OLAP分类的基本概念和基本操作
来源:互联网 发布:灵异知乎 编辑:程序博客网 时间:2024/05/17 14:14
OLAP存储分类
OLAP存储有多种实现方法,根据存储数据的方式不同可以分为ROLAP、MOLAP、HOLAP。
ROLAP:表示基于关系数据库的OLAP实现(Relational OLAP)。以关系数据库为核心,以关系型结构进行多维数据的表示和存储。ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字;另一类是维表,即对每个维至少使用一个表来存放维的层次、成员类别等维的描述信息。维表和事实表通过主关键字和外关键字联系在一起,形成了“星型模式”。对于层次复杂的维,为避免冗余数据占用过大的存储空间,可以使用多个表来描述,这种星型模式的扩展称为“雪花模式”。ROLAP的最大好处是可以实时地从源数据中获得最新数据更新,以保持数据实时性,缺陷在于运算效率比较低,用户等待响应时间比较长。
MOLAP:表示基于多维数据组织的OLAP实现(Multidimensional OLAP)。以多维数据组织方式为核心,也就是说,MOLAP使用多维数组存储数据。多维数据在存储中将形成“数据立方体(Cube)”的结构,此结构在得到高度优化后,可以最大程度地提高查询性能。随着源数据的更改,MOLAP 存储中的对象必须定期处理以合并这些更改。两次处理之间的时间将构成滞后时间,在此期间,OLAP对象中的数据可能无法与当前源数据相匹配。维护人员可以对 MOLAP 存储中的对象进行不中断的增量更新。MOLAP的优势在于由于经过了数据多维预处理,分析中数据运算效率高,主要的缺陷在于数据更新有一定延滞。
HOLAP:表示基于混合数据组织的OLAP实现(Hybrid OLAP),用户可以根据自己的业务需求,选择哪些模型采用ROLAP,哪些采用MOLAP。一般来说,会将非常用或需要灵活定义的分析使用ROLAP方式,而常用、常规模型采用MOLAP实现。
Cubes:是数据立方体。何为数据立方体?这主要是和维度的概念一起理解,我们现实是分三维,x,y,z三个坐标决定的空间。而数据库,可能会包含很多维度,只是在我们的认知中无法想像超越三维的事物,这只是个概念。可见,Cube是依赖于维度的。所以在我们建立Cube的时候,需要理解下面的Dimension是什么。
Dimensions:Cube的维度,每个Cube依赖哪些维度来做统计,就需要在这里建。虽然在创建立方的时候会自动帮我们创建维度,但是有时候他创建的维度并不能达到我们的目的。所以,我们先建Dimension,再建Cube。
Mining structures:数据挖掘用的东西,咱这里就不说了,因为我还没用过,只是看了下Webcast的视频,里面介绍了集成了大量的现有挖掘算法,很方便的可以做出相应的分析趋势。 还是看似厉啊。
OLAP的基本操作
我们已经知道OLAP的操作是以查询——也就是数据库的SELECT操作为主,但是查询可以很复杂,比如基于关系数据库的查询可以多表关联,可以使用COUNT、SUM、AVG等聚合函数。OLAP正是基于多维模型定义了一些常见的面向分析的操作类型是这些操作显得更加直观。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以上面的数据立方体为例来逐一解释下: 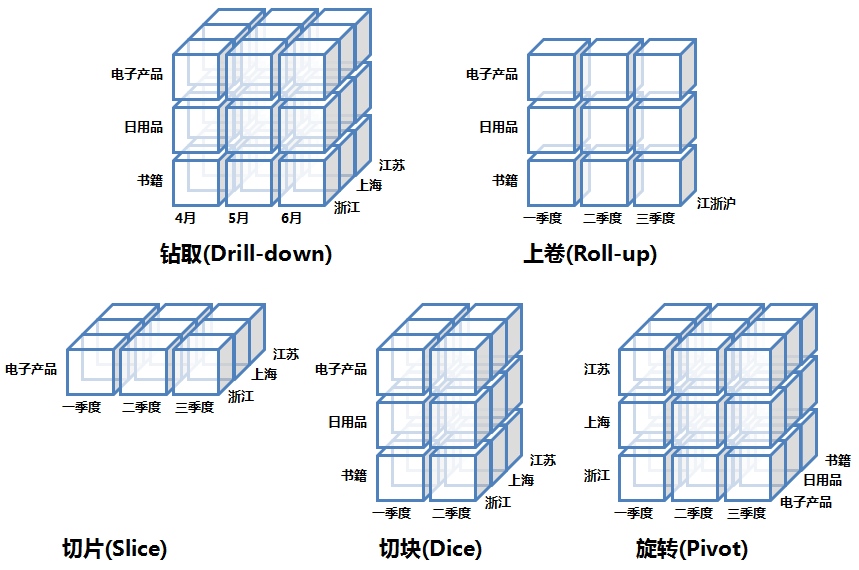
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
转自:http://blog.csdn.net/rgb_rgb/article/details/8662447
- OLAP分类的基本概念和基本操作
- OLAP分类的基本概念和基本操作
- OLAP分类的基本概念
- OLAP的基本概念
- OLAP的基本多维分析操作
- OLAP的分类
- 视频信号的分类和基本概念
- Animation的基本概念和分类
- 排序的基本概念和分类
- 排序的基本概念和分类
- Java 线程的基本概念 创建方法 和 基本操作
- OLAP基本概念
- 基线的基本概念和基线分类
- Docker的基本概念和操作
- 发动机的分类和基本
- [数据结构][C语言]图的基本介绍和操作实现之基本概念
- 分类的基本概念
- jQuery的基本特性和基本概念
- Github使用入门
- ajax提交form表单
- UVA
- day 42 Apache认证及常见功能
- SQL INSERT INTO 语句
- OLAP分类的基本概念和基本操作
- 数据结构实验之查找五:平方之哈希表
- 商品详情页+添加购物车
- 关于magento目录结构
- Git 二分调试法,火速定位疑难Bug!
- 深度学习实战 1-搭建Ubuntu16.04+Anaconda(内嵌Python3.6)+tensorflow
- 十分钟让你明白Objective-C的语法(和Java、C++的对比)
- 基于《21天实战caffe》blob学习时的问题
- Android深度探索 卷1 HAL与驱动开发 读书笔记2


