yarn ResourceManager
来源:互联网 发布:家具市场数据分析 编辑:程序博客网 时间:2024/05/18 03:33
阅读本文首先知道什么是YARN,如果不清楚,可以查看为什么会产生yarn,它解决了什么问题,有什么优势
如题:
为什么会产yarn,它解决了什么问题,有什么优势?
简单来讲是因为Mrv1的缺陷,产生yarn。下面详细介绍
Hadoop 和 MRv1 简单介绍
Hadoop 集群可从单一节点(其中所有 Hadoop 实体都在同一个节点上运行)扩展到数千个节点(其中的功能分散在各个节点之间,以增加并行处理活动)。图 1 演示了一个 Hadoop 集群的高级组件。
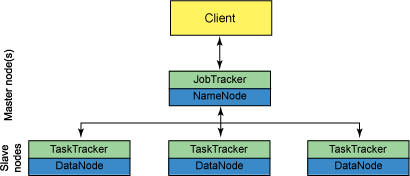
图 1. Hadoop 集群架构的简单演示
一个 Hadoop 集群可分解为两个抽象实体:MapReduce 引擎和分布式文件系统。MapReduce 引擎能够在整个集群上执行 Map 和 Reduce 任务并报告结果,其中分布式文件系统提供了一种存储模式,可跨节点复制数据以进行处理。Hadoop 分布式文件系统 (HDFS) 通过定义来支持大型文件(其中每个文件通常为 64 MB 的倍数)。
当一个客户端向一个 Hadoop 集群发出一个请求时,此请求由 JobTracker 管理。JobTracker 与 NameNode 联合将工作分发到离它所处理的数据尽可能近的位置。NameNode 是文件系统的主系统,提供元数据服务来执行数据分发和复制。JobTracker 将 Map 和 Reduce 任务安排到一个或多个 TaskTracker 上的可用插槽中。TaskTracker 与 DataNode(分布式文件系统)一起对来自 DataNode 的数据执行 Map 和 Reduce 任务。当 Map 和 Reduce 任务完成时,TaskTracker 会告知 JobTracker,后者确定所有任务何时完成并最终告知客户作业已完成。
从 图 1 中可以看到,MRv1 实现了一个相对简单的集群管理器来执行 MapReduce 处理。MRv1 提供了一种分层的集群管理模式,其中大数据作业以单个 Map 和 Reduce 任务的形式渗入一个集群,并最后聚合成作业来报告给用户。但这种简单性有一些隐秘,不过也不是很隐秘的问题。
MapReduce 的第一个版本既有优点也有缺点。MRv1 是目前使用的标准的大数据处理系统。但是,这种架构存在不足,主要表现在大型集群上。当集群包含的节点超过 4,000 个时(其中每个节点可能是多核的),就会表现出一定的不可预测性。其中一个最大的问题是级联故障,由于要尝试复制数据和重载活动的节点,所以一个故障会通过网络泛洪形式导致整个集群严重恶化。
但 MRv1 的最大问题是多租户。随着集群规模的增加,一种可取的方式是为这些集群采用各种不同的模型。MRv1 的节点专用于 Hadoop,所以可以改变它们的用途以用于其他应用程序和工作负载。当大数据和 Hadoop 成为云部署中一个更重要的使用模型时,这种能力也会增强,因为它允许在服务器上对 Hadoop 进行物理化,而无需虚拟化且不会增加管理、计算和输入/输出开销。
我们现在看看 YARN 的新架构,看看它如何支持 MRv2 和其他使用不同处理模型的应用程序。
YARN (MRv2) 简介
为了实现一个 Hadoop 集群的集群共享、可伸缩性和可靠性。设计人员采用了一种分层的集群框架方法。具体来讲,特定于 MapReduce 的功能已替换为一组新的守护程序,将该框架向新的处理模型开放。
回想一下,由于限制了扩展以及网络开销所导致的某些故障模式,MRv1 JobTracker 和 TaskTracker 方法曾是一个重要的缺陷。这些守护程序也是 MapReduce 处理模型所独有的。为了消除这一限制,JobTracker 和 TaskTracker 已从 YARN 中删除,取而代之的是一组对应用程序不可知的新守护程序。
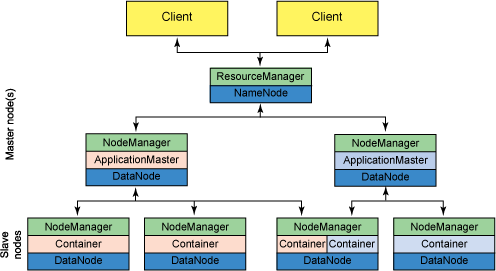
图 2. YARN 的新架构
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
ApplicationMaster 管理一个在 YARN 内运行的应用程序的每个实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
NodeManager 管理一个 YARN 集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过插槽管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。YARN 继续使用 HDFS 层。它的主要 NameNode 用于元数据服务,而 DataNode 用于分散在一个集群中的复制存储服务。
要使用一个 YARN 集群,首先需要来自包含一个应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个 ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster 协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
通过这些讨论,应该明确的一点是,旧的 Hadoop 架构受到了 JobTracker 的高度约束,JobTracker 负责整个集群的资源管理和作业调度。新的 YARN 架构打破了这种模型,允许一个新 ResourceManager 管理跨应用程序的资源使用,ApplicationMaster 负责管理作业的执行。这一更改消除了一处瓶颈,还改善了将 Hadoop 集群扩展到比以前大得多的配置的能力。此外,不同于传统的 MapReduce,YARN 允许使用 Message Passing Interface 等标准通信模式,同时执行各种不同的编程模型,包括图形处理、迭代式处理、机器学习和一般集群计算。
随着 YARN 的出现,您不再受到更简单的 MapReduce 开发模式约束,而是可以创建更复杂的分布式应用程序。实际上,您可以将 MapReduce 模型视为 YARN 架构可运行的一些应用程序中的其中一个,只是为自定义开发公开了基础框架的更多功能。这种能力非常强大,因为 YARN 的使用模型几乎没有限制,不再需要与一个集群上可能存在的其他更复杂的分布式应用程序框架相隔离,就像 MRv1 一样。甚至可以说,随着 YARN 变得更加健全,它有能力取代其他一些分布式处理框架,从而完全消除了专用于其他框架的资源开销,同时还简化了整个系统。
为了演示 YARN 相对于 MRv1 的效率提升,可考虑蛮力测试旧版本的 LAN Manager Hash 的并行问题,这是旧版 Windows® 用于密码散列运算的典型方法。在此场景中,MapReduce 方法没有多大意义,因为 Mapping/Reducing 阶段涉及到太多开销。相反,更合理的方法是抽象化作业分配,以便每个容器拥有密码搜索空间的一部分,在其之上进行枚举,并通知您是否找到了正确的密码。这里的重点是,密码将通过一个函数来动态确定(这确实有点棘手),而不需要将所有可能性映射到一个数据结构中,这就使得 MapReduce 风格显得不必要且不实用。
归结而言,MRv1 框架下的问题仅是需要一个关联数组,而且这些问题有专门朝大数据操作方向演变的倾向。但是,问题一定不会永远仅局限于此范式中,因为您现在可以更为简单地将它们抽象化,编写自定义客户端、应用程序主程序,以及符合任何您想要的设计的应用程序。
可以带着下面问题来阅读本文:
1.YARN通过什么来负责管理和分配集群中资源?
2.ResourceManager有几部分组成?
3.管理员通过什么服务来管理集群?
4.集群默认多长时间未汇报心跳,则认为其死掉?
5.ApplicationACLsManager有几种权限,查看主要查看什么,修改,主要修改什么?
6.ResourceScheduler在YARN中的位置?
在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager

用户交互
NM(NodeManager)管理
AM(ApplicationManager)管理
Application管理
安全管理
资源分配
- yarn ResourceManager
- YARN ResourceManager failover机制
- YARN ResourceManager failover机制
- Yarn中的ResourceManager分析
- Hadoop -YARN ResourceManager 剖析
- Yarn之ResourceManager资源管理
- YARN resourceManager解析
- yarn resourceManager 找不到nodeManager
- YARN/MRv2 ResourceManager代码分析
- YARN/MRv2 ResourceManager代码分析
- Apache Hadoop YARN – ResourceManager
- Apache Hadoop YARN – ResourceManager
- Apache Hadoop YARN – ResourceManager
- YARN (MRv2) ResourceManager High Availability
- BUG:Yarn resourceManager 无法启动
- hadoop2.0(YARN) ResourceManager failover机制
- Hadoop v2(Yarn)调度分析(2)ResourceManager
- YARN ResourceManager调度器的分析
- ndk学习笔记
- 最详细校验
- php+mongodb判断坐标是否在指定多边形区域内的实例
- BZOJ 2815 灾难 (灭绝树)
- Scala学习笔记(一)编程基础
- yarn ResourceManager
- 为您解惑:HTML5中使用MathML数学公式的简单讲解..........
- Sass/SCSS(关系,安装,webstorm配置编译,使用,语法)
- 20171102
- hidden symbol `pthread_atfork' in /usr/lib/x86_64-linux-gnu/libpthread_nonshared.a(pthread_atfork.oS
- 生成一个 有样式的 excel 文件
- statsmodels 安装方法
- android支付宝调用
- vue


