GBDT
来源:互联网 发布:foxmail咋样知乎 编辑:程序博客网 时间:2024/05/16 04:47
这一篇记录一下目前比较常用的集成算法GBDT。集成算法从根上来看,主要分为两大类--boosting和bagging。先说bagging,他的思想是建立多个弱学习期,最后的结果进行投票决定,而且每个弱学习器的训练样本都是在总样本中随机抽样的,这个算法是并行的,每个弱学习器是一起运算的。而boosting算法,其原理是在上一个弱学习器的基础上,构建下一个弱学习器,也就是根据上一个弱学习器的结果,对样本进行加权等操作,再构建下一个弱学习器,这个算法是不能并行运算的。
bagging算法的例子有随机森林,boosting算法的例子有adaboost,GBDT,XGBOOST。
adaboost是将上一个弱学习器判断错误的样本的权重加大,然后让下一个弱学习器对这些分错的样本进行重点学习,从而将误差降低,最后将这些弱学习器进行加权组合,误差率低的,赋予较大的权重,使其在决策中起到较大的作用,而误差率高的,赋予较小的权重。
损失函数可以对本身求微分得到最小值,然后再求出相应的参数。
GBDT的思想是初始学习一个基础决策树,然后用决策树输出一个结果,然后求这棵决策树的误差,然后再建立下一棵树去拟合上一棵树的误差,本质是:在m轮,寻找一个函数(决策树)h(x),去拟合上一轮的误差。也就是不停的寻找函数,加入到前边已经求出的函数的线性组合当中。在我们得到第二棵树的输出时,我们想要的是,这棵树的误差达到最小(本轮树拟合的是上一棵树的误差,本轮的误差就是第二棵树的输出与上一棵树的误差的差值),这个误差不能用两个数相减来表示,而是用损失函数来衡量,也就是损失函数达到最小。损失函数不等于误差,当损失函数为平方损失函数时,损失函数的值等于残差,当为其他的损失函数时,值就是相当于残差的估计。
GBDT就是用损失函数的负梯度拟合本轮残差的近似值,我们用负梯度求出第一轮的残差的近似值,然后再第二轮时利用(Xi,rti)再去构建第二棵树,这时就要求出函数h(x)使第二颗树的损失函数最小
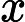
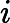
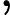
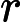
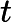

GBDT用的必须是CART二叉分类树
具体算法过程如下,
在上一节中,我们介绍了GBDT的基本思路,但是没有解决损失函数拟合方法的问题。针对这个问题,大牛Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。第t轮的第i个样本的损失函数的负梯度表示为


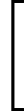
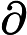
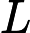
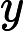
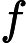
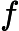
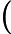
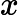
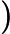

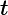

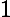
利用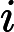
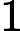
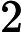
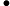
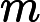

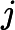
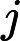
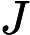
针对每一个叶子节点里的样本,我们求出使损失函数最小,也就是拟合叶子节点最好的的输出值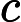

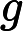
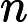
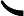
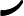
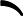
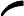

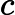

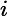
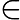
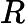
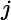

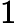

这一步就是让第二棵树的损失函数最小,求出让他损失函数最小的C值,就求出了函数h(x)。
这样我们就得到了本轮的决策树拟合函数如下:

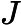
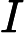
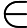
从而本轮最终得到的强学习器的表达式如下:
通过损失函数的负梯度来拟合,我们找到了一种通用的拟合损失误差的办法,这样无轮是分类问题还是回归问题,我们通过其损失函数的负梯度的拟合,就可以用GBDT来解决我们的分类回归问题。区别仅仅在于损失函数不同导致的负梯度不同而已。
这样轮回下去,直到误差小于一个值的时候,才停止。
- GBDT
- GBDT
- GBDT
- GBDT
- GBDT
- GBDT
- GBDT
- GBDT
- GBDT
- GBDT
- gbdt
- GBDT
- GBDT
- GBDT参考 (GBDT+LR)
- GBDT算法
- gbdt 资料
- gbdt算法
- gbdt介绍
- Shader编程学习笔记(八)—— Surface Shader 2
- MFC的多国语言界面的实现
- Linux下的nohup说明
- 简单理解spherical harmonic lighting(球谐光照)
- apk不能安装问题:Installation failed
- GBDT
- Linux\Android IO\内存信息统计
- Shader编程学习笔记(九)—— Cg语言入门1
- MyBatis学习总结(二)——使用MyBatis对表执行CRUD操作
- JavaScript基础知识
- DispatcherServlet学习笔记
- 用lua扩展你的Nginx(转载)
- Cesium 学习记录(1) 搭建Cesium开发环境
- uva 1252 最少看几位数字 就可以分辨出所有的二进制数字


