机器学习/深度学习小问题
来源:互联网 发布:今天淘宝怎么不能登录 编辑:程序博客网 时间:2024/05/16 15:15
数据预处理
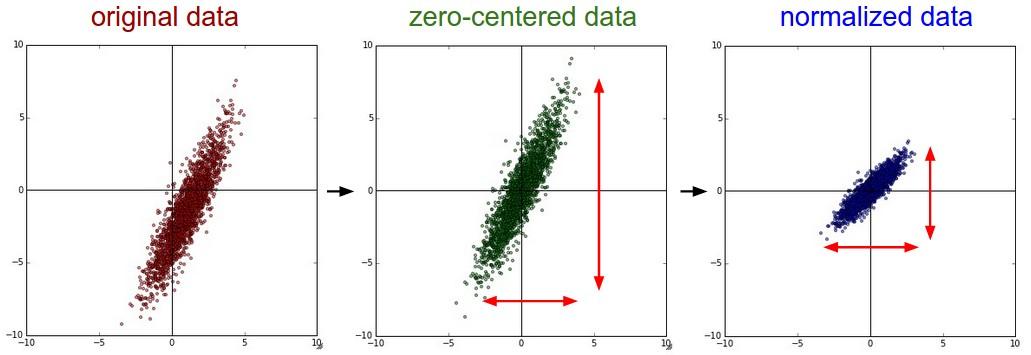
1、为什么数据进行零中心化处理?
以sigmoid激活函数为例。Sigmoid函数的输出不是零中心的。这个性质并不是我们想要的,因为在神经网络后面层中的神经元得到的数据将不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数(比如在f=w^Tx+b中每个元素都x>0),那么关于w的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数(具体依整个表达式f而定),这是因为W的梯度是X,如果X为正则W的梯度为正。这将会导致梯度下降权重更新时出现z字型的下降。然而,可以看到整个批量的数据的梯度被加起来后,对于权重的最终更新将会有不同的正负,这样就从一定程度上减轻了这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
2、为什么数据进行归一化处理?
答:在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。比如在预测房价的问题中,影响房价 Y 的因素有房子面积X1、卧室X2数量等,我们得到的样本数据就是这样一些样本点,这里的(X1,X2)又被称为特征。很显然,这些特征的量纲和数值得量级都是不一样的,在预测房价时,如果直接使用原始的数据值,那么他们对房价的影响程度将是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了。
简言之,当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
其实,在不同的问题中,中心化和标准化有着不同的意义:
比如在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛。
另外,对于主成分分析(PCA)问题,也需要对数据进行中心化和标准化等预处理步骤。
https://www.zhihu.com/question/37069477/answer/132387124
loss function
1、softmax与交叉熵的理解?
- 机器学习/深度学习小问题
- 深度学习,机器学习面试问题
- 机器学习&深度学习
- 机器学习&深度学习
- 机器学习&&深度学习
- 机器/深度学习基础
- 深度学习机器选择
- 关于机器学习&深度学习的一些问题,求教。
- 机器学习岗位面试问题汇总 之 深度学习
- 机器学习、深度学习、数据挖掘——问题集锦
- 机器学习和深度学习入门问题形象解答
- 机器学习、深度学习概念
- 面试:机器学习--深度学习
- 机器学习之深度学习
- 深度学习&&机器学习&&模式识别
- 机器学习&深度学习资料
- 深度学习 血战 机器学习
- 机器学习 vs. 深度学习
- ubuntu下同时安装anaconda2与anaconda3,并分别安装与之对应的tensorflow
- 使用js触发事件
- prometheus学习笔记(一)
- C++多态实现机制
- Android Studio颜色选择器selector
- 机器学习/深度学习小问题
- prometheus学习笔记(二)
- python format
- 多线程死锁的产生原因及避免
- 计算机网络最简单的定义
- Ubuntu 16.04 Apache https设置及SSL免费证书安装
- 帧率设置 及在游戏运行时显示帧率
- mybatis多表查询
- Java知识点简记(1)面向对象


