”很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子结点;然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中去搜索(将其他子结点加入到搜索路径)。重复这个过程直到搜索路径为空。
这里还有几个细节需要注意一下,如下图,假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。


举一个稍微复杂的例子,我们来查找点(2,4.5),在(7,2)处测试到达(5,4),在(5,4)处测试到达(4,7),然后search_path中的结点为<(7,2), (5,4), (4,7)>,从search_path中取出(4,7)作为当前最佳结点nearest, dist为3.202;
然后回溯至(5,4),以(2,4.5)为圆心,以dist=3.202为半径画一个圆与超平面y=4相交,如下图,所以需要跳到(5,4)的左子空间去搜索。所以要将(2,3)加入到search_path中,现在search_path中的结点为<(7,2), (2, 3)>;另外,(5,4)与(2,4.5)的距离为3.04 < dist = 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
回溯至(2,3),(2,3)是叶子节点,直接平判断(2,3)是否离(2,4.5)更近,计算得到距离为1.5,所以nearest更新为(2,3),dist更新为(1.5)
回溯至(7,2),同理,以(2,4.5)为圆心,以dist=1.5为半径画一个圆并不和超平面x=7相交, 所以不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2,4.5)的最近邻点,最近距离为1.5。


clustering
应用:相关文章内容聚类
需要两点:
k-means 用在大数据集时用map reduce
map reduce is framwork 并行
- [x] 新增 Todo 列表功能
- [x] 修复 地方LaTex 公式渲染问题
- [x] 新增 LaTex 公式编号功能
Mixture models
概率模型,为了抓住聚类的不确定性,计算出属于哪个类的概率
可以根据用户的喜好反馈来帮助我们确定类别
LDA
允许属于多类别,并且告诉我们不同主题包含在文章中的比例
应用:相关文章内容聚类
需要两点:
k-means 用在大数据集时用map reduce
map reduce is framwork 并行
2. 书写一个质能守恒公式1
3. 高亮一段代码2
@requires_authorizationclass SomeClass: passif __name__ == '__main__': # A comment print 'hello world'4. 高效绘制 流程图
5. 高效绘制 序列图
Alice->Bob: Hello Bob, how are you?Note right of Bob: Bob thinksBob-->Alice: I am good thanks!6. 高效绘制 甘特图
title 项目开发流程 section 项目确定 需求分析 :a1, 2016-06-22, 3d 可行性报告 :after a1, 5d 概念验证 : 5d section 项目实施 概要设计 :2016-07-05 , 5d 详细设计 :2016-07-08, 10d 编码 :2016-07-15, 10d 测试 :2016-07-22, 5d section 发布验收 发布: 2d 验收: 3d7. 绘制表格
8. 更详细语法说明
想要查看更详细的语法说明,可以参考我们准备的 Cmd Markdown 简明语法手册,进阶用户可以参考 Cmd Markdown 高阶语法手册 了解更多高级功能。
总而言之,不同于其它 所见即所得 的编辑器:你只需使用键盘专注于书写文本内容,就可以生成印刷级的排版格式,省却在键盘和工具栏之间来回切换,调整内容和格式的麻烦。Markdown 在流畅的书写和印刷级的阅读体验之间找到了平衡。 目前它已经成为世界上最大的技术分享网站 GitHub 和 技术问答网站 StackOverFlow 的御用书写格式。
什么是 Cmd Markdown
您可以使用很多工具书写 Markdown,但是 Cmd Markdown 是这个星球上我们已知的、最好的 Markdown 工具——没有之一 :)因为深信文字的力量,所以我们和你一样,对流畅书写,分享思想和知识,以及阅读体验有极致的追求,我们把对于这些诉求的回应整合在 Cmd Markdown,并且一次,两次,三次,乃至无数次地提升这个工具的体验,最终将它演化成一个 编辑/发布/阅读 Markdown 的在线平台——您可以在任何地方,任何系统/设备上管理这里的文字。
1. 实时同步预览
我们将 Cmd Markdown 的主界面一分为二,左边为编辑区,右边为预览区,在编辑区的操作会实时地渲染到预览区方便查看最终的版面效果,并且如果你在其中一个区拖动滚动条,我们有一个巧妙的算法把另一个区的滚动条同步到等价的位置,超酷!
2. 编辑工具栏
也许您还是一个 Markdown 语法的新手,在您完全熟悉它之前,我们在 编辑区 的顶部放置了一个如下图所示的工具栏,您可以使用鼠标在工具栏上调整格式,不过我们仍旧鼓励你使用键盘标记格式,提高书写的流畅度。

3. 编辑模式
完全心无旁骛的方式编辑文字:点击 编辑工具栏 最右侧的拉伸按钮或者按下 Ctrl + M,将 Cmd Markdown 切换到独立的编辑模式,这是一个极度简洁的写作环境,所有可能会引起分心的元素都已经被挪除,超清爽!
4. 实时的云端文稿
为了保障数据安全,Cmd Markdown 会将您每一次击键的内容保存至云端,同时在 编辑工具栏 的最右侧提示 已保存 的字样。无需担心浏览器崩溃,机器掉电或者地震,海啸——在编辑的过程中随时关闭浏览器或者机器,下一次回到 Cmd Markdown 的时候继续写作。
5. 离线模式
在网络环境不稳定的情况下记录文字一样很安全!在您写作的时候,如果电脑突然失去网络连接,Cmd Markdown 会智能切换至离线模式,将您后续键入的文字保存在本地,直到网络恢复再将他们传送至云端,即使在网络恢复前关闭浏览器或者电脑,一样没有问题,等到下次开启 Cmd Markdown 的时候,她会提醒您将离线保存的文字传送至云端。简而言之,我们尽最大的努力保障您文字的安全。
6. 管理工具栏
为了便于管理您的文稿,在 预览区 的顶部放置了如下所示的 管理工具栏:

通过管理工具栏可以:
发布:将当前的文稿生成固定链接,在网络上发布,分享
新建:开始撰写一篇新的文稿
删除:删除当前的文稿
导出:将当前的文稿转化为 Markdown 文本或者 Html 格式,并导出到本地
列表:所有新增和过往的文稿都可以在这里查看、操作
模式:切换 普通/Vim/Emacs 编辑模式
7. 阅读工具栏

通过 预览区 右上角的 阅读工具栏,可以查看当前文稿的目录并增强阅读体验。
工具栏上的五个图标依次为:
目录:快速导航当前文稿的目录结构以跳转到感兴趣的段落
视图:互换左边编辑区和右边预览区的位置
主题:内置了黑白两种模式的主题,试试 黑色主题,超炫!
阅读:心无旁骛的阅读模式提供超一流的阅读体验
全屏:简洁,简洁,再简洁,一个完全沉浸式的写作和阅读环境
8. 阅读模式
在 阅读工具栏 点击 或者按下 Ctrl+Alt+M 随即进入独立的阅读模式界面,我们在版面渲染上的每一个细节:字体,字号,行间距,前背景色都倾注了大量的时间,努力提升阅读的体验和品质。
9. 标签、分类和搜索
在编辑区任意行首位置输入以下格式的文字可以标签当前文档:
标签: 未分类
标签以后的文稿在【文件列表】(Ctrl+Alt+F)里会按照标签分类,用户可以同时使用键盘或者鼠标浏览查看,或者在【文件列表】的搜索文本框内搜索标题关键字过滤文稿,如下图所示:
10. 文稿发布和分享
在您使用 Cmd Markdown 记录,创作,整理,阅读文稿的同时,我们不仅希望它是一个有力的工具,更希望您的思想和知识通过这个平台,连同优质的阅读体验,将他们分享给有相同志趣的人,进而鼓励更多的人来到这里记录分享他们的思想和知识,尝试点击 (Ctrl+Alt+P) 发布这份文档给好友吧!
再一次感谢您花费时间阅读这份欢迎稿,点击 (Ctrl+Alt+N) 开始撰写新的文稿吧!祝您在这里记录、阅读、分享愉快!
作者 @ghosert
2016 年 07月 07日
- 支持 LaTeX 编辑显示支持,例如:
∑ni=1ai=0 , 访问 MathJax 参考更多使用方法。 ↩ - 代码高亮功能支持包括 Java, Python, JavaScript 在内的,四十一种主流编程语言。 ↩
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- android 基础 serialization,Transient
- CodeForces 876D Sorting the Coins
- Kolakosiki序列问题
- MySql的函数和事件(navicat界面操作)
- html-javascript前端页面刷新重载的方法汇总
- 聚类
- 代码触发,手动触发touchstart事件,touch事件,click事件,自定义事件
- ConfigReader(四十)—— ReadNpcConfig
- Centos6.5安装Nginx
- BZOJ2734 [HNOI2012]集合选数
- 让Android 设备通过USB 转RJ45有线网卡上网
- centos 实现ssh远程连接docker
- 正则表达式的思维导图解读
- java web 发送邮件


