理解神经网络,从简单的例子开始(1)7行python代码构建神经网络
来源:互联网 发布:淘宝卖家数据中心在哪 编辑:程序博客网 时间:2024/05/17 23:30
理解神经网络,从简单的例子开始(1)7行python代码构建神经网络
前言
本文分为两个部分,第一个部分是一个简单的实例:9行Python代码搭建神经网络,这篇文章原文为:原文链接, 其中中文翻译版来自:中文翻译版。已经转载如下。这个实例算是通俗易懂,只是,它更多的是(本人觉得)对于一个简单的神经网络整个过程的描述,对于初学者而言,阅读之后很可能还不是特别明白其中的原理。要明白其中的原理,需要更深入的思考:为什么能够这个神经网络能够预测结果?而本文就是在这个实例的基础之上的思考。这也就是本文的第二部分内容。
第一部分:简单的例子
(转载)
本文我会解释这个神经网络是怎样炼成的,所以你也可以搭建你自己的神经网络。也会提供一个加长版、但是也更漂亮的源代码。
不过首先,什么是神经网络?人脑总共有超过千亿个神经元细胞,通过神经突触相互连接。如果一个神经元被足够强的输入所激活,那么它也会激活其他神经元,这个过程就叫“思考”。
我们可以在计算机上创建神经网络,来对这个过程进行建模,且并不需要模拟分子级的生物复杂性,只要观其大略即可。为了简化起见,我们只模拟一个神经元,含有三个输入和一个输出。

我们将训练这个神经元来解决下面这个问题,前四个样本叫作“训练集”,你能求解出模式吗?”?”处应该是0还是1呢? 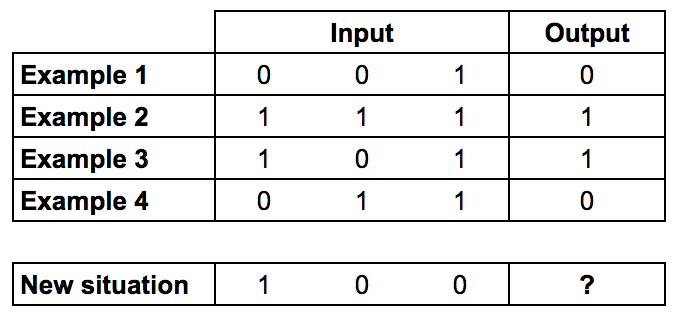
或许你已经发现了,输出总是与第一列的输入相等,所以?应该是1。
训练过程
问题虽然很简单,但是如何教会神经元来正确的回答这个问题呢?我们要给每个输入赋予一个权重,权重可能为正也可能为负。权重的绝对值,代表了输入对输出的决定权。在开始之前,我们先把权重设为随机数,再开始训练过程:
- 从训练集样本读取输入,根据权重进行调整,再代入某个特殊的方程计算神经元的输出。
- 计算误差,也就是神经元的实际输出和训练样本的期望输出之差。
- 根据误差的方向,微调权重。
- 重复10000次。
最终神经元的权重会达到训练集的最优值。如果我们让神经元去思考一个新的形势,遵循相同过程,应该会得到一个不错的预测。
计算神经元输出的方程
你可能会好奇,计算神经元输出的人“特殊方程”是什么?首先我们取神经元输入的加权总和:
接下来我们进行正规化,将结果限制在0和1之间。这里用到一个很方便的函数,叫Sigmoid函数:
如果绘出图像,Sigmoid函数是S形的曲线: 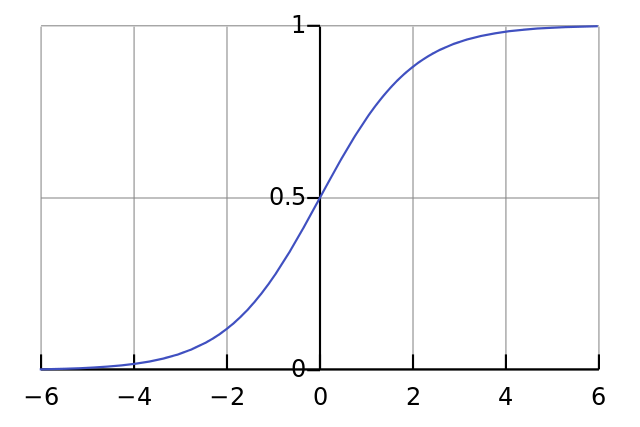
将第一个公式代入第二个,即得最终的神经元输出方程:
调整权重的方程
在训练进程中,我们需要调整权重,但是具体如何调整呢?就要用到“误差加权导数”方程:
为什么是这个方程?首先我们希望调整量与误差量成正比,然后再乘以输入(0-1)。如果输入为0,那么权重就不会被调整。最后乘以Sigmoid曲线的梯度,为便于理解,请考虑:
- 我们使用Sigmoid曲线计算神经元输出。
- 如果输出绝对值很大,这就表示该神经元是很确定的(有正反两种可能)。
- Sigmoid曲线在绝对值较大处的梯度较小。
- 如果神经元确信当前权重值是正确的,那么就不需要太大调整。乘以Sigmoid曲线的梯度可以实现。
Sigmoid曲线的梯度可由导数获得:
代入公式可的最终的权重调整方程:
实际上也有其他让神经元学习更快的方程,这里主要是取其相对简单的优势。
构建Python代码
尽管我们不直接用神经网络库,但还是要从Python数学库Numpy中导入4种方法:
- exp: 自然对常数
- array: 创建矩阵
- dot:矩阵乘法
- random: 随机数
比如我们用array()方法代表训练集:
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])training_set_outputs = array([[0, 1, 1, 0]]).T.T函数就是矩阵转置。我想现在可以来看看美化版的源代码了,最后我还会提出自己的终极思考。源代码中已经添加了注释逐行解释。注意每次迭代我们都一并处理了整个训练集,以下为完整的Python示例:
第二部分: 思考
神经网络学习属于深度学习,深度学习是机器学习的一个分支。机器学习的一般步骤为:预处理数据集。使用训练集数据训练模型,让模型更加优化。模型的优化过程可以理解为参数的调整过程,而一个模型可以理解为一个函数,一个函数由许多参数构成。训练结束之后,就可以做预测工作。
例子中有三个input,设置了三个参数,开始的时候这三个参数是随机产生的,在(-1, 1)范围之间。我们的任务就是让这三个参数能够根据误差自动调整大小,使得误差越来越小。现在我们的问题有:
1. 如何计算误差?
2. 如何让改变参数,变大还是减小?
3. 参数每一次变化的量是多少?这个改变的量是固定的吗?
我们会发现,这几个问题和梯度下降发求局部最优解很像。都是通过朝着一个“正确”的方向一点点逼近“最优”解。
第一个问题是如何计算误差。这个问题在上面转载的部分已经给出了。简单来讲就是使用实际的结果减去程序所计算的结果的差值。也就是代码中这部分:error = training_set_outputs - output。
第二个问题涉及到了参数调整的方向性,也就是是应该增大参数呢还是减小参数的。例子中的计算方法是这样的:
adjustment=dot(training_set_inputs.T,error*self.__sigmoid_derivative(output))self.synaptic_weights += adjustment如果error小于0,那么程序计算的结果比实际的值大,所得的adjustment小于0,所以synaptic_weights 也随之变小,在下一轮迭代之后,synaptic_weights 会越来越小,直到error的值逼近0(虽然此时还是小于0)。
第三个问题是关于“步长”的问题。先来看这个公式:
该公式对应的图像为:
该公式的特点是,x值越大,y值越逼近1;x值越小,y值越逼近于-1。也就是x的绝对值越大,该函数所对应的斜率越小,也就是变化率越小,也即是所对应的导数的值越小。如果上面的公式用S表示,那么它的导数等于S*(1-S),也就是下面所示的公式:
Sigmoid曲线的梯度可由导数获得:
代入公式可的最终的权重调整方程:
对应的代码为:
output = self.think(training_set_inputs)error = training_set_outputs - outputadjustment = dot(training_set_inputs.T,error*self.__sigmoid_derivative(output))对应于上面的代码,如果output值接近于0.5,__sigmoid_derivative(output)所得到的值就很大(该函数表示sigmoid函数的导数),因为斜率很大,相应地,步长很大。如果output的值很大或者很小,对应的斜率很小,所以它的步长就小。但是,如果实际的值为1,而output的值是一个负值而且很小,这会怎么样呢?开始的时候,步长会很小,随着算法的迭代,output值会越来越逼近实际值(也就是1),这时候步长逐渐变大,直到output大于0,这时候步长开始逐渐变小。这个体现在sigmoid函数的斜率从小变大再变小的过程。所以,随着算法的迭代,随着计算的结果越来越逼近真实结果,步长会逐渐变小。
最后,在英文版原文中有python代码,可以直接粘贴复制,如果xrange函数报错,就改为range。
结束,感谢!
最后贴一下代码:
from numpy import exp, array, random, dotclass NeuralNetwork(): def __init__(self): # Seed the random number generator, so it generates the same numbers # every time the program runs. # random.seed(1) # We model a single neuron, with 3 input connections and 1 output connection. # We assign random weights to a 3 x 1 matrix, with values in the range -1 to 1 # and mean 0. # random() -> [0, 1) self.synaptic_weights = 2 * random.random((3, 1)) - 1 # The Sigmoid function, which describes an S shaped curve. # We pass the weighted sum of the inputs through this function to # normalise them between 0 and 1. def __sigmoid(self, x): return 1 / (1 + exp(-x)) # The derivative of the Sigmoid function. # This is the gradient of the Sigmoid curve. # It indicates how confident we are about the existing weight. def __sigmoid_derivative(self, x): return x * (1 - x) # We train the neural network through a process of trial and error. # Adjusting the synaptic weights each time. def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations): for iteration in range(number_of_training_iterations): # Pass the training set through our neural network (a single neuron). output = self.think(training_set_inputs) # Calculate the error (The difference between the desired output # and the predicted output). error = training_set_outputs - output # Multiply the error by the input and again by the gradient of the Sigmoid curve. # This means less confident weights are adjusted more. # This means inputs, which are zero, do not cause changes to the weights. adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output)) # Adjust the weights. self.synaptic_weights += adjustment # The neural network thinks. def think(self, inputs): # Pass inputs through our neural network (our single neuron). return self.__sigmoid(dot(inputs, self.synaptic_weights));if __name__ == "__main__": #Intialise a single neuron neural network. neural_network = NeuralNetwork() print("Random starting synaptic weights: ") print(neural_network.synaptic_weights) # The training set. We have 4 examples, each consisting of 3 input values # and 1 output value. training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]]) training_set_outputs = array([[0, 1, 1, 0]]).T # Train the neural network using a training set. # Do it 10,000 times and make small adjustments each time. neural_network.train(training_set_inputs, training_set_outputs, 10000) print ("New synaptic weights after training: ") print( neural_network.synaptic_weights) # Test the neural network with a new situation. print ("Considering new situation [1, 0, 0] -> ?: ") print (neural_network.think(array([1, 0, 0])))- 理解神经网络,从简单的例子开始(1)7行python代码构建神经网络
- 理解神经网络,从简单的例子开始(2)使用python建立多层神经网络
- Kernel Methods (1) 从简单的例子开始
- 【神经网络】11行Python代码实现的神经网络
- 深入理解C#:从简单的数据类型开始
- .NET开发基础:从简单的例子理解泛型
- 先从简单的开始
- 从简单的三角形开始
- BP神经网络(python代码)
- python构建深度神经网络(DNN)
- C#开发的进化史(从简单的数据类型开始)
- Shiro介绍(二):从简单的认证开始
- 机器学习与神经网络(四):BP神经网络的介绍和Python代码实现
- 从简单开始,编写一个Makefile(1)
- 一个 11 行 Python 代码实现的神经网络
- 一个 11 行 Python 代码实现的神经网络
- 一个 11 行 Python 代码实现的神经网络
- 一个 11 行 Python 代码实现的神经网络
- 怎么解决java.lang.NoClassDefFoundError错误
- android摄像头对焦出现的bug
- GoldenGate(1)_概述与安装
- Error: Cannot find module 'webpack-merge'
- unity怪物的状态机
- 理解神经网络,从简单的例子开始(1)7行python代码构建神经网络
- java面试常用算法大全
- RTAI API ---RTAI service functions
- 洛谷P1242 新汉诺塔 【神奇的递归】
- python的lambda()和map()的个人理解
- Java 基础知识总结(一)
- NRF24L01的通信距离
- PAT刷题:1037. 在霍格沃茨找零钱(20)
- $.fn与$.extend区别


