统计学习知识---感知机学习算法的拓展(非线性可分数据问题)
来源:互联网 发布:好医生app软件 编辑:程序博客网 时间:2024/05/21 17:13
感知机算法中的优化方法的几何解释
本部分参考台湾大学林轩田教授机器学习基石课程—PLA部分
PLA算法只有在出现错误分类的时候,才去调整w和b的值,使得错误分类减少。假设我们遇到的数据点(xn,yn)是我们第t次分类错误,那么就有因为是二分类问题,所以只会出现以下两种错误分类的情况: 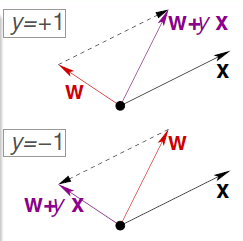
- 第一种:当yn=+1 时,则我们的错误结果为wTxn=wt∗xn=||w||∗||xn||∗cosΘ<0,即cosΘ<0 则Θ太大,为了能过纠正错误,决定减小Θ,就让w(t+1)=wt+x,紫色为改正之后的w(t+1)
- 同理,对于第二种情况,当yn=-1的时候,则我们的错误结果为wTxn=wt∗xn=||w||∗||xn||∗cosΘ>0,即cosΘ>0 则Θ太小,为了能过纠正错误,决定增大Θ,就让w(t+1)=wt-x,紫色为改正之后的w(t+1)。
综上所述,当分割线遇到点(xn,yn)时,如果分割正确,那么wt就不变,如果分割错误,那么就令
(注意w是分割线wTx=0的法线,也就是说分割线的方向是与w的方向垂直的。。。)
思考
PLA 的优点是算法思路比较简单,易于实现。然而这个算法最大的缺点是假设了数据是线性可分的,然而事先并无法知道数据是否线性可分的。假如将PLA 用在线性不可分的数据中时,会导致PLA永远都无法对样本进行完全正确分开从而陷入到死循环中。
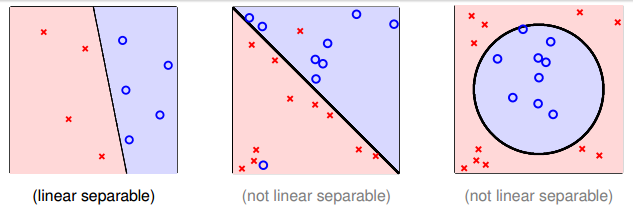
如下图所示,当实例点并不是线性可分的时候,根本找不到一条直线或者一个超平面来完全划分开两类数据,只能利用曲线或者超曲面来划分。
为了避免上面线性不可分的情况,将PLA的条件放宽一点,不再要求所有的样本都能正确的分开,而是要求犯错误的样本尽可能的少,即将问题变为了:
也是就是说去寻找一条犯错误最少的线或者超平面。
其实,从实际意义上,是不能的。这是一个著名的NP hard 问题!!!因为线有无穷多个啊!!!无法求得其最优解,因此只能求尽可能接近其最优解的近似解。林教授的课程讲义中提出的一种求解其近似解的算法 Pocket Algorithm(口袋算法,一种贪心算法)。
Pocket Algorithm(口袋算法)
口袋算法基于贪心的思想,他总是让遇到的最好的线(或者超平面)拿在自己手里。简单介绍一下:首先,我们有一条分割线wt,将数据实例不断带入,发现数据点(xn,yn)再上面出现错误分类,那么我们就纠正分割线得到w(t+1),然后我们让wt和w(t+1)遍历所有的数据,看一下哪条线犯的错误少,那么就让w(t+1)代替wt,否则wt不变。
那么如何让算法停下来呢?
由于口袋算法得到的线越来越好(PLA就不一定了,PLA是最终结果最好,其他情况就不一定是什么样子,不一定是越来越好),所以我们就自己规定迭代的次数。

思考?
- 1
- 2
与PLA的比较:
- 1
- 2
- 3
- 4
代码实现
下面,我们用Python来实现pocket Algorithm算法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
实验结果:Weights:[-0.43701921 -0.10683611 0.34784736]
Intercept Value: -1.0
Minimum Number Of Errors:935

上图的第一幅表示的是每次迭代时的出错数,第二幅图表示的每次更新权重时的出错数。通过上图可以观察到,在7000次迭代过程中,每次迭代出错数是不固定的,而每次更新时出错数是递减的。而且,7000词迭代过程中只有十次左右的更新操作。
参考资料:
1、机器学习基石—PLA
2、台湾大学林轩田教授机器学习基石课程理解及python实现—-PLA
3、分类系列之感知器学习算法PLA 和 口袋算法Pocket Algorithm
4、听课笔记(第二讲): Perceptron-感知机 (台湾国立大学机器学习基石)
- 统计学习知识---感知机学习算法的拓展(非线性可分数据问题)
- 感知机学习算法的拓展---非线性可分数据问题
- 统计学习算法--感知机
- 统计学习方法---感知机算法拓展(神经网络)
- 机器学习(统计学习方法)7 【感知机学习算法】
- 统计学习-感知机
- 统计学习笔记(二)感知机
- 数据可续--统计知识学习--转载知乎
- 非线性可分数据最优超平面的构建
- 统计学习方法学习--感知机
- 感知机学习算法
- 感知机学习算法
- 感知机算法拓展---神经网络
- 感知机学习算法的对偶形式
- 感知机学习算法的原始形式
- 感知机学习算法的对偶形式
- 感知机学习算法的简单实现(Python)
- 整理:统计学习-2 感知机知识准备(模型类型、超平面与梯度下降法)
- 06.奇特的一生评语
- SQL Server 2008 R2导出数据脚本的方法
- @suppressWarnings("unchecked") java 中是什么意思
- Express+Nodejs 下的登录拦截实现
- Linux 系统命令及shell脚本1
- 统计学习知识---感知机学习算法的拓展(非线性可分数据问题)
- java集合框架03--LinkedList和源码分析
- H3C-QoS实例一:基于ACL实现报文过滤
- 前端自适应http或https
- ListView加载实时数据闪烁的问题
- photoshop中图层叠加算法
- 我们也说说Android.mk(6)
- cordova 编译安卓的时候报sdk的问题
- Git的安装和使用


