LabelEncoder和OneHotEncoder 在特征工程中的应用
来源:互联网 发布:ai软件描边 编辑:程序博客网 时间:2024/06/06 00:51
对于一些特征工程方面,有时会用到LabelEncoder和OneHotEncoder。
比如kaggle中对于性别,sex,一般的属性值是male和female。两个值。那么不靠谱的方法直接用0表示male,用1表示female 了。上面说了这是不靠谱的。
所以要用one-hot编码。
首先我们需要用LabelEncoder把sex这个属性列里面的离散属性用数字来表示,就是上面的过程,把male,female这种不同的字符的属性值,用数字表示。
以titanic 里面的train数据集为例.


Step1和step2解决的就是先fit所有样本的Sex属性值,就知道有多少个不同的属性值,有male和female,就用0和1表示,假如有3个不同的值,就用0,1,2表示。step2中transform操作就是转为数字表示形式。
但是转换成这样还不行,上面说过了,这样直接用数字表示的话,是不合理的,至于为什么不合理,待会引入scikit learn 中的原文。所以再把这些数字转化为one-hot编码形式。
这里就用OneHotEncoder

.png)
两行代码就把数值型表示转为了one-hot编码形式。
下面引入scikit learn中的OneHotEncoder的介绍。
http://scikit-learn.org/stable/modules/preprocessing.html#preprocessing
具体内容看上面链接,下面转载这个博客对一些文字的翻译
http://blog.csdn.net/google19890102/article/details/44039761
一、One-Hot Encoding
One-Hot编码,又称为一位有效编码,主要是采用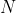 位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
有如下三个特征属性:
二、One-Hot Encoding的处理方法
三、实际的Python代码
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
- 性别:["male","female"]
- 地区:["Europe","US","Asia"]
- 浏览器:["Firefox","Chrome","Safari","Internet Explorer"]
对于某一个样本,如["male","US","Internet Explorer"],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是思维的,这样,我们可以采用One-Hot编码的方式对上述的样本“["male","US","Internet Explorer"]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。
然后我主要介绍一下源文档的代码,
import numpy as np from sklearn.preprocessing
import OneHotEncoder
enc = OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2]])
print"enc.n_values_ is:",enc.n_values_
print"enc.feature_indices_ is:",enc.feature_indices_
printenc.transform([[0, 1, 1]]).toarray()
enc.n_values_ is: [23 4]
enc.feature_indices_ is: [02 5 9]
[[ 1. 0. 0. 1. 0. 0. 1. 0. 0.]]
这个代码很容易理解,简单解释一下没我一开始也没整明白。
首先由四个样本数据[0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2],共有三个属性特征,也就是三列。比如第一列,有0,1两个属性值,第二列有0,1,2三个值.....
那么enc.n_values_就是每个属性列不同属性值的个数,所以分别是2,3,4
再看enc.feature_indices_是对enc.n_values_的一个累加。
再看[0, 1, 1]这个样本是如何转换为基于上面四个数据下的one-hot编码的。
第一列:0->10
第二列:1->010
第三列:1->0100
简单解释一下,在第三列有,0,1,2,3四个值,分别对应1000,0100,0010,0001.
阅读全文
0 0
- LabelEncoder和OneHotEncoder 在特征工程中的应用
- python 数据处理中的 LabelEncoder 和 OneHotEncoder
- sklearn.preprocessing.LabelEncoder和onehotencoder
- sklearn.preprocessing中 LabelEncoder 和 OneHotEncoder区别
- Sklearn中LabelEncoder与OneHotEncoder
- LabelEncoderm OneHotEncoder 在python中的运用
- 基于sklearn的序列处理 : LabelEncoder 与 OneHotEncoder
- iOS_11_XMPP在工程中的应用
- 广告学中的特征工程
- 所涉及到的几种 sklearn 的二值化编码函数:OneHotEncoder(), LabelEncoder(), LabelBinarizer(), MultiLabelBinarizer()
- 所涉及到的几种 sklearn 的二值化编码函数:OneHotEncoder(), LabelEncoder(), LabelBinarizer(), MultiLabelBinarizer()
- OneHotEncoder
- 自然语言处理中的文本处理和特征工程
- 细胞工程在植物组织培养中的应用
- 选项卡在工程中的应用
- 时频分析在工程中的应用
- Kotlin在Android工程中的应用
- Kotlin在Android工程中的应用
- C语言实验——打印数字图形
- 如何编写测试用例(笔记)
- 爬虫系列3网站构建技术类型
- codeforces 651A python
- Android学习日记0_ 环境搭建、单元测试、注解
- LabelEncoder和OneHotEncoder 在特征工程中的应用
- Git版本管理--GitHub
- 1023. 组个最小数 (20)
- 数据结构实验之二叉树六:哈夫曼编码
- 音乐检索(听歌识曲)实现过程
- 数据分析
- SWPU CTF 2017 Web WriteUp
- ros机器人开发概述
- PAT (Basic Level) Practise (中文)1002


