从零开始用Python构造决策树(附公式、代码)
来源:互联网 发布:115 mac会员破解版 编辑:程序博客网 时间:2024/06/06 04:18
点击有惊喜
熵的计算:
根据计算公式:
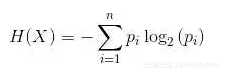
对应的 python 代码:
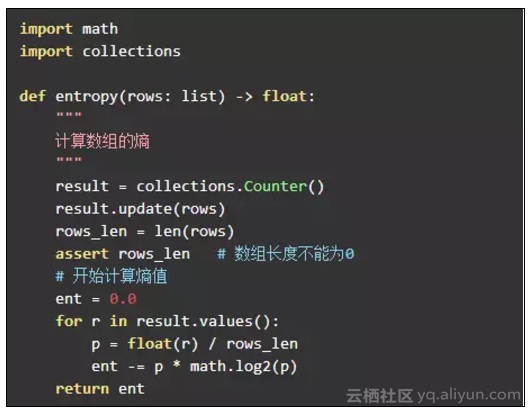
条件熵的计算:
根据计算方法:
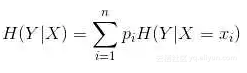
对应的 python 代码:
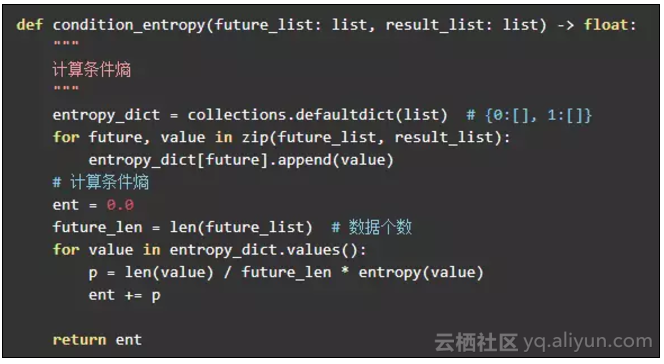
其中参数 future_list 是某一特征向量组成的列表,result_list 是 label 列表。
信息增益:
根据信息增益的计算方法:
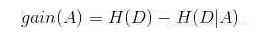
对应的python代码:
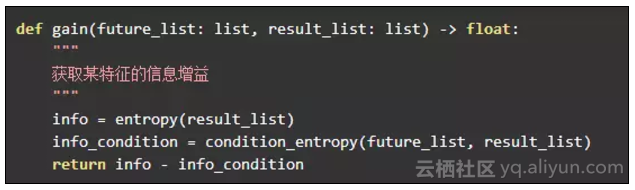
定义决策树的节点
作为树的节点,要有左子树和右子树是必不可少的,除此之外还需要其他信息:
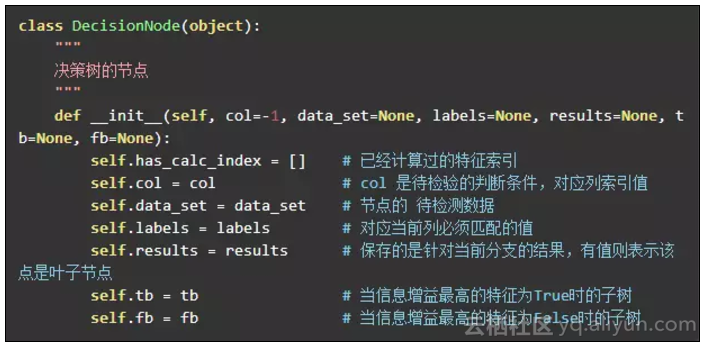
树的节点会有两种状态,叶子节点中 results 属性将保持当前的分类结果。非叶子节点中, col 保存着该节点计算的特征索引,根据这个索引来创建左右子树。
has_calc_index 属性表示在到达此节点时,已经计算过的特征索引。特征索引的数据集上表现是列的形式,如数据集(不包含结果集):
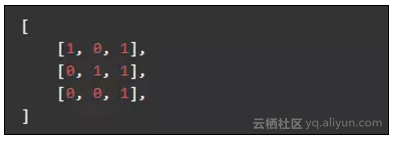
有三条数据,三个特征,那么第一个特征对应了第一列 [1, 0, 0] ,它的索引是 0 。
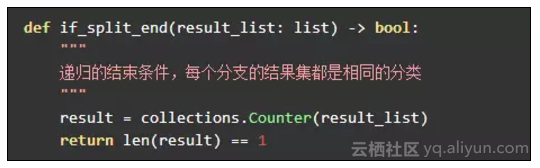
递归的停止条件
本章将构造出完整的决策树,所以递归的停止条件是所有待分析的训练集都属于同一类:
从训练集中筛选最佳的特征:
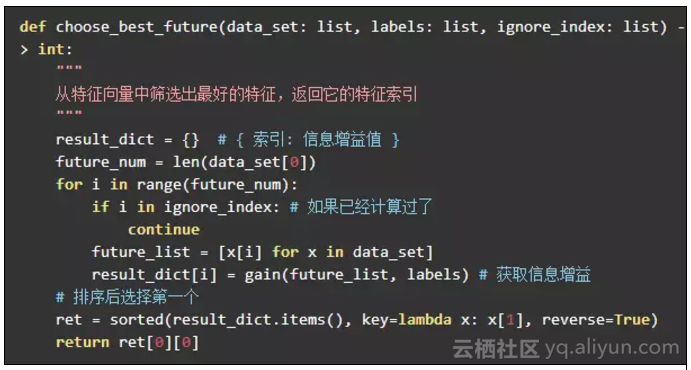
因此计算节点就是调用 best_index = choose_best_future(node.data_set, node.labels, node.has_calc_index) 来获取最佳的信息增益的特征索引。
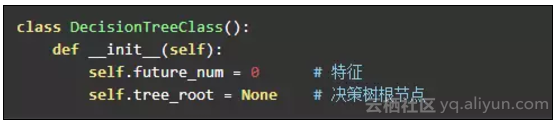
构造决策树
决策树中需要一个属性来指向树的根节点,以及特征数量。不需要保存训练集和结果集,因为这部分信息是保存在树的节点中的。
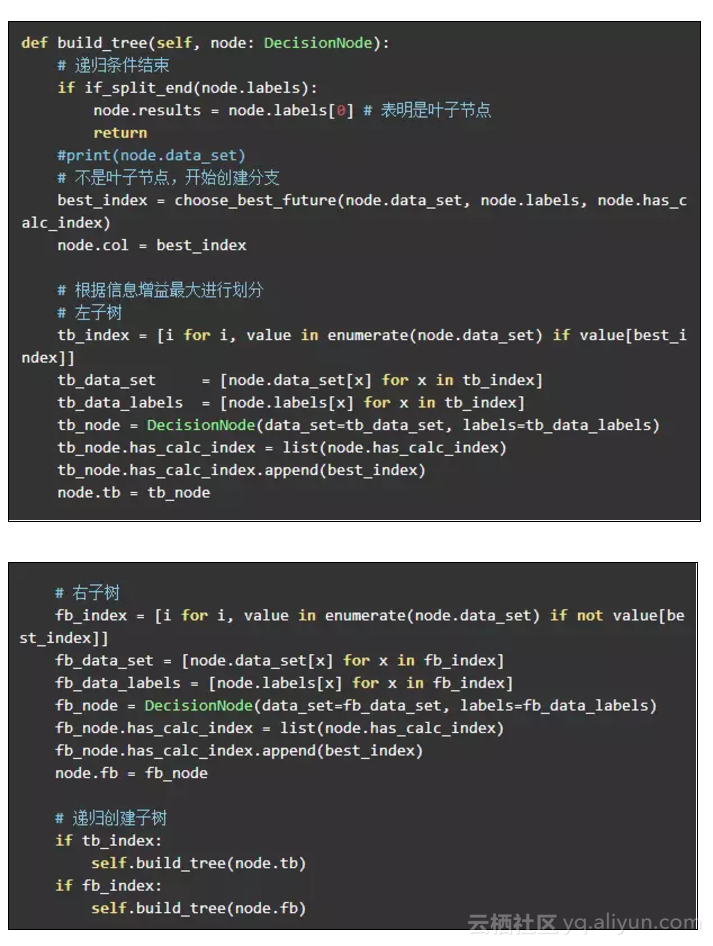
创建决策树:
这里需要递归来创建决策树:
点击有惊喜

阅读全文
0 0
- 从零开始用Python构造决策树(附公式、代码)
- 从零开始用Python构造决策树(附公式、代码)
- 从零开始用Python构造决策树(附公式、代码)
- 从零开始用Python构造决策树(附公式、代码)
- 从零开始用Python构造决策树(附公式、代码)
- 从零开始用Python构造决策树(附公式、代码)
- 用Python从零开始构造决策树
- 从零开始教你训练神经网络(附公式&学习资源)
- 从零开始教你训练神经网络(附公式&学习资源)
- 从零开始教你训练神经网络(附公式&学习资源)
- 决策树ID3代码(Python)
- Python构造决策树
- 决策树算法详解(内附Python函数)
- 决策树的Python代码分析(一)
- 决策树的Python代码分析(二)
- 决策树原理实例(python代码实现)
- 【python实战】3 决策树(代码讲解)
- 决策树代码python
- java Calendar 日历表
- 【论文笔记】Robust Scene Text Recognition with Automatic Rectification
- Windows下安装java开发环境
- C/C++作业4
- java序列化
- 从零开始用Python构造决策树(附公式、代码)
- java高并发解决方案
- hadoop HDFS检测文件是否存在hadoop fs -test
- struct2的xml文件中result的配置(转)
- redis实现分布式锁
- 【重磅发布】代码谱写传奇,深度揭秘中国开发者现状
- ios-leveldb
- MFC-CTabCtrl选项卡控件
- 12.19笔记


