http协议详解及操作
来源:互联网 发布:360秒收录网站源码 编辑:程序博客网 时间:2024/05/21 09:59
互联网,绝大多数的Web开发,都是构建在HTTP协议之上的Web应用,核心就是不同构建在TCP/IP协议基础上的http请求。固本求原,本篇文章将对http协议进行整理学习、然后使用代码去操作。
1.http协议
1.1如何工作
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
一个HTTP”客户端”是一个应用程序(Web浏览器或其他任何客户端),通过连接到服务器达到向服务器发送一个或多个HTTP的请求的目的。
一个HTTP”服务器”同样也是一个应用程序(通常是一个Web服务,如Apache Web服务器或IIS服务器等),通过接收客户端的请求并向客户端发送HTTP响应数据。
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
以下图表展示了HTTP协议通信流程: 
因此,该协议就是客户端和服务器交换数据的一揽子标准。
1.1.1客户端的http请求
可以是浏览器发起请求,也可以是程序代码去发起。
1.1.2服务器的http响应
HTTP响应也由四个部分组成,分别是:状态行、消息报文、空行和响应正文。 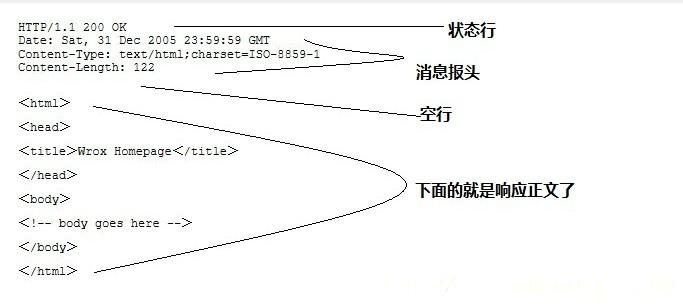
1.3HTTP协议的报文
HTTP消息由客户端到服务器的请求和服务器到客户端的响应组成,请求和响应由HTTP报文传递,报文是简单的格式化数据块。
起始行和首部就是由行分隔的ASCII文本。每行都以一个由两个字符组成的行终止序列作为结束,其中包括一个回车符(ASCII码13)和一个换行符(ASCII码10)。
请求消息和响应消息都是由以下内容组成:
- 起始行(对于请求消息,开始行就是请求行,对于响应消息,开始行就是状态行)
- 消息报文(首部)(可选)
- 空行(只有CRLF的行)
- 消息正文(主体)(可选)

如图,一个请求报文的示意: 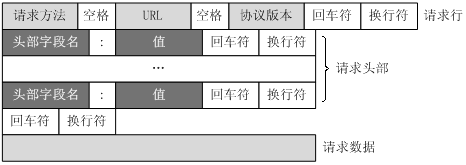
每一个报文域都是由名字+“:”+空格+值 组成,消息报文域的名字是大小写无关的。
如图:一个访问百度的请求报文和响应报文(header)

HTTP消息报文包括普通报文、请求报文、响应报文、实体报文。
###1.3.1.普通报文在普通报文中,有少数报文域用于所有的请求和响应消息,但并不用于被传输的实体,只用于传输的消息。eg:Cache-Control 用于指定缓存指令,缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是独立的(一个消息的缓存指令不会影响另一个消息处理的缓存机制),HTTP1.0使用的类似的报文域为Pragma。请求时的缓存指令包括:no-cache(用于指示请求或响应消息不能缓存)、no-store、max-age、max-stale、min-fresh、only-if-cached;响应时的缓存指令包括:public、private、no-cache、no-store、no-transform、must-revalidate、proxy-revalidate、max-age、s-maxage.###1.3.2.请求报文请求报文允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。1.3.3.响应报文
响应报文允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识的资源进行下一步访问的信息。
1.3.4.实体报文
请求和响应消息都可以传送一个实体。一个实体由实体报文域和实体正文组成,但并不是说实体报文域和实体正文要在一起发送,可以只发送实体报文域。
HTTP实体的组成:实体首部和实体主体。
实体首部:描述了HTTP报文的内容实体主体:实体主体即原始数据1.3.4.1实体首部
Allow:列出了可以对此实体执行的请求方法
Location:告知客户端实体实际上位于何处,用于将接收端定向到资源的位置(URL)上去
Content-Base:解析主体中的相对URL时使用的基础URL
Content-Encoding:对主体执行的任意编码方式
Content-Language:理解主体时最适宜使用的自然语言
Content-Length:主体的长度
Content-Location:资源实际所处的位置
Content-MD5:主体的MD5校验和
Content-Range:在整个资源中此实体表示的字节范围
Content-Type:这个主体的对象类型
ETag:与此实体相关的实体标记
Expires:实体不再有效,要从原始的源端再次获取实体的日期和时间
Last-Modified:这个实体最后一次被修改的日期和时间
1.3.4.2.实体的主体
该部分其实就是HTTP要传输的内容,是可选的。HTTP报文可以承载很多类型的数字数据,比如,图片、视频、HTML文档电子邮件、软件应用程序等等。
这是大头。但是描述的信息很少,说明http并不是很care你传输的是什么东西,它就是一个负责运输的工具。
1.3.5状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
HTTP状态码的英文为HTTP Status Code。 下面是常见的HTTP状态码:
2用Python操作http请求
2.1python处理http的包选型
根据前人踩坑描述,Python 3 处理HTTP请求的包:http,urllib,urllib3,requests。
http是偏低层的,一般不使用。
下面摘录官网的document地址:
http: https://docs.python.org/3/library/http.html
urllib也是一个包,里面含有多个模块:urllib.request,urllib.error,urllib.parse,urllib.robotparser。
这里的urllib.request 跟python 2.X 的urllib2有点像。urllib.request 基于http.client,但是比 http.client 更高层一些。
urllib:https://docs.python.org/3/library/urllib.html
相比python的标准库,urllib3有很多很重要的特性,比如线程安全等。同时urllib3也很强大而且易于使用。
urllib3:https://pypi.python.org/pypi/urllib3
Requests 基于urllib3,号称“Requests is an elegant and simple HTTP library for Python, built for human beings.”,意思就是专门为人类设计的HTTP库。
Requests:http://docs.python-requests.org/en/latest/index.html
选型结论:requests和urllib3
http://docs.python-requests.org/en/latest/user/quickstart/
https://urllib3.readthedocs.io/en/latest/user-guide.html
剩下的事就简单了,在document里面翱翔一番。
2.2urllib3
我作为爬坑的,我说还是不要用它了,不方便。urllib3默认不支持https,支持也可以,请你做点额外的工作。user-guide上都有。
# -*- coding: utf-8 -*-'''学习使用urlib3,集合了大部分方法的使用Demo.by windanchaos'''import urllib3'''You’ll need a PoolManager instance to make requests. This object handles all of the details of connection pooling and thread safety.'''http = urllib3.PoolManager()# make a request use request()# request() returns a HTTPResponse object# HTTPResponse返回了http的表头headers\状态码status\实体data.# 定义超时和重试次数r1 = http.request('GET', 'http://www.baidu.com',timeout=4.0,retries=10)r2 = http.request('GET', 'http://httpbin.org/robots.txt')print(r1.status)# headers 是header的dictprint(r1.headers)print(r1.data)print(r2.status)print(r2.headers)print(r2.data)# 请求数据的组织,下面访问baidu,使用手机端的User-Agent组织请求报头,返回的data就是移动端的了agent={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) \ Version/9.0 Mobile/13B143 Safari/601.1'}r3 = http.request('GET', 'http://www.baidu.com', headers=agent)print(r3.data)# post和put请求,需要自己encode请求的参数from urllib import urlencodeimport jsonencoded_args = urlencode({'arg': 'value'})url4 = 'http://httpbin.org/post?' + encoded_argsr4 = http.request('POST', url4)print(json.loads(r4.data.decode('utf-8'))['args'])# 当然如果是form数据,urllib3也可以帮你encode,如:r5 = http.request('POST', 'http://httpbin.org/post', fields={'field': 'value'})print(json.loads(r5.data.decode('utf-8'))['form'],r5.status)# post json demodata = {'attribute': 'value'}encoded_data = json.dumps(data).encode('utf-8')r6 = http.request('POST', 'http://httpbin.org/post', body=encoded_data, headers={'Content-Type': 'application/json'})print(json.loads(r6.data.decode('utf-8'))['json'])# post file and binary data'''For uploading files using multipart/form-data encoding you can use the same approach as Form data and specify the file field as a tuple of (file_name, file_data)'''with open('example.txt') as fp: file_data = fp.read()r7 = http.request('POST','http://httpbin.org/post', fields={'filefield': ('example.txt', file_data, 'text/plain')})json.loads(r7.data.decode('utf-8'))['files']'''For sending raw binary data simply specify the body argument. It’s also recommended to set the Content-Type header'''with open('example.jpg', 'rb') as fp: binary_data = fp.read()r8 = http.request('POST','http://httpbin.org/post',body=binary_data,headers={'Content-Type': 'image/jpeg'})json.loads(r8.data.decode('utf-8'))['data']# 对ssl默认是不支持的。需要提供额外的配置或下载额外的包。# log & Errors & Exceptions¶'''If you are using the standard library logging module urllib3 will emit several logs. In some cases this can be undesirable. You can use the standard logger interface to change the log level for urllib3’s logger>>>logging.getLogger("urllib3").setLevel(logging.WARNING)>>> try:... http.request('GET', 'nx.example.com', retries=False)>>> except urllib3.exceptions.NewConnectionError:... print('Connection failed.')'''2.3requests
文章超长了。转到下一篇继续。
Reference参考文献(网页):
http://www.runoob.com/http/http-tutorial.html
http://www.cnblogs.com/li0803/archive/2008/11/03/1324746.html
http://tools.jb51.net/table/http_status_code
http://www.cnblogs.com/miniren/p/5885393.html
- http协议详解及操作
- Http协议及TCP/IP协议详解
- Web资源访问及HTTP协议详解
- Web资源访问及HTTP协议详解
- Web资源访问及HTTP协议详解
- HTTP协议头及错误码详解
- 【http】http协议详解
- 浏览器 HTTP 协议缓存机制详解及Http协议预处理工具类
- web资源访问过程及http协议详解
- HTTP 协议详解 (增删减及标注)
- HTTP协议详解 及用ping命令ping网络
- Java web 入门知识 及HTTP协议详解
- Telnet操作HTTP协议
- 网络协议-HTTP协议详解
- HTTP协议-http事务详解
- HTTP协议详解----HTTP消息
- Http协议详解
- HTTP协议详解
- 自定义组件
- HDU-2013(蟠桃记)
- 奇异值分解 VS 特征值分解
- 【R】R-Shinny的一些笔记
- go语言获取exe文件执行路径
- http协议详解及操作
- 20171105考试总结
- 求2个正整数之和
- PAT乙级题1023.组个最小数
- uboot的配置和编译文件解析
- VideoJS 网页直播实现双击全屏
- C语言结构体中最后一个成员为char[1]或char[0]
- Leetcode: 300. Longest Increasing Subsequence
- 周志华《Machine Learning》学习笔记(9)--EM算法


