【计算机视觉之三】运用k近邻算法进行图片分类
来源:互联网 发布:js 淘宝左侧 分类导航 编辑:程序博客网 时间:2024/06/05 10:00
这篇文章主要给不知道计算机视觉是啥的人介绍一下图像分类问题以及最近的最近邻算法。
目录
- 图像分类
1.1 图像分类的原理
1.2 面临的问题
1.3 图像分类任务 - 最近邻算法
- 代码实现
- L2距离
- 用k-近邻进行图片分类
5.1 k近邻分类原理
5.2 超参数的选取 - 小结一下最近邻和k近邻
1.图像分类
1.1 图像分类的原理
计算机视觉中的核心问题是给定一张图片的类别,新来一张图片,希望识别图片中物品的类别,比较受欢迎的计算机视觉方面的任务有物体检测,图像分割等。
举个小栗子
图像数据必须要被计算机识别,所以要把图片转化成矩阵,这时候就会有很多问题了。
在下面这张图片中,是使用了一个图片分类模型分类,然后输出这张图片属于那个类别的概率,一共有四个类别(cat,dog,hat,mug)。一张图片可以用可以用一个非常大的三维数组表示,表征的是像素,在下面这张图片中,转化为 数组就是248X400的,同时呢,图片是有颜色分别的,因此多出来了三个颜色通道,分别是红,绿,蓝(RGB),因此一张图片一般用248X400X3表示,后面的3代表颜色通道,一共有297600个数,每个数都是在0-255的范围内。我们的目的就是把这样成千上万维的数分类,输出一个是猫还是狗的类别标签。

1.2 面临的问题
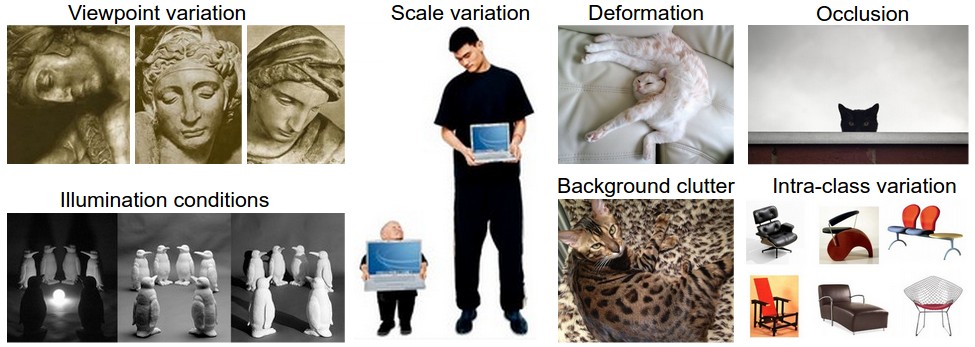
当照相的时候,摄像头换个角度,拍出来的图片不一样,但猫还是同一只猫,或者一些背景色的也会影响计算机识别。
还有像一些物体的形状不同,却是同以物体,计算机也很难识别。
或者是躲在草丛里的猫,这些图片人一眼就能识别,但计算机却很难识别。

还有很多问题,总之,计算机视觉还有很长一段路要走。哈哈
1.3 图像分类任务
图像分类简单来说就是输入一个表征一张图片的数组,然后输出这张图片所属的类别,总结来说可以分为一下三步:
输入:我们的输入是一个有N张图片组成的集合,每张图片都给了一个特定的类别标签,我们称这样的数据为训练集。
学习:我们的目的就是让模型学习这些图片大概是什么样子,然后记下来。我们称这一步为训练模型。
评估:这一步主要是看我们训练的模型到底好不好。主要内容就是利用上一步训练得来的模型预测一个模型没看过的数据集的标签,然后拿这些标签和真正的标签,我们希望预测出来的这些跟真正的标签尽可能一致。
2.最近邻算法
下来看一下图像分类中的常用算法—最近邻算法
最近邻算法在图像分类中非常简单粗暴,我们用斯坦福大学公布的数据,总共有6万张32X32X3的图片数据,有十个类别,每张图片都属于这十个类别中的一个,我们可以用5000张作为训练集,用1000万张作为测试集。用最近邻算出和该类别中最类似的图片。 
用最近邻算出的结果如上右图,可以发现还是有很多分类错的。
最近邻算法的原理很简答,在训练的时候就是光记住每个类别的数据,然后预测的时候算一下测试集中的图片与训练集中的每一张图片的距离,然后看一下跟他距离最近的训练集中的图片的类别,这个类别就是我们要预测的类别。
那距离应该怎么计算呢?一般可以把这个32X32X3的数组展开,然后用距离计算公式计算两个向量之间的距离,L1距离可以表示为:
看一下它具体是怎么做的: 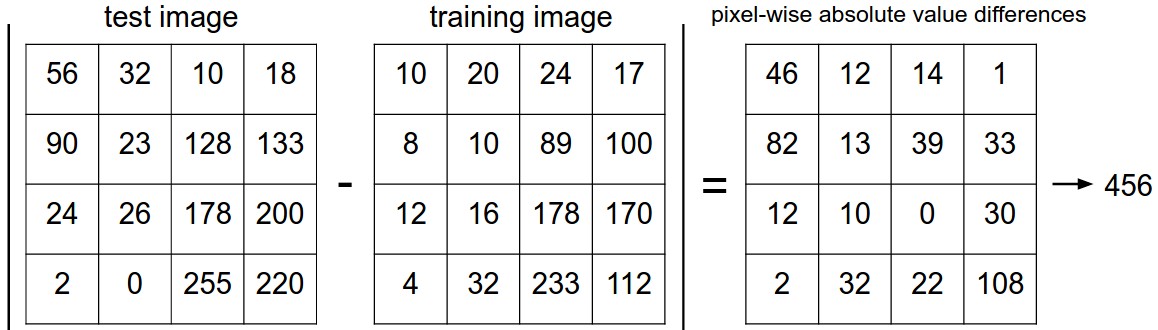
这是一个颜色通道里的L1距离计算,其实就是对应位置上相减,然后把每个方格里的数加起来。
3.代码实现
让我们看一下怎么在代码中实现最近邻算法分类,我们把数据导入,分为四个数组,分别为训练集/标签,和测试集/标签。其中Xtr包含了所有的50000张图片数据,Ytr为一维数组,包含了这50000张数据的标签(0-9).
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # 斯坦福大学的课程代码中提供的函数来导入数据# 把所有图片变为一维向量Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows 变成 50000 x 3072Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows 变成 10000 x 3072既然我们已经把图片数据都转为1维数组,那就可以训练模型并且评估了。
nn = NearestNeighbor() # 创建一个最近邻分类器的类,相当于初始化nn.train(Xtr_rows, Ytr) # 把训练数据给模型,训练Yte_predict = nn.predict(Xte_rows) # 预测测试集的标签# 算一下分类的准确率,这里取的是平均值print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )注意一下我们的衡量标准是准确率,他是分类正确的样本占总测试样本的比例。注意一下我们建的模型,几乎所有模型都有一个操作,那就是train(X,y),就是输入训练数据和标签,让模型学习一个判断标准,判断这张图像是那个类别的。然后,还有有一个predict(X)的操作,他接收一份跟训练数据一样样式的数据,然后预测这些数据的标签是什么样子的。
下面这段代码是用L1距离来计算的:
import numpy as npclass NearestNeighbor(object): def __init__(self): pass def train(self, X, y): #X是NXD的数组,其中每一行代表一个样本,Y是N行的一维数组,对应X的标签 # 最近邻分类器就是简单的记住所有的数据 self.Xtr = X self.ytr = y def predict(self, X): #X是NXD的数组,其中每一行代表一个图片样本 #看一下测试数据有多少行 num_test = X.shape[0] # 确认输出的结果类型符合输入的类型 Ypred = np.zeros(num_test, dtype = self.ytr.dtype) # 循环每一行,也就是每一个样本 for i in xrange(num_test): # 找到和第i个测试图片距离最近的训练图片 # 计算他们的L1距离 distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) min_index = np.argmin(distances) # 拿到最小那个距离的索引 Ypred[i] = self.ytr[min_index] # 预测样本的标签,其实就是跟他最近的训练数据样本的标签 return Ypred如果你运行这个代码,你会发现我们的准确率大约在38.6%左右,貌似比胡乱猜好很多,如果是人来识别的话,准确率大约会有94%,而卷积神经网络已经可以达到95%的准确率,可以看一下kaggle这个比赛,已经达到95%了
4 .L2距离
向量之间的距离计算除了L1距离之外,还可以使用L2距离:
因为平方根对应的是单调函数,它能在缩放距离的绝对大小的同时保留顺序。
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))5.用k-近邻进行图片分类
5.1 k近邻分类原理
你可能会很好奇,当我们预测的时候只用训练集中最接近的样本的标签作为预测结果。事实上,用k-近邻算法可能会得到更好的结果。原理很简单,这一次,我们不在使用训练集中的单张图片,我们可以使用训练集中的topK张图片,然后根据这些图片对这个测试的图片投票,得到这张测试图片的标签。其实k=1就是最近邻分类,我们比较一下最近邻分类和5-近邻分类。

这是在二维空间中的三个类别,红,蓝,绿。颜色的交界处就是用L2距离算出来的决策边界,白色区域表示的是模糊区域,就是不知道到底是那个类别。貌似k近邻比最近邻确实好很多,但这个k具体应该怎选取呢?
5.2 超参数的选取
k近邻分类要求我们自己寻定k取多少,那到底一开始这个k应该怎么选取呢?此外,还有很多距离函数,比如L1,L2可以选择,还有其他的一些可以尝试,比如点乘。这样的选择我们称之为超参数的选取,在机器学习算法中,往往不同的数据集就会有不同的超参数,所以,这个很大一部分是依赖于数据的分布和样式的。
那我们具体应该怎么选取呢?你可能会说我们可以都试一下呀!牛逼啊,这可是一个好主意,其实我们基本就这么干的,但是在干的时候,我们很多小技巧可以帮我们节省很多功夫。但首先,我们不能使用测试集中的数据,因为这部分数据在被用来做测试之前,模型必须是从没见过的。如果你使用了测试集来训练,很可能会导致一个后果,就是你用这份测试数据来训练得到的模型在测试数据上的表现也非常好,但是,如果将来还有新的数据来的时候,你的模型就不会有这个效果,我们称模型在测试数据上过拟合了。因此,为了选择好的超参数,我们必须准备一份评估数据集。
评估集
那这份评估集应该怎么选取呢?很简单,就是在训练数据中分割一部分数据出来,比如,我们的50000张图片数据,我们可以分出来1000张作为评估数据,其余的4900张作为训练集。
看一下代码是怎么实现的
# 假设我们之前有 Xtr_rows, Ytr, Xte_rows, Yte 这几份数据# Xtr_rows 是 50,000 x 3072 的矩阵Xval_rows = Xtr_rows[:1000, :] # 抽取前1000张作为评估集Yval = Ytr[:1000]Xtr_rows = Xtr_rows[1000:, :] # 其余的4900张作为训练集Ytr = Ytr[1000:]# 找到在评估集上表现做好的超参数validation_accuracies = []for k in [1, 3, 5, 10, 20, 50, 100]: # 使用确定的k值作用在评估集上 nn = NearestNeighbor() nn.train(Xtr_rows, Ytr) # 这里假设我们有一个最近邻的类,可以把k值作为输入 Yval_predict = nn.predict(Xval_rows, k = k) acc = np.mean(Yval_predict == Yval) print 'accuracy: %f' % (acc,) # 记录在评估集上每个k对应的准确率 validation_accuracies.append((k, acc))最后可以就每个k值和对应的准确率画一张图,选取准确率最高的那个k来作为参数在测试集中使用。
6.小结一下最近邻和k近邻
最近邻分类的优缺点值得我们去深思。最大的优点就是它在训练的时候非常简单粗暴,只要记住这些图片就OK了,但是在预测的时候要计算一张图片和所有训练集中的图片的距离,这就在测试集上花费了太多的时间了。而我们希望的是,模型在训练的时候多花点时间没关系,但在测试的时间一定要尽量快。
接下来的卷积神经网络正是在训练集中花了很多时间,但在测试集上花的时间很少。
参考
cs231n
- 【计算机视觉之三】运用k近邻算法进行图片分类
- 分类问题之K-近邻算法
- K近邻分类算法
- K近邻分类算法
- K近邻分类算法
- k-近邻分类算法
- 利用sklearn包中的k-近邻算法进行分类
- k-近邻算法(三)
- no1 计算机视觉历史 & k近邻线性分类器 & 损失函数和最优化
- 机器学习(二):分类算法之k-近邻算法
- 数据挖掘---分类算法之K近邻(KNN)算法
- 机器学习分类算法之k-近邻算法
- K-近邻分类算法KNN
- K-近邻分类算法KNN
- 图片分类-K近邻分类器
- 《机器学习系统设计》之k-近邻分类算法
- 机器学习之K-最近邻规则分类(KNN)算法
- 深度学习之k-近邻算法识别手写图片
- day5_常用模块
- 设置闹钟
- 亿图流程图连接线怎么画?三个步骤轻松搞定
- [学习笔记][Java编程思想]第6章:访问权限控制
- Python——简单A+B
- 【计算机视觉之三】运用k近邻算法进行图片分类
- Java时间日期格式转换
- 13 linux内核里实现中断底半部处理的新方法
- Fragment导入包的问题
- Wannafly挑战赛4 A 解方程
- 请求发送者与接收者解耦——命令模式(一)
- 在laraval中仿dd函数添加一个ddnodie调试函数
- 配置Tomcat使用https协议(配置SSL协议)
- JavaScript创建数组


