JPA implementations comparison: Hibernate, Toplink Essentials, Openjpa, Eclipselink
来源:互联网 发布:qq端口号 编辑:程序博客网 时间:2024/04/30 21:02
原文链接在此,因无法直接访问,所以转贴于此。
Summary
This article is a response to the lack of information on the net about the performance differences among the 4 most well known Java Persistence API (JPA) implementations: Toplink Essentials, EclipseLink,Hibernate and OpenJPA.Besides results and conclusions, the full test code is also available in case you want to repeat the test yourself.
I wrote a relatively simple program which executes some queries and inserts in a MySQL database through JPA. Four fixed-time tests were done with exactly the same code, just changing the JPA implementation library and the persistence.xml. I monitored the resources used by the JVM and counted the inserts and queries executed during the tests. Finally, I show here my conclusions and also the results of these tests, so that you can draw your own. I consider the differences found among the different implementations truly relevant.
For the tests performed for this article, nothing except JPA was used. No web pages, no web or application server. Just java threads, JPA and MySQL. I give more details in the next sections.
Note: In case you are using JPA with Axis and/or the Google Web Toolkit (GWT), this other article focused on working with JPA, Axis and GWT could be of interest for you.
Description of hardware and software
For the tests performed for this article, nothing except JPA was used. No web pages, no web or application server. Just java threads, JPA and MySQL. I give more details in the next sections.
Note: In case you are using JPA with Axis and/or the Google Web Toolkit (GWT), this other article focused on working with JPA, Axis and GWT could be of interest for you.
Description of hardware and software
The tests have been done in an Acer Extensa 5620G laptop, with a pentium Core 2 Duo T5250 Processor with 2 Gb Ram DDR2, being monitored by a standard PC.
For the tests I have used the following software:
Inserting thread loop gets an arbitrary employee and makes a copy of him/her, letting MySQL generate a new emp_no. This was the only modification I did to the employees database: the emp_no is auto-generated.
Querying thread loop executes these queries in sequence:
- Ubuntu 8.10 Intrepid Ibex
- MySQL database, version 5.0 (installed from the official Ubuntu repositories).
- Java Virtual Machine 1.6
- Driver jdbc for MySQL 5.1.
- Eclipse Ganymede
- The employees database example for MySQL, courtesy of Patrick Crews and Giuseppe Maxia (url below in the references section)
- JConsole for resources monitoring
- GIMP 2 to capture screens
The database and the JVM were running in the Acer machine. But both JConsole and GIMP were executed in a PC (also equiped with Ubuntu 8.10) connected via tcp/ip to the test machine. I did it so that I did not overload the machine running the tests.
Versions of the JPA implementations tested:
- Hibernate EntityManager and Annotations 3.4.0
- Toplink Essentials version 2 build 41
- Openjpa 1.2.0
- Eclipselink 1.0.2
Description of code and tests
The code developed for the tests is available to download here. All you have to do is import the zip file inEclipse. You will need at least one of the JPA implementation libraries. You can download them from the urls in the references section below.
The code is made up of two type of threads, one for inserting and one for querying. each of them containing a loop.Inserting thread loop gets an arbitrary employee and makes a copy of him/her, letting MySQL generate a new emp_no. This was the only modification I did to the employees database: the emp_no is auto-generated.
Querying thread loop executes these queries in sequence:
- A query returning the number of female employees.
- A query returning the number of male employees.
- A query returning all employees hired since an arbitray date.
- A query returning all employees born after an arbitrary date.
- A query returning all women who have earned more than an arbitrary salary.
- When the program starts, it waits 2 minutes for the monitoring infraestructure to be ready (connecting JConsole to the JVM, basically).
- It then starts 2 of the so-called inserting threads. I start the inserting threads before the querying threads trying that the queries do not always return the same (which will eventually happen, anyway).
- After starting the inserting threads, the program starts running 18 of the querying threads, inserting a pause of 10 seconds before starting next. This is so that they do not execute the same query at the same time.
- The program runs the threads for 30 minutes. After that time, it sends a stop signal to the threads, which will safely make them stop after the next inserting or querying round. The main program waits 15 minutes for the threads to stop and the jvm memory to stabilize.
- Before stopping, the threads provide information about the number of inserts/queries they have executed.
The only change from test to test was the JPA implementation library and the persistence.xml. It is important to notice that the persistence.xml was left by default for each of the implementations, omitting on purpose any kind optimization that the implementation could accept.
Before every test, the inserted records were deleted. In this way, every implementation started with the database exactly in the same situation.
ResultsBefore every test, the inserted records were deleted. In this way, every implementation started with the database exactly in the same situation.
These were the results of the tests per JPA implementation library. Notice that the time was fixed: 30 minutes running.
Number of queries+inserts executedNumber of queries executedNumber of inserts executedMax mem occupied during the test(Mb)Mem occupied after the test(Mb)OpenJPA3928
353039896
61Hibernate12687
3080960713079Toplink Essentials
5720
374019805525Eclipselink
5874
373521395725
The maximum memory occupied is the maximum amount that the JVM reserved during the test.
The memory occupied after the test is the amount of memory that remained reserved after finishing the test.
I have emphasized the highest and lowest values for each of the columns.
The memory occupied after the test is the amount of memory that remained reserved after finishing the test.
I have emphasized the highest and lowest values for each of the columns.
You can see this graphically in the following images showing the data monitored during the different tests.

OpenJPA monitoring data
 Hibernate monitoring data
Hibernate monitoring data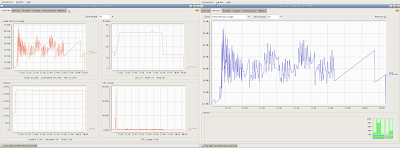 Toplink Essentials monitoring data
Toplink Essentials monitoring data Eclipselink monitoring data
Eclipselink monitoring dataConclusions
My intention is that anyone can draw their own conclusions looking at the results or using the code to do a test of their own.
Nevertheless, I consider that there are a number of conclusions that one can draw watching the monitored data:
References
Ubuntu: http://www.ubuntu.com/
Employees database: http://dev.mysql.com/doc/employee/en/employee.html,https://launchpad.net/test-db/
Openjpa: http://openjpa.apache.org/
Toplink Essentials: http://www.oracle.com/technology/products/ias/toplink/jpa/download.html
Hibernate JPA: http://www.hibernate.org/397.html
Eclipselink: http://www.eclipse.org/eclipselink/
MySQL: http://www.mysql.com/
Eclipse: http://www.eclipse.org/
Nevertheless, I consider that there are a number of conclusions that one can draw watching the monitored data:
- There is not an implementation that clearly has the best performance. Some had a very good CPU or memory performance and some did it very well when inserting or querying. But none of them was outstanding as a whole.
- The number of records inserted by Hibernate was extremely higher than it was for any other implementation (4 times more compared to Eclipselink and 24 times more compared to OpenJPA). However, Hibernate was also the JPA implementation that executed the lowest number of queries, although the differences in this value (3080 for Hibernate vs 3740 for Toplink Essentials) are not so extreme as for the number of inserts.
- Hibernate was also the implementation that consumed more memory. But having into account that it inserted many more records than the others, it sounds reasonable.
- OpenJPA had the lowest value of inserts+queries.
- The number of inserts executed by OpenJPA was extremely low, compared to the others.
- The usage of CPU in the case of Toplink Essentials and Eclipselink was extremely low.
References
Ubuntu: http://www.ubuntu.com/
Employees database: http://dev.mysql.com/doc/employee/en/employee.html,https://launchpad.net/test-db/
Openjpa: http://openjpa.apache.org/
Toplink Essentials: http://www.oracle.com/technology/products/ias/toplink/jpa/download.html
Hibernate JPA: http://www.hibernate.org/397.html
Eclipselink: http://www.eclipse.org/eclipselink/
MySQL: http://www.mysql.com/
Eclipse: http://www.eclipse.org/
- JPA implementations comparison: Hibernate, Toplink Essentials, Openjpa, Eclipselink
- JPA 实现比较:Hibernate、Toplink Essentials、OpenJPA、Eclipselink
- JPA 实现比较:Hibernate、OpenJPA、Eclipselink
- TopLink&EclipseLink
- TopLink JPA
- Spring + toplink-essentials(JPA) is not a known entity type 问题解决
- OpenJPA与Hibernate实现JPA的性能…
- Comparison of different SQL implementations
- Toplink JPA简介
- Toplink-JPA/zhuan
- 【转】Toplink JPA简介
- Toplink JPA 参数说明
- EclipseLink/Features/JPA
- EclipseLink JPA 2.1
- Eclipselink JPA 使用小结
- OPENJPA使用JPA规范
- JPA调研与JPA的总体思想和现有Hibernate、TopLink,JDO等ORM框架
- 什么事JPA,JPA和Hibernate、TopLink等ORM框架的关系
- 迅雷官方手把手教你,一个下载软件中到底可以强行植入多少广告
- [转]LBM相关的开源软件与免费代码
- YAFFS2的简单制作
- 利用Google Translate制作自己的翻译脚本(更新中>>>)
- TheServerSide网站2009年最热文章
- JPA implementations comparison: Hibernate, Toplink Essentials, Openjpa, Eclipselink
- 行动中的美好!
- final在java中的应用
- super java
- abstract和interface的区别
- 2009年终总结
- CUDA面内存用法总结
- broncho a1 hack指南-准备环境
- 把中英文混合的字符串转换成AscII


