Scrapy架构简述
来源:互联网 发布:初始化磁盘数据错误 编辑:程序博客网 时间:2024/05/29 08:21
瞅一眼官方文档给出的架构图,此图中包含了Scrapy框架的基本组件构成以及数据流的走向。 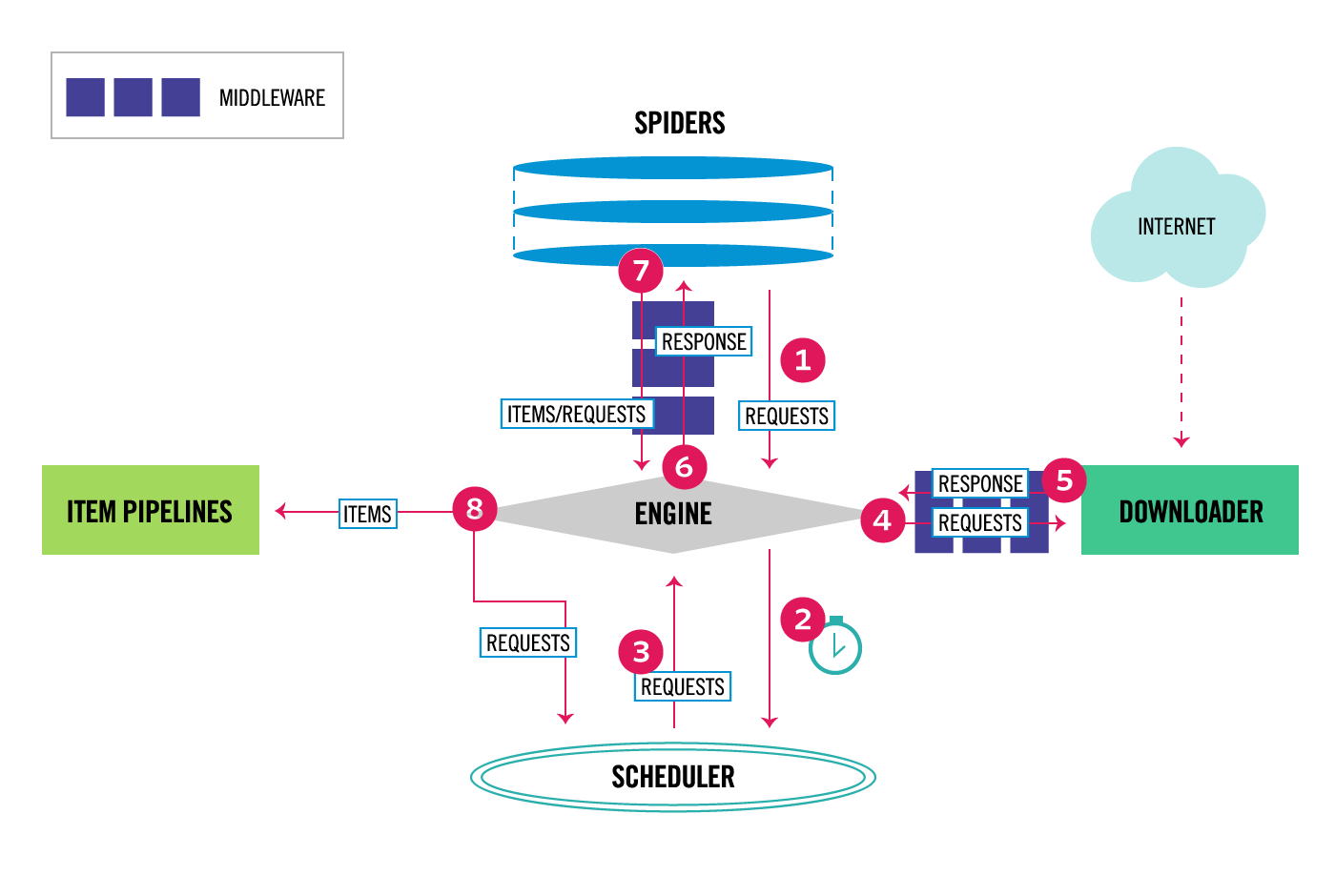
第一眼看过去,有点蒙逼是正常的,接着往下看看就会会理解了。
先了解了解每个组件是做什么的:
Spiders(爬虫类): Spiders是开发者自定义的一个类,用于解析相应并提取item或下个爬取的URL
Scrapy Engine(引擎): Engine负责控制数据流在系统中的流动走向,并在指定条件下触发一些事件。同时,也可以简单理解为Scrapy中数据流的中转站
Scheduler(调度器): Scheduler接收Engine发出的requests,并将这些requests放入到处理队列中,以便之后Engine需要时再提供
Downloader(下载器): Downloader负责抓取网页信息并提供给Engine,进而转发至Spider
Item Pipeline(处理管道): Item Pipeline负责处理Spiders类处理提取之后的item,典型的处理有数据清洗,验证以及持久化
下面需要在介绍一下架构中存在的两种中间件
Spider middlewares: Spider中间件作为Spider和Engine中间存在的特定钩子,处理Engine返回的responses和自身向Engine输出的requests、items
Downloader middlewares: Downloader中间件作为Engine和Downloader中间存在的特定钩子,处理从Engine发出的requests和自身向Engine返回的responses
在后期的讲解中,会慢慢涉及中间件的开发,并利用中间件方便的完成许多功能
重点讲解一下整个架构的数据流的流通过程(看图理解):
1. Engine从Spider获取到第一条Requests
2. Engine将这条Requests发送至Scheduler,然后从Spider准备接收下一条Requests
3. Schedulers取出队列中的一条Requests发送给Engine
4. Engine 将接收到的Requests发送至Downloader,这个过程Requests会经过Downloader Middlewares
5. 一旦页面完成下载,Downloader会成为一个Response,然后将它发送至Engine,这个发送过程也会经过Downloader Middlewares
6. Engine接收到Response后,将它发送至Spider进行处理,会经过Spider Middlewares
7. Spider处理完Response然后返回items和新的Requests至Engine,会经过Spider Middlewares
8. Engine将接收到的Item发送至Item Pipelines,然后将Requests发送至Scheduler并准备接收下一条需要爬取的Requests
9. 一次url的爬取过程结束了,然后会重复这个爬取过程,直到Schedueler中没有Requests需要处理。
通过这篇文章的阅读,可以大概了解Scrapy框架基本构成及数据流的走向。对后续Scrapy的学习会有非常大的帮助,同时为进阶的Scrapy学习及源码的剖析打下基础。
- Scrapy架构简述
- scrapy架构
- 简述安装scrapy的方法
- Scrapy的架构
- scrapy 架构详解
- scrapy 架构详解二
- Scrapy架构概览
- scrapy架构设计分析
- Scrapy的架构初探
- scrapy架构初探
- Scrapy爬虫架构图解
- Scrapy核心架构
- scrapy框架架构
- 多层架构简述
- 游戏服务器架构简述
- Facebook架构简述
- Heritrix架构简述
- 简述三层架构
- sd卡烧录系统后容量下降解决办法
- Qt之根据扩展名获取文件图标、类型
- 多线程下载httpurlConnection
- 普通二极管伏安特性和肖特基二极管电压电流特性
- 【观察】联想数据中心业务整体布局见成效 背后的动能和势能
- Scrapy架构简述
- NOIP2017 游记 Day 1
- 该如何学习java-IO流
- U3D Shader Forward Path光源存储信息
- Boyer-Moore BM算法(普林斯顿算法课Algorithm2-part II:Substring Search)
- C++创建对象及注意事项
- BFS/DFS引出A*算法
- 2017CCPC 秦皇岛比赛总结
- redis五大类型用法


