word2vec初步了解
来源:互联网 发布:js input name 数组 编辑:程序博客网 时间:2024/06/05 06:20
最近学校小组作业要做一个项目,涉及到自然语言处理,所以先了解一些word2vec,也是为了以后便于温习将这些记录下来
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,是用来生成此项的工具。它简单、高效,因此引起了很多人的关注
词向量就是将一个词语转换成计算机可以识别的向量的形式。
在网上看到了一个特别形象的例子:
如一句话“大家喜欢吃苹果”,总共四个词“大家”,“喜欢”,“吃”,“苹果”
那么这句话是一个自然语言的概率是:
P(大家,喜欢,吃,苹果)=p(大家)p(喜欢|大家)p(吃|大家,喜欢)p(苹果|大家,喜欢,吃)
p(大家)表示“大家”这个词在语料库里面出现的概率;
p(喜欢|大家)表示“喜欢”这个词出现在“大家”后面的概率;
p(吃|大家,喜欢)表示“吃”这个词出现在“大家喜欢”后面的概率;
p(苹果|大家,喜欢,吃)表示“苹果”这个词出现在“大家喜欢吃”后面的概率。
把这些概率连乘起来,得到的就是这句话平时出现的概率。
从上面的情况看来,计算起来是非常麻烦的,一般都用偷懒的方式。
为了表示简单,上面的公式用下面的方式表示:
其中,如果Contexti是空的话,就是它自己p(w),另外如“吃”的Context就是“大家”、“喜欢”,其余的对号入座。
由于上面方法太过繁琐,衍生出N-gram模型。
N-gram就是只管这个词前面的n-1个词,加上它自己,总共n个词,来计算P(wi|Context)。
因此效果要看n的取值大小,一般取3。
在Bengio03的文章中,他们提到除了上面说的问题之外,n-gram还存在其他问题:
1.n-gram语言模型无法建模更远的关系,语料的不足使得无法训练更高阶的语言模型。
2.这种模型无法建模出词之间的相似度,有时候两个具有某种相似性的词,如果一个词经常出现在某段词之后,那么也许另一个词出现在这段词后面的概率也比较大,比如:
The cat is walking in the bedroom
A dog was running in a room
如果第一句话里的元组在语料中出现的很多,训练的很充分,第二句话中的元组在语料中出现的少,训练的不充分,那么使用语言模型计算第一句话的概率就比较高,而第二句话的概率就低。
如果有一种方法,能知道The和a相似,cat和dog相似等等,并且会给相似的词类似的语言模型概率,那么第二句话也可以得到高概率。
既然我们想要的就是P(wi|Context),那么可以用一个神经网络直接去建模这个概率,网络的输入是前N-1单词,输出是V个节点,其中第i个节点的输出值就是P(wi|Wp)。下面用Wp表示Context前面的N-1的个词。
具体的模型如下:
1.每个单词i表示成一个向量Ci
2.把单词的向量表示Ci排列成一个更大的向量作为神经网络输入,输出是第n个单词。
3.训练出C和神经网络的参数。 
如果不考虑虚线(输入跳过隐层直接到输出的连接),那么红框内是个标准的三层前向神经网络,输入层是单词的向量表示,隐层使用tanh激活函数,输出层用softmax做概率归一化。
对于每个样本,输入是context,输出是一个1 of V的向量,即V个输出节点,只有wi对应的那个节点为1,其他都为0。
使用BP算法(前向传播和反向传播)训练这个网络即可得到所有的参数值。
虽然这篇文章的方法是为了计算语言模型,但也同时获得一种单词在向量空间上的表示。而这个副作用才是google的word2vec的真正目标。
词汇表,可以用一个长长的向量来表示。词的个数,就是词汇表向量的维度。
word2vec,它的输入是词汇表向量,当看到一个训练样本时,对于样本中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。它的输出也是词汇表向量,对于训练样本的标签中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。
那么,对所有的样本,训练这个神经元网络。收敛之后,将从输入层到隐含层的那些权重,作为每一个词汇表中的词的向量。比如,第一个词的向量是(w1,1 w1,2 w1,3 … w1,m),m是表示向量的维度。所有虚框中的权重就是所有词的向量的值。有了每个词的有限维度的向量,就可以用到其它的应用中,因为它们就像图像,有了有限维度的统一意义的输入。 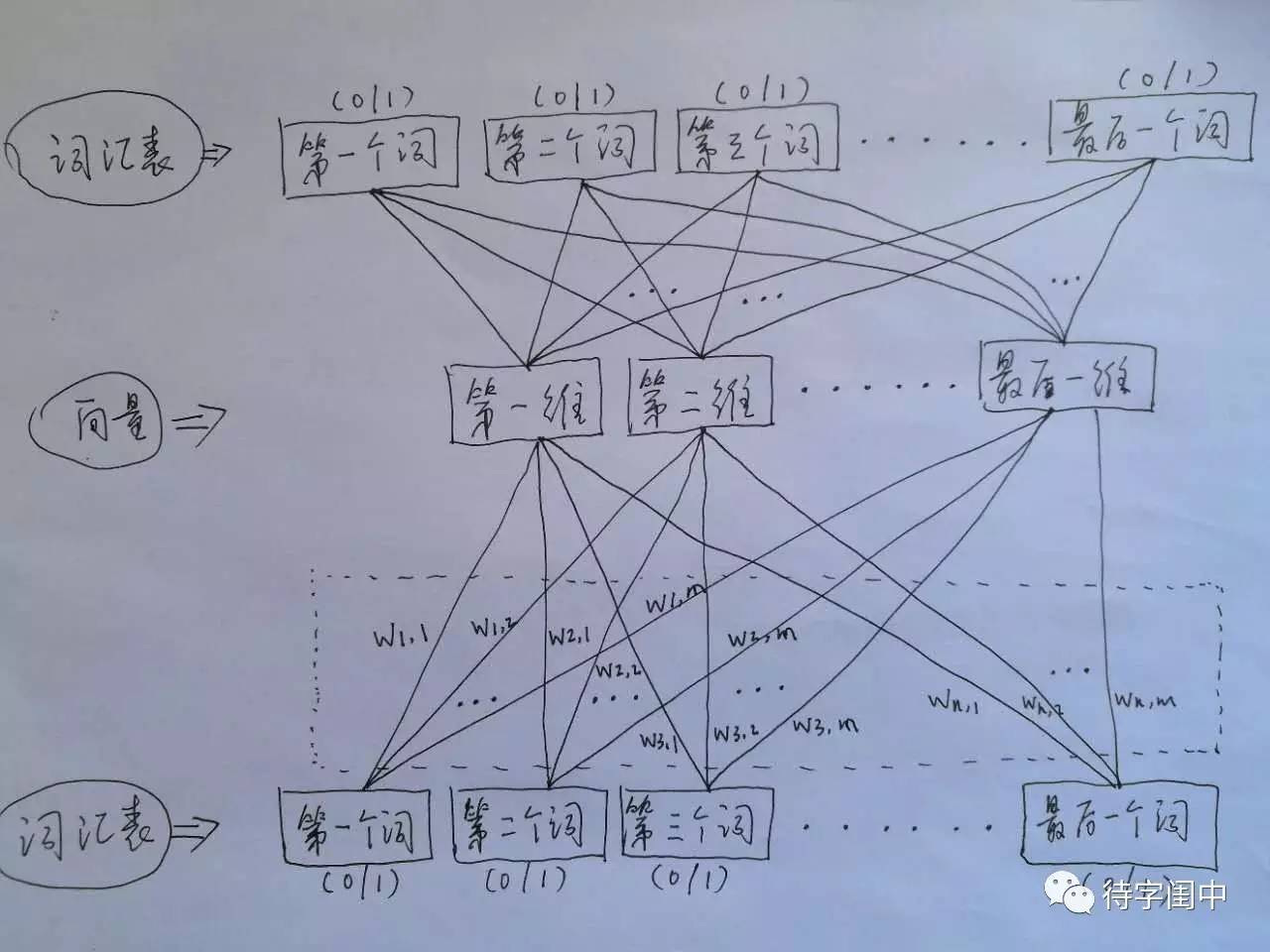
word2vec是根据文章中每个词的上下关系,把每个词的关系映射到同一坐标系下,构成了一个大矩阵,矩阵下反映了每个词的关系。
- word2vec初步了解
- python初步实现word2vec
- python初步实现word2vec
- python初步实现word2vec
- python初步实现word2vec
- Word2Vec学习笔记1 初步梳理
- SPRING 了解初步
- Jawe的初步了解
- Jawe的初步了解
- 初步了解osworkflow designer
- (二)初步了解
- 初步了解Oracle
- 初步了解CSS
- 初步了解CSS3
- Felix?OSGi? -初步了解
- 环境变量初步了解
- 初步了解接口测试
- skyeye初步了解
- Spring---SpEL
- 偷天换日(树形动态规划)
- UVA 1331Minimax Triangulation——最优三角剖分
- 【C#与.NET程序设计】(3)- C#基本参数类型
- #Linux Shell 脚本编程(10)—文本过滤(合并与分割—sort、uniq、join、cut、paste、split)
- word2vec初步了解
- LuoguP1962 斐波那契数列 解题报告【矩阵快速幂】
- lower_bound
- 能解开assetbundle格式资源的UnityStudio工具
- 最全的Android安全工具合集
- 安装linux开发板以及裸机程序烧写
- 安装MariaDB
- Linux Unit10
- 第一个只出现一次的字符 (剑指offer)


