基于信赖域的动态径向基函数代理模型优化策略
来源:互联网 发布:z370主板 知乎 编辑:程序博客网 时间:2024/06/05 14:24
- DRBF法回顾
- TR-DRBF简介
- 拉丁超方设计
- 信頼域思想
- 算例
DRBF法回顾
在上一篇基于动态径向基函数(DRBF)代理模型的优化策略中我们简要介绍了DRBF算法,这种算法收敛次数少,但由于收敛区间只缩小不扩张,该算法有着天然的劣势,如果在几次迭代当中并未搜索到最优解附近的区间,则更新新样本点的区间将缩减到足够小,以致矩阵奇异,从而算法失效。
也是由于这个原因,笔者并未对该算法进行详细展开。
TR-DRBF简介
在本篇文章中,将介绍一种新的算法,TR-DRBF(Trust region based dynamic radial basis function)算法。该方法同样用于模型优化,目的是找到某个函数的最小值,算法的大致描述如下:给定特定函数与搜索区间,首先在整个区间内采一些点,采点方法见拉丁超方设计。
采完第一组点后,利用径向基函数插值出一个代理模型,然后利用全局优化算法(如遗传算法等,笔者用的即为遗传算法)优化该代理模型,得到一个近似最优解,由于当前采集的特征点较少,代理模型并不能很好的代表原函数,接下来就需要运用基于信赖域的采样空间更新策略更新采样空间,得到一组新的样本点,与之前的样本点一起保存进样本点数据库中,然后用这些样本点一起构造新的代理模型,直至相邻两次代理模型求得的全局最优解带入真实模型中,满足收敛条件即可跳出循环。
流程图如下
拉丁超方设计
拉丁超方设计是保证空间均布性与投影均匀性的计算实验设计方案。其实现用matlab自带的lhsdesign函数即可
信頼域思想
信赖域采样空间更新策略的主要目的是使基于当前代理模型的子优化能够实现目标函数值的显著下降。
信赖域采样空间更新策略就是根据当前已知信息,并结合信赖域思想,进行采样空间更新,确定更新后的采样空间的边界。需用参数取值为c1=0.75,c2=1.25,r1=0.1,r2=0.75,信赖域半径上限Δ 取为初始设计空间的半径R,本文中lambda=0.05。
信赖域采样空间更新策略可以总结如下。
第 1 步,确定新采样空间的中心点xc。若真实目标函数值下降,则
当前可能最优解 xk 作为更新后采样空间的中心点x_c,反之,则将上一次的可能最优解 xk -1作为更新后采样空间的中心点 x_c。
% matlab codeif(Y_star_k_1 > Y_star_k) X_c = X_star_k;else X_c = X_star_k_1;end第 2 步,更新信赖域半径delta_k。将信赖域思想引入采样空间更新策略中,根据已知信息,求解获得信赖因子r 。根据r 的大小,按照对信赖域半径进行适当缩放。
r = GetTRFactor(Y_star_k_1,Y_star_k,Y_star_predict_k);delta_k = UpdateDelta(r,X_star_k,X_star_k_1,c1,c2,r1,r2,Delta);function [ output_args ] = GetTRFactor( Y_star_k_1,Y_star_k,Y_star_predict_k )output_args = (Y_star_k_1 - Y_star_k)/(Y_star_k_1 - Y_star_predict_k);%该过程衡量最优解值的改善情况endfunction [ output_args ] = UpdateDelta(r,X_star_k,X_star_k_1,c1,c2,r1,r2,Delta)if r < r1 output_args = c1*abs(X_star_k - X_star_k_1);elseif r > r2 output_args = min(c2*abs(X_star_k - X_star_k_1),Delta);else output_args = abs(X_star_k - X_star_k_1);endend第3 步,信赖域采样空间边界控制。多次迭代之后可能会出现所求信赖域半径delta_k太小,导致新增样本点过于集中在一个狭小空间中,对于提高RBF 代理模型的近似精度没有明显帮助,同时为使优化策略更容易跳出局部最优解,给定最小信赖域半径,可以根据实际问题来确定。此外,获得的信赖域采样空间可能超出初始设计空间,则选取二者交集作为信赖域采样空间边界。则整个基于信赖域思想的采样更新策略如下。
function [ output_args ] = shrinkspace(Y_star_k_1,Y_star_k,Y_star_predict_k,X_star_k,X_star_k_1,lb,ub,lbc,ubc,Delta,c1,c2,r1,r2,lambda)if(Y_star_k_1 > Y_star_k) X_c = X_star_k;else X_c = X_star_k_1;endr = GetTRFactor(Y_star_k_1,Y_star_k,Y_star_predict_k);delta_k = UpdateDelta(r,X_star_k,X_star_k_1,c1,c2,r1,r2,Delta);delta_k = max(delta_k,lambda*Delta);lbc = X_c - delta_k;ubc = X_c + delta_k;lbc = max(lbc,lb);ubc = min(ubc,ub);output_args = [lbc;ubc];end算例
SC_Function
比如我们期望对SC 函数进行优化,该函数是常见的一种优化测试函数,其函数图像如下图
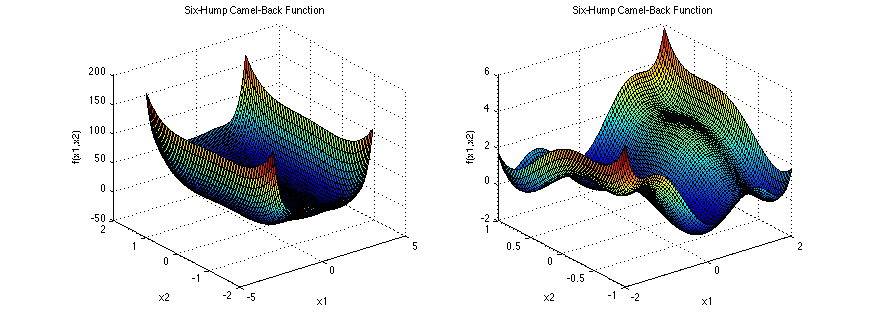
首先,在[-2 -2;2 2]内由拉丁超方方法采集6个点,构造代理模型及所采的6个点如下图 
可以看到,代理模型过每一个采样点,所以说径向基函数为差值型。采用ga算法进行优化求解,得到第一个最优解为[0.9377 -0.4421]处,最优值是1.0767,此时代理模型与原函数相去甚远,所以我们还要进一步更新该代理模型。
选取六个点中的最小值[-0.6615 -0.0811]为中心点更新采样空间,由更新策略得新的采样空间为[-0.6615 -0.8031; 2 -0.0811],然后再在该更新后的空间中重新采6个点,与原来的6个点一起保存到样本库中,进入第二轮循环。
在第二轮循环中,由这12个点构建新的代理模型,得下图 
可以看到,曲面中部的近似于原函数的精度已明显有所提高,动态更新策略仅对兴趣区域采集新的点,所以曲面靠近边界处的精度并未提高,我们也并不关心,因为从代理模型来看,函数的全局最优解仅有可能出现在该次循环所计算的更新后的采样区间当中。
如此进行数次迭代,在第8次循环后,满足收敛条件,循环结束,最后一次构造的代理模型如图

最终找到的全局最优解为-1.0314,与SC_Function的真实最优解-1.0316相差很小。并且这只代表该次的结果,在笔者多次的实验中,大部分时候可以精确找到真实全局最优解,少数情况会过早结束循环,所得结果略大于真实解。要解决这一问题,可以适当调整收敛判据,使之更严格。
该算例最终结果如下
GN_Function
- 基于信赖域的动态径向基函数代理模型优化策略
- 基于动态径向基函数(DRBF)代理模型的优化策略
- 径向基函数神经网络模型与学习算法
- 高斯径向基函数的理解
- 径向基函数方差的选取
- 径向基函数(RBF)
- 径向基函数
- 径向基核函数
- 径向基函数神经网络
- 动态网站的优化策略
- 动态网站的优化策略
- 代理、动态代理、基于模版方法的动态代理
- 基于接口的动态代理
- 基于cglib的动态代理
- 信赖的
- MATLAB中的径向基函数
- 6.3 径向基函数网络
- 径向基函数(RBF)
- 开发者入门必读:最值得看的十大机器学习公开课
- 决策:加入创业公司的考虑
- Java 8 函数式编程(Lambda 表达式)
- BeanFactory not initialized or already closed
- 第十三周Java作业
- 基于信赖域的动态径向基函数代理模型优化策略
- Deepin 15.5 Beta安装oracle
- 如何使用Python编写vim插件
- 凸包旋转卡壳 模板
- VS2015、VS2017等引用有黄色的感叹号小图标
- “'WebElement' object is not iterable”
- !--三子棋之C语言实现--!
- 20171128 自省
- EasyNVR无插件流媒体服务器前端技术防止重复提交的方法


