数据库中间件 Sharding-JDBC 源码分析 —— JDBC实现与读写分离
来源:互联网 发布:win10电脑主题软件 编辑:程序博客网 时间:2024/06/05 07:32
摘要: 原创出处 http://www.iocoder.cn/Sharding-JDBC/jdbc-implement-and-read-write-splitting/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文主要基于 Sharding-JDBC 1.5.0 正式版
- 1. 概述
- 2. unspported 包
- 3. adapter 包
- 3.1 WrapperAdapter
- 3.2 AbstractDataSourceAdapter
- 3.3 AbstractConnectionAdapter
- 3.4 AbstractStatementAdapter
- 3.5 AbstractPreparedStatementAdapter
- 3.6 AbstractResultSetAdapter
- 4. 插入流程
- 5. 查询流程
- 6. 读写分离
- 666. 彩蛋
������关注微信公众号:【芋道源码】有福利:
1. RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
2. RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
3. 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
4. 新的源码解析文章实时收到通知。每周更新一篇左右。
5. 认真的源码交流微信群。
1. 概述
本文主要分享 JDBC 与 读写分离 的实现。为什么会把这两个东西放在一起讲呢?客户端直连数据库的读写分离主要通过获取读库和写库的不同连接来实现,和 JDBC Connection 刚好放在一块。
OK,我们先来看一段 Sharding-JDBC 官方对自己的定义和定位
Sharding-JDBC定位为轻量级java框架,使用客户端直连数据库,以jar包形式提供服务,未使用中间层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式,可理解为增强版的JDBC驱动,旧代码迁移成本几乎为零。
可以看出,Sharding-JDBC 通过实现 JDBC规范,对上层提供透明化数据库分库分表的访问。�� 黑科技?实际我们使用的数据库连接池也是通过这种方式实现对上层无感知的提供连接池。甚至还可以通过这种方式实现对 Lucene、MongoDB 等等的访问。
扯远了,下面来看看 Sharding-JDBC jdbc 包的结构:
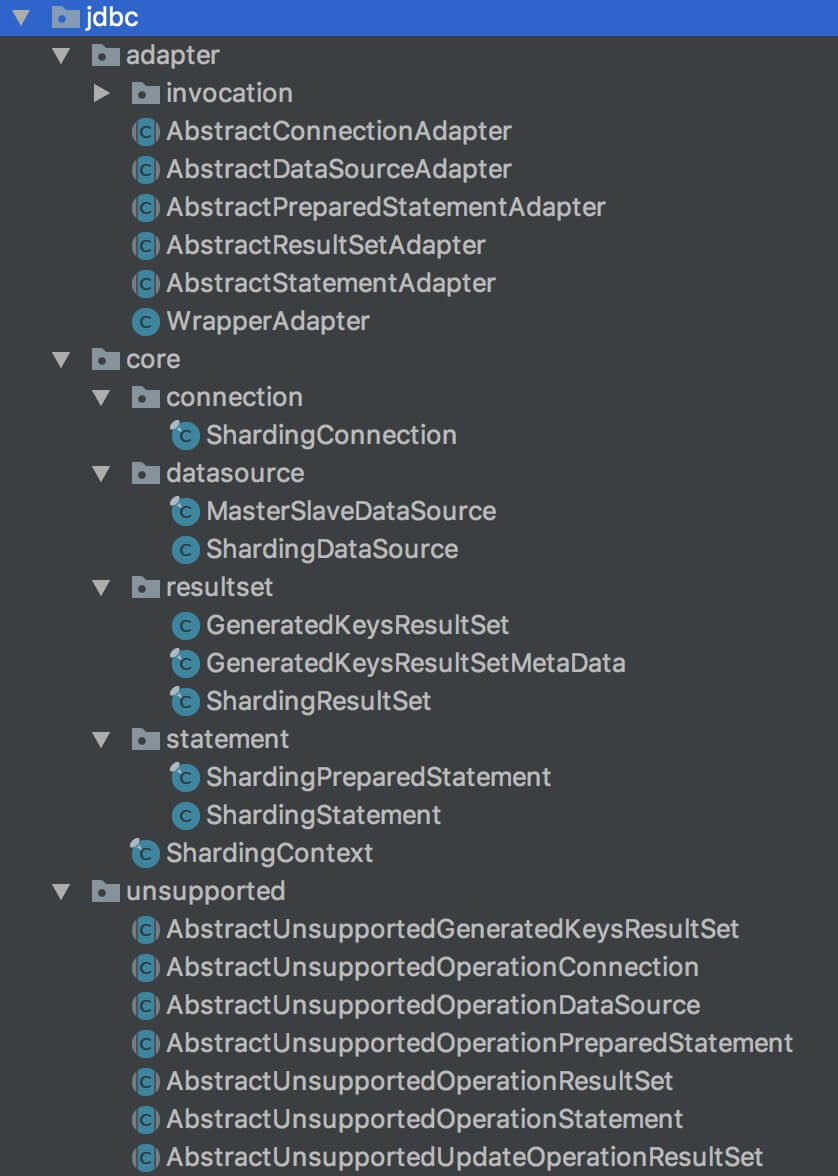
unsupported:声明不支持的数据操作方法adapter:适配类,实现和分库分表无关的方法core:核心类,实现和分库分表相关的方法
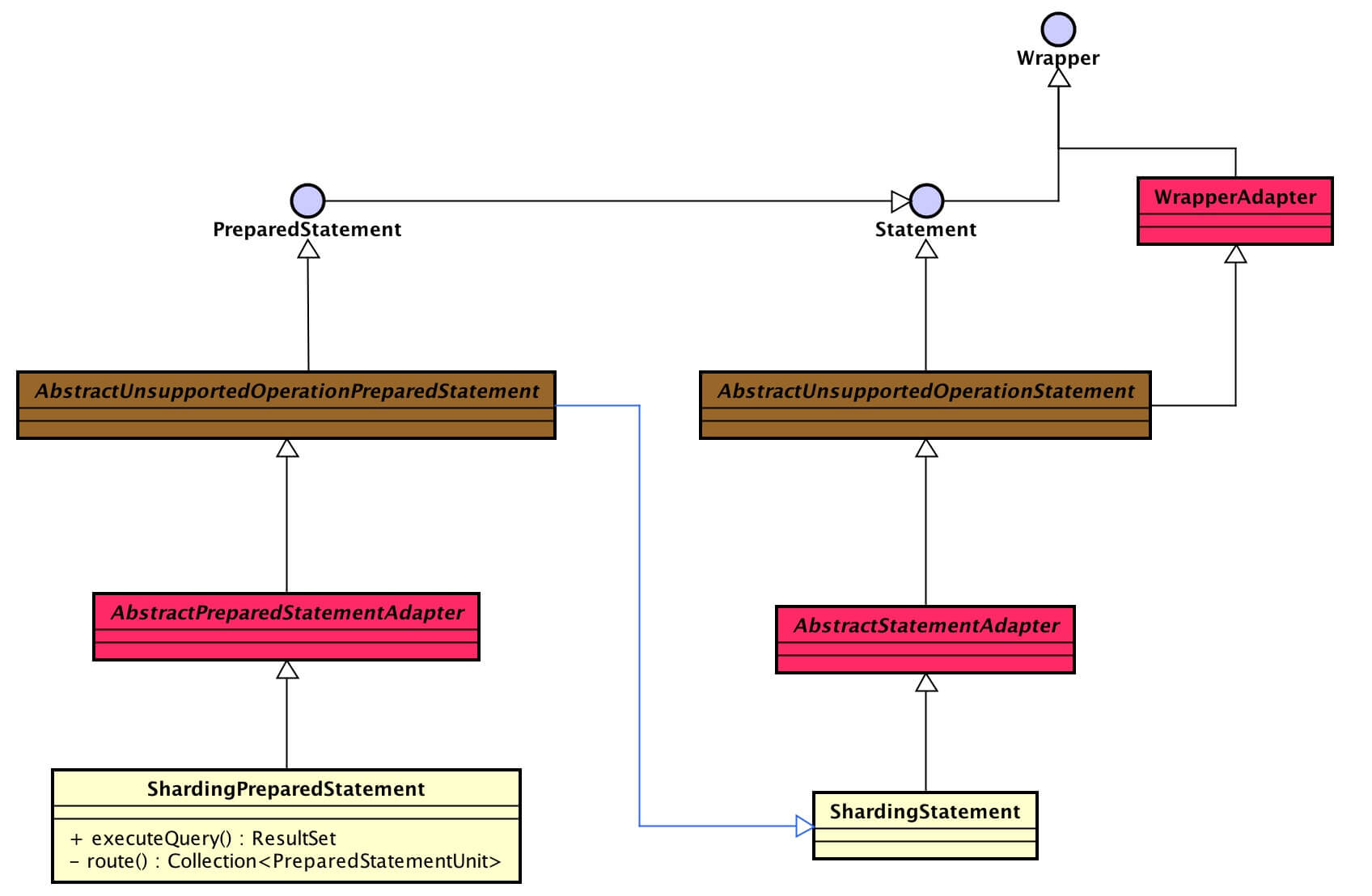
根据 core 包,可以看出分到四种我们超级熟悉的对象
Datasource
Connection
Statement
ResultSet
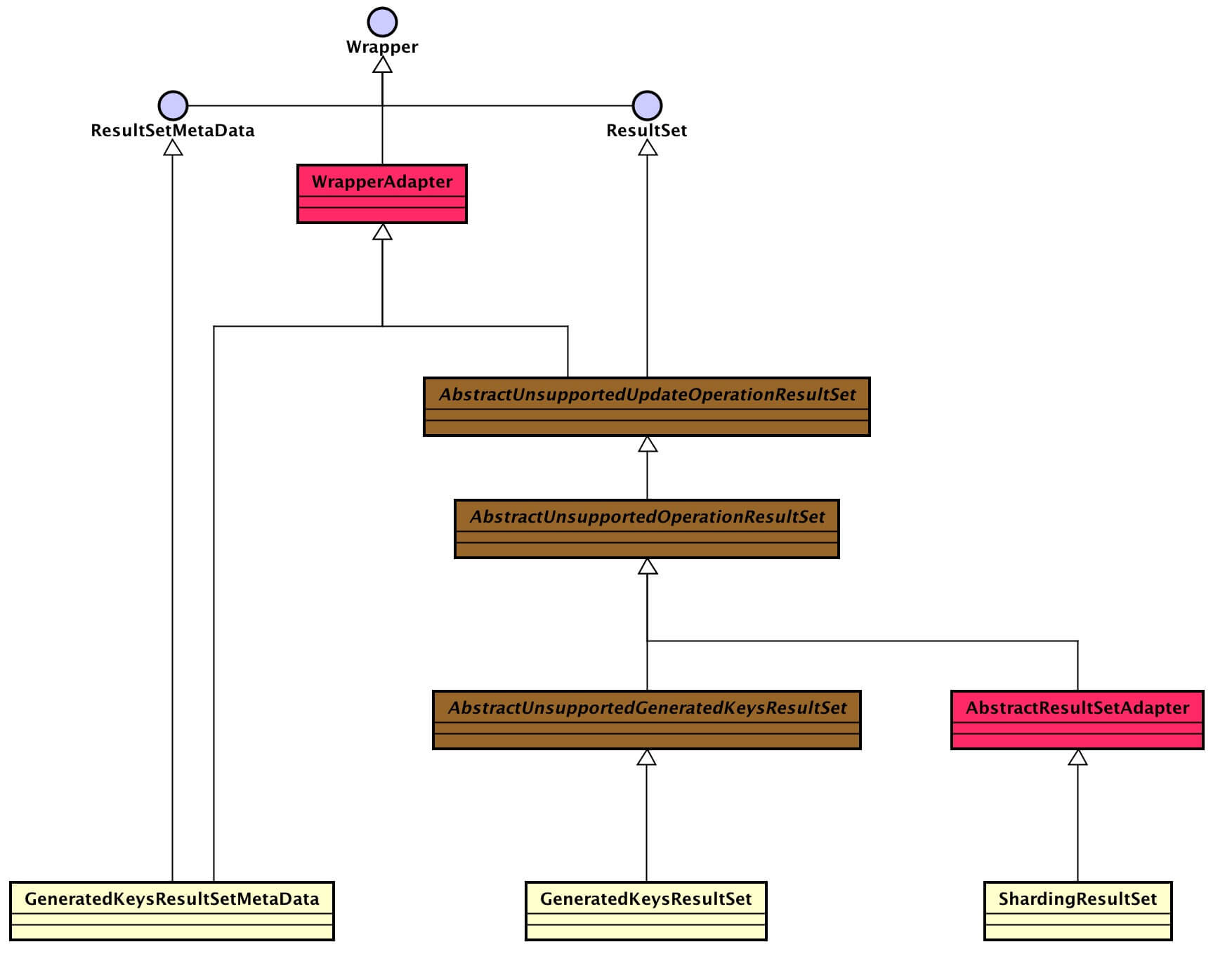
实现层级如下:JDBC 接口 <=(继承)== unsupported抽象类 <=(继承)== unsupported抽象类 <=(继承)== core类。
本文内容顺序
unspported包adapter包- 插入流程,分析的类:
- ShardingDataSource
- ShardingConnection
- ShardingPreparedStatement(ShardingStatement 类似,不重复分析)
- GeneratedKeysResultSet、GeneratedKeysResultSetMetaData
- 查询流程,分析的类:
- ShardingPreparedStatement
- ShardingResultSet
- 读写分离,分析的类:
- MasterSlaveDataSource
**Sharding-JDBC 正在收集使用公司名单:传送门。
�� 你的登记,会让更多人参与和使用 Sharding-JDBC。传送门
Sharding-JDBC 也会因此,能够覆盖更多的业务场景。传送门
登记吧,骚年!传送门**
2. unspported 包
unspported 包内的抽象类,声明不支持操作的数据对象,所有方法都是 throw new SQLFeatureNotSupportedException() 方式。
public abstract class AbstractUnsupportedGeneratedKeysResultSet extends AbstractUnsupportedOperationResultSet { @Override public boolean getBoolean(final int columnIndex) throws SQLException { throw new SQLFeatureNotSupportedException("getBoolean"); } // .... 省略其它类似方法}public abstract class AbstractUnsupportedOperationConnection extends WrapperAdapter implements Connection { @Override public final CallableStatement prepareCall(final String sql) throws SQLException { throw new SQLFeatureNotSupportedException("prepareCall"); } // .... 省略其它类似方法}3. adapter 包
adapter 包内的抽象类,实现和分库分表无关的方法。
考虑到第4、5两小节更容易理解,本小节贴的代码会相对多
3.1 WrapperAdapter
WrapperAdapter,JDBC Wrapper 适配类。
对 Wrapper 接口实现如下两个方法:
@Overridepublic final <T> T unwrap(final Class<T> iface) throws SQLException { if (isWrapperFor(iface)) { return (T) this; } throw new SQLException(String.format("[%s] cannot be unwrapped as [%s]", getClass().getName(), iface.getName()));}@Overridepublic final boolean isWrapperFor(final Class<?> iface) throws SQLException { return iface.isInstance(this);}提供子类 #recordMethodInvocation() 记录方法调用,#replayMethodsInvocation() 回放记录的方法调用:
/*** 记录的方法数组*/private final Collection<JdbcMethodInvocation> jdbcMethodInvocations = new ArrayList<>();/*** 记录方法调用.* * @param targetClass 目标类* @param methodName 方法名称* @param argumentTypes 参数类型* @param arguments 参数*/public final void recordMethodInvocation(final Class<?> targetClass, final String methodName, final Class<?>[] argumentTypes, final Object[] arguments) { try { jdbcMethodInvocations.add(new JdbcMethodInvocation(targetClass.getMethod(methodName, argumentTypes), arguments)); } catch (final NoSuchMethodException ex) { throw new ShardingJdbcException(ex); }}/*** 回放记录的方法调用.* * @param target 目标对象*/public final void replayMethodsInvocation(final Object target) { for (JdbcMethodInvocation each : jdbcMethodInvocations) { each.invoke(target); }}这两个方法有什么用途呢?例如下文会提到的 AbstractConnectionAdapter 的
#setAutoCommit(),当它无数据库连接时,先记录;等获得到数据连接后,再回放:// AbstractConnectionAdapter.java@Overridepublic final void setAutoCommit(final boolean autoCommit) throws SQLException { this.autoCommit = autoCommit; if (getConnections().isEmpty()) { // 无数据连接时,记录方法调用 recordMethodInvocation(Connection.class, "setAutoCommit", new Class[] {boolean.class}, new Object[] {autoCommit}); return; } for (Connection each : getConnections()) { each.setAutoCommit(autoCommit); }}JdbcMethodInvocation,反射调用JDBC相关方法的工具类:
public class JdbcMethodInvocation { /** * 方法 */ @Getter private final Method method; /** * 方法参数 */ @Getter private final Object[] arguments; /** * 调用方法. * * @param target 目标对象 */ public void invoke(final Object target) { try { method.invoke(target, arguments); // 反射调用 } catch (final IllegalAccessException | InvocationTargetException ex) { throw new ShardingJdbcException("Invoke jdbc method exception", ex); } }}
提供子类 #throwSQLExceptionIfNecessary() 抛出异常链:
protected void throwSQLExceptionIfNecessary(final Collection<SQLException> exceptions) throws SQLException { if (exceptions.isEmpty()) { // 为空不抛出异常 return; } SQLException ex = new SQLException(); for (SQLException each : exceptions) { ex.setNextException(each); // 异常链 } throw ex;}3.2 AbstractDataSourceAdapter
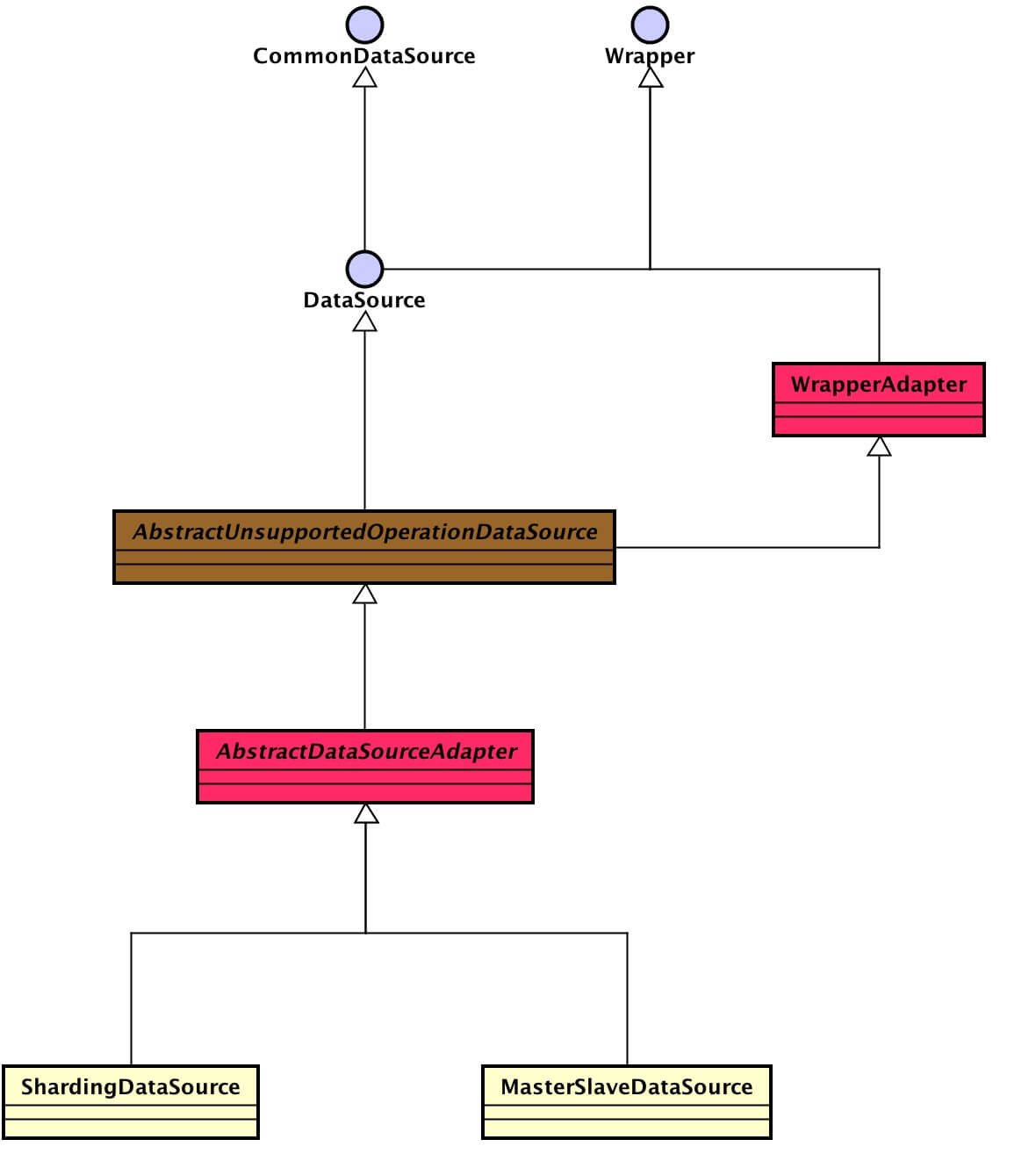
AbstractDataSourceAdapter,数据源适配类。
直接点击链接查看源码。
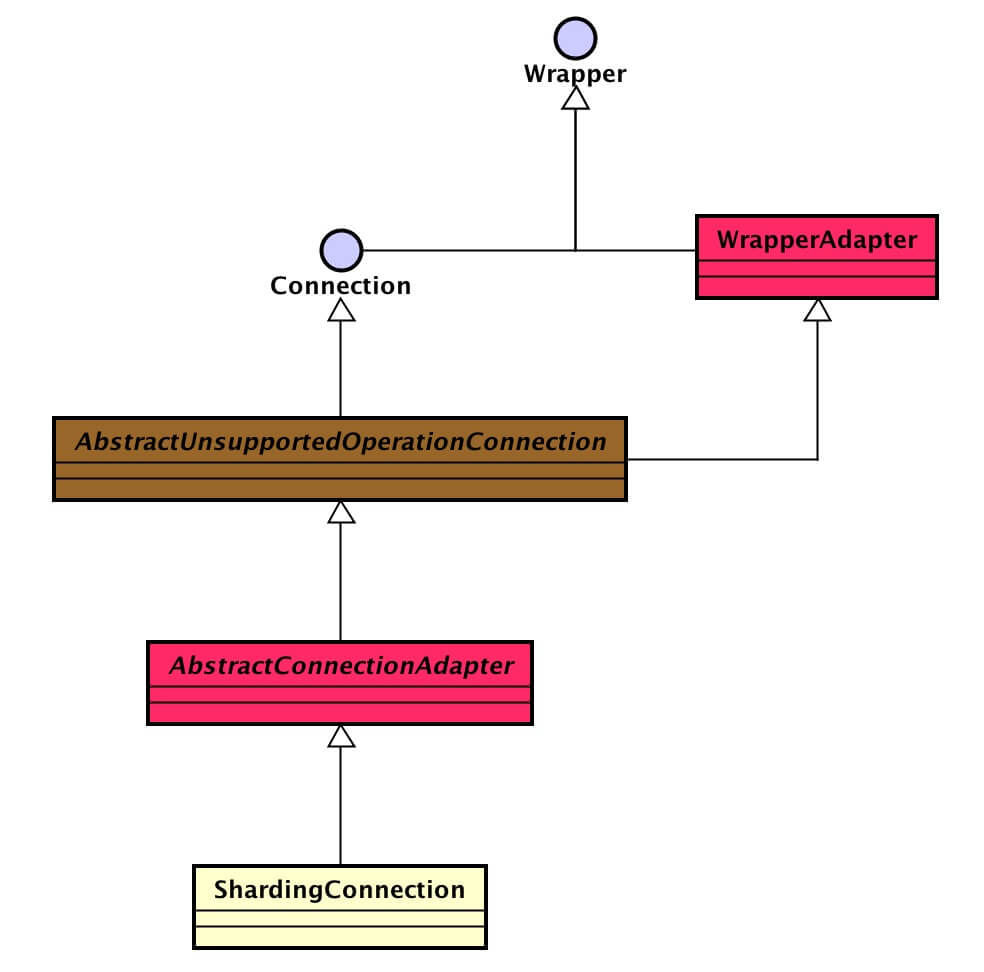
3.3 AbstractConnectionAdapter
AbstractConnectionAdapter,数据库连接适配类。
我们来瞅瞅大家最关心的事务相关方法的实现。
/*** 是否自动提交*/private boolean autoCommit = true;/*** 获得链接** @return 链接*/protected abstract Collection<Connection> getConnections();@Overridepublic final boolean getAutoCommit() throws SQLException { return autoCommit;}@Overridepublic final void setAutoCommit(final boolean autoCommit) throws SQLException { this.autoCommit = autoCommit; if (getConnections().isEmpty()) { // 无数据连接时,记录方法调用 recordMethodInvocation(Connection.class, "setAutoCommit", new Class[] {boolean.class}, new Object[] {autoCommit}); return; } for (Connection each : getConnections()) { each.setAutoCommit(autoCommit); }}#setAutoCommit()调用时,实际会设置其所持有的 Connection 的autoCommit属性#getConnections()和分库分表相关,因而仅抽象该方法,留给子类实现
@Overridepublic final void commit() throws SQLException { for (Connection each : getConnections()) { each.commit(); }}@Overridepublic final void rollback() throws SQLException { Collection<SQLException> exceptions = new LinkedList<>(); for (Connection each : getConnections()) { try { each.rollback(); } catch (final SQLException ex) { exceptions.add(ex); } } throwSQLExceptionIfNecessary(exceptions);}#commit()、#rollback()调用时,实际调用其所持有的 Connection 的方法异常情况下,
#commit()和#rollback()处理方式不同,笔者暂时不知道答案,求证后会进行更新#commit()处理方式需要改成和#rollback()一样。代码如下:
@Overridepublic final void commit() throws SQLException { Collection<SQLException> exceptions = new LinkedList<>(); for (Connection each : getConnections()) { try { each.commit(); } catch (final SQLException ex) { exceptions.add(ex); } } throwSQLExceptionIfNecessary(exceptions);}
事务级别和是否只读相关代码如下:
/*** 只读*/private boolean readOnly = true;/*** 事务级别*/private int transactionIsolation = TRANSACTION_READ_UNCOMMITTED;@Overridepublic final void setReadOnly(final boolean readOnly) throws SQLException { this.readOnly = readOnly; if (getConnections().isEmpty()) { recordMethodInvocation(Connection.class, "setReadOnly", new Class[] {boolean.class}, new Object[] {readOnly}); return; } for (Connection each : getConnections()) { each.setReadOnly(readOnly); }}@Overridepublic final void setTransactionIsolation(final int level) throws SQLException { transactionIsolation = level; if (getConnections().isEmpty()) { recordMethodInvocation(Connection.class, "setTransactionIsolation", new Class[] {int.class}, new Object[] {level}); return; } for (Connection each : getConnections()) { each.setTransactionIsolation(level); }}3.4 AbstractStatementAdapter
AbstractStatementAdapter,静态语句对象适配类。
@Overridepublic final int getUpdateCount() throws SQLException { long result = 0; boolean hasResult = false; for (Statement each : getRoutedStatements()) { if (each.getUpdateCount() > -1) { hasResult = true; } result += each.getUpdateCount(); } if (result > Integer.MAX_VALUE) { result = Integer.MAX_VALUE; } return hasResult ? Long.valueOf(result).intValue() : -1;}/*** 获取路由的静态语句对象集合.* * @return 路由的静态语句对象集合*/protected abstract Collection<? extends Statement> getRoutedStatements();#getUpdateCount()调用持有的 Statement 计算更新数量#getRoutedStatements()和分库分表相关,因而仅抽象该方法,留给子类实现
3.5 AbstractPreparedStatementAdapter
AbstractPreparedStatementAdapter,预编译语句对象的适配类。
#recordSetParameter()实现对占位符参数的设置:
/*** 记录的设置参数方法数组*/private final List<SetParameterMethodInvocation> setParameterMethodInvocations = new LinkedList<>();/*** 参数*/@Getterprivate final List<Object> parameters = new ArrayList<>();@Overridepublic final void setInt(final int parameterIndex, final int x) throws SQLException { setParameter(parameterIndex, x); recordSetParameter("setInt", new Class[]{int.class, int.class}, parameterIndex, x);}/*** 记录占位符参数** @param parameterIndex 占位符参数位置* @param value 参数*/private void setParameter(final int parameterIndex, final Object value) { if (parameters.size() == parameterIndex - 1) { parameters.add(value); return; } for (int i = parameters.size(); i <= parameterIndex - 1; i++) { // 用 null 填充前面未设置的位置 parameters.add(null); } parameters.set(parameterIndex - 1, value);}/*** 记录设置参数方法调用** @param methodName 方法名,例如 setInt、setLong 等* @param argumentTypes 参数类型* @param arguments 参数*/private void recordSetParameter(final String methodName, final Class[] argumentTypes, final Object... arguments) { try { setParameterMethodInvocations.add(new SetParameterMethodInvocation(PreparedStatement.class.getMethod(methodName, argumentTypes), arguments, arguments[1])); } catch (final NoSuchMethodException ex) { throw new ShardingJdbcException(ex); }}/*** 回放记录的设置参数方法调用** @param preparedStatement 预编译语句对象*/protected void replaySetParameter(final PreparedStatement preparedStatement) { addParameters(); for (SetParameterMethodInvocation each : setParameterMethodInvocations) { updateParameterValues(each, parameters.get(each.getIndex() - 1)); // 同一个位置多次设置,值可能不一样,需要更新下 each.invoke(preparedStatement); }}/*** 当使用分布式主键时,生成后会添加到 parameters,此时 parameters 数量多于 setParameterMethodInvocations,需要生成该分布式主键的 SetParameterMethodInvocation*/private void addParameters() { for (int i = setParameterMethodInvocations.size(); i < parameters.size(); i++) { recordSetParameter("setObject", new Class[]{int.class, Object.class}, i + 1, parameters.get(i)); }}private void updateParameterValues(final SetParameterMethodInvocation setParameterMethodInvocation, final Object value) { if (!Objects.equals(setParameterMethodInvocation.getValue(), value)) { setParameterMethodInvocation.changeValueArgument(value); // 修改占位符参数 }}逻辑类似
WrapperAdapter的#recordMethodInvocation(),#replayMethodsInvocation(),请认真阅读代码注释SetParameterMethodInvocation,继承 JdbcMethodInvocation,反射调用参数设置方法的工具类:
public final class SetParameterMethodInvocation extends JdbcMethodInvocation { /** * 位置 */ @Getter private final int index; /** * 参数值 */ @Getter private final Object value; /** * 设置参数值. * * @param value 参数值 */ public void changeValueArgument(final Object value) { getArguments()[1] = value; }}
3.6 AbstractResultSetAdapter
AbstractResultSetAdapter,代理结果集适配器。
public abstract class AbstractResultSetAdapter extends AbstractUnsupportedOperationResultSet { /** * 结果集集合 */ @Getter private final List<ResultSet> resultSets; @Override // TODO should return sharding statement in future public final Statement getStatement() throws SQLException { return getResultSets().get(0).getStatement(); } @Override public final ResultSetMetaData getMetaData() throws SQLException { return getResultSets().get(0).getMetaData(); } @Override public int findColumn(final String columnLabel) throws SQLException { return getResultSets().get(0).findColumn(columnLabel); } // .... 省略其它方法}4. 插入流程
插入使用分布式主键例子代码如下:
// 代码仅仅是例子,生产环境下请注意异常处理和资源关闭String sql = "INSERT INTO t_order(uid, nickname, pid) VALUES (1, '2', ?)";DataSource dataSource = new ShardingDataSource(shardingRule);Connection conn = dataSource.getConnection();PreparedStatement ps = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS); // 返回主键需要 Statement.RETURN_GENERATED_KEYSps.setLong(1, 100);ps.executeUpdate();ResultSet rs = ps.getGeneratedKeys();if (rs.next()) { System.out.println("id:" + rs.getLong(1));}调用 #executeUpdate() 方法,内部过程如下:

是不是对上层完全透明?!我们来看看内部是怎么实现的。
// ShardingPreparedStatement.java@Overridepublic int executeUpdate() throws SQLException { try { Collection<PreparedStatementUnit> preparedStatementUnits = route(); return new PreparedStatementExecutor( getShardingConnection().getShardingContext().getExecutorEngine(), getRouteResult().getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeUpdate(); } finally { clearBatch(); }}#route()分库分表路由,获得预编译语句对象执行单元( PreparedStatementUnit )集合。public final class PreparedStatementUnit implements BaseStatementUnit { /** * SQL 执行单元 */ private final SQLExecutionUnit sqlExecutionUnit; /** * 预编译语句对象 */ private final PreparedStatement statement;}#executeUpdate()调用执行引擎并行执行多个预编译语句对象。执行时,最终调用预编译语句对象( PreparedStatement )。我们来看一个例子:// PreparedStatementExecutor.javapublic int executeUpdate() { Context context = MetricsContext.start("ShardingPreparedStatement-executeUpdate"); try { List<Integer> results = executorEngine.executePreparedStatement(sqlType, preparedStatementUnits, parameters, new ExecuteCallback<Integer>() { @Override public Integer execute(final BaseStatementUnit baseStatementUnit) throws Exception { // 调用 PreparedStatement#executeUpdate() return ((PreparedStatement) baseStatementUnit.getStatement()).executeUpdate(); } }); return accumulate(results); } finally { MetricsContext.stop(context); }}
// ShardingPreparedStatement.javaprivate Collection<PreparedStatementUnit> route() throws SQLException { Collection<PreparedStatementUnit> result = new LinkedList<>(); // 路由 setRouteResult(routingEngine.route(getParameters())); // 遍历 SQL 执行单元 for (SQLExecutionUnit each : getRouteResult().getExecutionUnits()) { SQLType sqlType = getRouteResult().getSqlStatement().getType(); Collection<PreparedStatement> preparedStatements; // 创建实际的 PreparedStatement if (SQLType.DDL == sqlType) { preparedStatements = generatePreparedStatementForDDL(each); } else { preparedStatements = Collections.singletonList(generatePreparedStatement(each)); } getRoutedStatements().addAll(preparedStatements); // 回放设置占位符参数到 PreparedStatement for (PreparedStatement preparedStatement : preparedStatements) { replaySetParameter(preparedStatement); result.add(new PreparedStatementUnit(each, preparedStatement)); } } return result;}/*** 创建 PreparedStatement** @param sqlExecutionUnit SQL 执行单元* @return PreparedStatement* @throws SQLException 当 JDBC 操作发生异常时*/private PreparedStatement generatePreparedStatement(final SQLExecutionUnit sqlExecutionUnit) throws SQLException { Optional<GeneratedKey> generatedKey = getGeneratedKey(); // 获得连接 Connection connection = getShardingConnection().getConnection(sqlExecutionUnit.getDataSource(), getRouteResult().getSqlStatement().getType()); // 声明返回主键 if (isReturnGeneratedKeys() || isReturnGeneratedKeys() && generatedKey.isPresent()) { return connection.prepareStatement(sqlExecutionUnit.getSql(), RETURN_GENERATED_KEYS); } return connection.prepareStatement(sqlExecutionUnit.getSql(), getResultSetType(), getResultSetConcurrency(), getResultSetHoldability());}- 调用
#generatePreparedStatement()创建 PreparedStatement,后调用#replaySetParameter()回放设置占位符参数到 PreparedStatement 当 声明返回主键 时,即
#isReturnGeneratedKeys()返回true时,调用connection.prepareStatement(sqlExecutionUnit.getSql(), RETURN_GENERATED_KEYS)。为什么该方法会返回true?上文例子conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)// ShardingConnection.java@Overridepublic PreparedStatement prepareStatement(final String sql, final String[] columnNames) throws SQLException { return new ShardingPreparedStatement(this, sql, Statement.RETURN_GENERATED_KEYS);}// ShardingPreparedStatement.javapublic ShardingPreparedStatement(final ShardingConnection shardingConnection, final String sql, final int autoGeneratedKeys) { this(shardingConnection, sql); if (RETURN_GENERATED_KEYS == autoGeneratedKeys) { markReturnGeneratedKeys(); }}protected final void markReturnGeneratedKeys() { returnGeneratedKeys = true;}声明返回主键后,插入执行完成,我们调用
#getGeneratedKeys()可以获得主键 :// ShardingStatement.java@Overridepublic ResultSet getGeneratedKeys() throws SQLException { Optional<GeneratedKey> generatedKey = getGeneratedKey(); // 分布式主键 if (generatedKey.isPresent() && returnGeneratedKeys) { return new GeneratedKeysResultSet(routeResult.getGeneratedKeys().iterator(), generatedKey.get().getColumn(), this); } // 数据库自增 if (1 == getRoutedStatements().size()) { return getRoutedStatements().iterator().next().getGeneratedKeys(); } return new GeneratedKeysResultSet();}调用
ShardingConnection#getConnection()方法获得该 PreparedStatement 对应的真实数据库连接( Connection ):// ShardingConnection.java/** * 根据数据源名称获取相应的数据库连接. * * @param dataSourceName 数据源名称 * @param sqlType SQL语句类型 * @return 数据库连接 * @throws SQLException SQL异常 */public Connection getConnection(final String dataSourceName, final SQLType sqlType) throws SQLException { // 从连接缓存中获取连接 Optional<Connection> connection = getCachedConnection(dataSourceName, sqlType); if (connection.isPresent()) { return connection.get(); } Context metricsContext = MetricsContext.start(Joiner.on("-").join("ShardingConnection-getConnection", dataSourceName)); // DataSource dataSource = shardingContext.getShardingRule().getDataSourceRule().getDataSource(dataSourceName); Preconditions.checkState(null != dataSource, "Missing the rule of %s in DataSourceRule", dataSourceName); String realDataSourceName; if (dataSource instanceof MasterSlaveDataSource) { dataSource = ((MasterSlaveDataSource) dataSource).getDataSource(sqlType); realDataSourceName = MasterSlaveDataSource.getDataSourceName(dataSourceName, sqlType); } else { realDataSourceName = dataSourceName; } Connection result = dataSource.getConnection(); MetricsContext.stop(metricsContext); // 添加到连接缓存 connectionMap.put(realDataSourceName, result); // 回放 Connection 方法 replayMethodsInvocation(result); return result;}private Optional<Connection> getCachedConnection(final String dataSourceName, final SQLType sqlType) { String key = connectionMap.containsKey(dataSourceName) ? dataSourceName : MasterSlaveDataSource.getDataSourceName(dataSourceName, sqlType); return Optional.fromNullable(connectionMap.get(key));}- 调用
#getCachedConnection()尝试获得已缓存的数据库连接;如果缓存中不存在,获取到连接后会进行缓存 - 从 ShardingRule 配置的 DataSourceRule 获取真实的数据源( DataSource )
- MasterSlaveDataSource 实现主从数据源封装,我们在下小节分享
- 调用
#replayMethodsInvocation()回放记录的 Connection 方法
- 调用
插入实现的代码基本分享完了,因为是不断代码下钻的方式分析,可以反向向上在理理,会更加清晰。
5. 查询流程
单纯从 core 包里的 JDBC 实现,查询流程 #executeQuery() 和 #execute() 基本一致,差别在于执行和多结果集归并。
@Overridepublic ResultSet executeQuery() throws SQLException { ResultSet result; try { // 路由 Collection<PreparedStatementUnit> preparedStatementUnits = route(); // 执行 List<ResultSet> resultSets = new PreparedStatementExecutor( getShardingConnection().getShardingContext().getExecutorEngine(), getRouteResult().getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeQuery(); // 结果归并 result = new ShardingResultSet(resultSets, new MergeEngine( getShardingConnection().getShardingContext().getDatabaseType(), resultSets, (SelectStatement) getRouteResult().getSqlStatement()).merge()); } finally { clearBatch(); } // 设置结果集 setCurrentResultSet(result); return result;}- SQL执行 感兴趣的同学可以看:《Sharding-JDBC 源码分析 —— SQL 执行》
- 结果归并 感兴趣的同学可以看:《Sharding-JDBC 源码分析 —— 结果归并》
结果归并
#merge()完后,创建分片结果集( ShardingResultSet )public final class ShardingResultSet extends AbstractResultSetAdapter { /** * 归并结果集 */ private final ResultSetMerger mergeResultSet; @Override public int getInt(final int columnIndex) throws SQLException { Object result = mergeResultSet.getValue(columnIndex, int.class); wasNull = null == result; return (int) ResultSetUtil.convertValue(result, int.class); } @Override public int getInt(final String columnLabel) throws SQLException { Object result = mergeResultSet.getValue(columnLabel, int.class); wasNull = null == result; return (int) ResultSetUtil.convertValue(result, int.class); } // .... 隐藏其他类似 getXXXX() 方法}
6. 读写分离
建议前置阅读:《官方文档 —— 读写分离》
当你有读写分离的需求时,将 ShardingRule 配置对应的数据源 从 ShardingDataSource 替换成 MasterSlaveDataSource。我们来看看 MasterSlaveDataSource 的功能和实现。
支持一主多从的读写分离配置,可配合分库分表使用
// MasterSlaveDataSourceFactory.javapublic final class MasterSlaveDataSourceFactory { /** * 创建读写分离数据源. * * @param name 读写分离数据源名称 * @param masterDataSource 主节点数据源 * @param slaveDataSource 从节点数据源 * @param otherSlaveDataSources 其他从节点数据源 * @return 读写分离数据源 */ public static DataSource createDataSource(final String name, final DataSource masterDataSource, final DataSource slaveDataSource, final DataSource... otherSlaveDataSources) { return new MasterSlaveDataSource(name, masterDataSource, Lists.asList(slaveDataSource, otherSlaveDataSources)); }}// MasterSlaveDataSource.javapublic final class MasterSlaveDataSource extends AbstractDataSourceAdapter { /** * 数据源名 */ private final String name; /** * 主数据源 */ @Getter private final DataSource masterDataSource; /** * 从数据源集合 */ @Getter private final List<DataSource> slaveDataSources;}同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。
// ShardingConnection.javapublic Connection getConnection(final String dataSourceName, final SQLType sqlType) throws SQLException { // .... 省略部分代码 String realDataSourceName; if (dataSource instanceof MasterSlaveDataSource) { // 读写分离 dataSource = ((MasterSlaveDataSource) dataSource).getDataSource(sqlType); realDataSourceName = MasterSlaveDataSource.getDataSourceName(dataSourceName, sqlType); } else { realDataSourceName = dataSourceName; } Connection result = dataSource.getConnection(); // .... 省略部分代码}// MasterSlaveDataSource.java/*** 当前线程是否是 DML 操作标识*/private static final ThreadLocal<Boolean> DML_FLAG = new ThreadLocal<Boolean>() { @Override protected Boolean initialValue() { return false; }};/*** 从库负载均衡策略*/private final SlaveLoadBalanceStrategy slaveLoadBalanceStrategy = new RoundRobinSlaveLoadBalanceStrategy();/*** 获取主或从节点的数据源.** @param sqlType SQL类型* @return 主或从节点的数据源*/public DataSource getDataSource(final SQLType sqlType) { if (isMasterRoute(sqlType)) { DML_FLAG.set(true); return masterDataSource; } return slaveLoadBalanceStrategy.getDataSource(name, slaveDataSources);}private static boolean isMasterRoute(final SQLType sqlType) { return SQLType.DQL != sqlType || DML_FLAG.get() || HintManagerHolder.isMasterRouteOnly();}- ShardingConnection 获取到的数据源是 MasterSlaveDataSource 时,调用
MasterSlaveDataSource#getConnection()方法获取真实的数据源 - 通过
#isMasterRoute()判断是否读取主库,以下三种情况会访问主库:- 非查询语句 (DQL)
- 该数据源在当前线程访问过主库:通过线程变量
DML_FLAG实现 - 强制主库:程序里调用
HintManager.getInstance().setMasterRouteOnly()实现
访问从库时,会通过负载均衡策略( SlaveLoadBalanceStrategy ) 选择一个从库
// SlaveLoadBalanceStrategy.javapublic interface SlaveLoadBalanceStrategy { /** * 根据负载均衡策略获取从库数据源. * * @param name 读写分离数据源名称 * @param slaveDataSources 从库数据源列表 * @return 选中的从库数据源 */ DataSource getDataSource(String name, List<DataSource> slaveDataSources);}// RoundRobinSlaveLoadBalanceStrategy.javapublic final class RoundRobinSlaveLoadBalanceStrategy implements SlaveLoadBalanceStrategy { private static final ConcurrentHashMap<String, AtomicInteger> COUNT_MAP = new ConcurrentHashMap<>(); @Override public DataSource getDataSource(final String name, final List<DataSource> slaveDataSources) { AtomicInteger count = COUNT_MAP.containsKey(name) ? COUNT_MAP.get(name) : new AtomicInteger(0); COUNT_MAP.putIfAbsent(name, count); count.compareAndSet(slaveDataSources.size(), 0); return slaveDataSources.get(count.getAndIncrement() % slaveDataSources.size()); }}- MasterSlaveDataSource 默认使用 RoundRobinSlaveLoadBalanceStrategy,暂时不支持配置
- RoundRobinSlaveLoadBalanceStrategy,轮询负载均衡策略,每个从节点访问次数均衡,暂不支持数据源故障移除
666. 彩蛋
没有彩蛋
没有彩
没有
没
下一篇,《分布式事务(一)之最大努力型》走起。老司机,赶紧上车。
道友,分享一个朋友圈可好?不然交个道姑那敏感词你。
- 数据库中间件 Sharding-JDBC 源码分析 —— JDBC实现与读写分离
- 数据库中间件 Sharding-JDBC 源码分析 —— 结果归并
- 数据库中间件 Sharding-JDBC 源码分析 —— SQL 解析(一)之语法解析
- 数据库中间件 Sharding-JDBC 源码分析 —— SQL 解析(二)之SQL解析
- 数据库中间件 Sharding-JDBC 源码分析 —— SQL 解析(三)之查询SQL
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 解析(四)之插入SQL
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 解析(六)之删除SQL
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 路由(一)分库分表配置
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 路由(二)之分库分表路由
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 改写
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— 分布式主键
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 执行
- 数据库中间件 Sharding-JDBC 源码分析 —— 事务(一)之BED
- 数据库shard中间件对比,以及sharding-jdbc 实现原理分析
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 解析(四)之插入SQL解析
- 数据库分库分表中间件 Sharding-JDBC 源码分析 —— SQL 解析(五)之更新SQL解析
- Sharding-JDBC 1.3.0发布——支持读写分离
- Sharding-JDBC读写分离探秘
- 原生ajax的实现
- 网络工程师笔记《三》
- 51nod 1847 奇怪的数学题
- CentOS7--如何搭建LAMP服务环境?
- 批量源数据按时间分片聚合
- 数据库中间件 Sharding-JDBC 源码分析 —— JDBC实现与读写分离
- iOS算法总结-冒泡排序
- 【LeetCode】141.Linked List Cycle(easy)解题报告
- ROS问题总结
- [leetcode]第七周作业
- spring data jpa 定义全局接口BaseDao
- Android Studio查看包依赖关系+删除冲突框架版本(如glide)
- fragment皮毛学习
- WSDL Web服务描述语言


