布隆过滤器浅解
来源:互联网 发布:哪些网络游戏有mac版 编辑:程序博客网 时间:2024/05/17 12:05
1)位数组:
假设Bloom Filter使用一个m比特的数组来保存信息,初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0,即BF整个数组的元素都设置为0。

2)添加元素,k个独立hash函数
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。
当我们往Bloom Filter中增加任意一个元素x时候,我们使用k个哈希函数得到k个哈希值,然后将数组中对应的比特位设置为1。即第i个哈希函数映射的位置hashi(x)就会被置为1(1≤i≤k)。
注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。
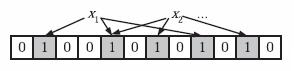
3)判断元素是否存在集合
在判断y是否属于这个集合时,我们只需要对y使用k个哈希函数得到k个哈希值,如果所有hashi(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive。
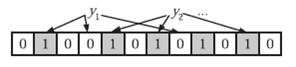
Bloom Filter的缺点:
1)Bloom Filter无法从Bloom Filter集合中删除一个元素。因为该元素对应的位会牵动到其他的元素。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。 此外,Bloom Filter的hash函数选择会影响算法的效果。
2)还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数,即hash函数选择会影响算法的效果。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况 下,m至少要等于n*lg(1/E) 才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应 该>=nlg(1/E)*lge ,大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意:
这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。


- 布隆过滤器浅解
- 关于布隆过滤器
- 布隆过滤器
- 重写布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器
- 布隆过滤器原理
- 布隆过滤器
- 布隆过滤器
- android studio界面初识
- IntelliJ IDEA中关于get、set方法Code template的编辑,用于修改get、set注释
- BZOJ 2142 浅谈LuCas EXtra拓展卢卡斯定理解合数组合式
- HDU1863 最小生成树 prim模版
- 图中的最小生成树——Kruskal算法
- 布隆过滤器浅解
- doctype解析
- Keepalived安装及配置实现虚拟IP与HDFS Active Namenode同步
- Java for循环和foreach循环的性能比较
- bzoj 2423 [HAOI2010]最长公共子序列 动态规划
- Java的初始化块
- 一位资深程序员大牛给予Java初学者的学习路线建议
- 表的创建与管理
- 设计模式中类的关系


