转 .NET 运行全程简析
来源:互联网 发布:手机挂机赚钱软件 编辑:程序博客网 时间:2024/04/30 09:22
转帖,原文作者我没有注意去查阅
解析.NET运行全程
今天没什么事做,去复习程序集那章,然后就想到了.NET的运行流程。于是就把握理解的.NET运行过程大概地按照流程重新想了一次。
在这里,描述一下,希望能给各位带来帮助,如果有不足之处,还希望大家多多指教。
先看一张最基本的.NET运行流程图,这应该是所有学习.NET的人都知道的图,没有细节,只有最基本的框架。
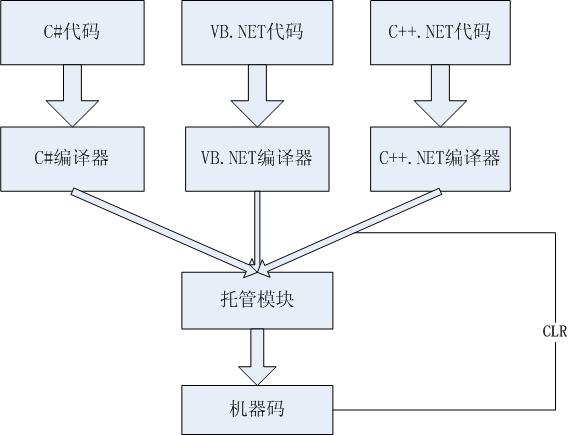 这张图很简单,相信每个人应该都见过的,大概的解释下,拿C#代码为例,C#代码首先通过C#编译器然后形成托管代码,然后再由托管代码转换为机器可识别的2进制机器码。
这张图很简单,相信每个人应该都见过的,大概的解释下,拿C#代码为例,C#代码首先通过C#编译器然后形成托管代码,然后再由托管代码转换为机器可识别的2进制机器码。
好了,我们分别来分析每一个过程,以C#为例。
1.C#代码通过C#编译器编译成了托管模块。我们来解释下”托管”这个名词,托管我的理解就是不能够直接与操作系统进行交互的东西。比如说托管语言就是说需要在操作系统和语言之间搭建一层虚拟机,目前较为常见的托管语言主要是JAVA和C#,JAVA靠的是JVM(JAVA virtual Machine),而C#则是CLR。
那托管模块究竟是由什么组成的呢?我们来慢慢看。
托管模块是一个需要CLR环境才能跑起来的模块,又被称为PE文件。托管模块一般来说包含以下四部分:
<1>PE表头。PE表头最主要的作用就是标识出该文件的类型,比如说究竟是个控制台应用程序,Windows应用程序,还是一个程序集。另外PE表头还包含了一些比如说文件创建时间,编辑时间之类的东东。
<2>CLR表头。这个我不是太了解。但是应该主要是标识一些跟CLR有关的东西,比如说CLR的版本号。我个人认为CLR表头最主要的作用是标识出函数入口点的元数据标记,以及元数据的地址和占有内存大小。
<3>元数据。元数据我个人认为主要是标识出代码中定义的类型和成员。元数据有很多应用,很多我忘记了,我了解的有这样几条:(关于元数据的详细讨论,我们稍后进行)
1. 反射。Type.GetType(string className)。反射依靠的正是元数据。
2. VS的智能感知。这个是通过分析元数据来告诉我们类有什么方法,方法有什么参数。
3. 垃圾回收器。垃圾回收器正是通过元数据来获知对象的类型,以及对象之间的相互引用。
4. 安全检查。(这个我不懂,希望各位高手指教)
<4>IL代码。对于IL,微软给出的是这样的解释:面向对象的汇编语言,他拥有很多高级指令,甚至
包括初始化类,异常抛出等等。IL也常常被称做托管代码。其实.NET中的IL就相当于JAVA中的字节码文件,不同的是JAVA的字节码文件是解释执行,而IL代码是编译执行。(应该是这样的,如果有错误希望大家指出,我JAVA不熟)
元数据微软MSDN的描述是这样的:元数据是一种二进制信息,用以存储在公共语言运行库PE文件或内存中的程序进行描述。元数据的存储主要是以表形式来存储的,比如说有一个表专门来存储类,一个表专门来存储字段。如果一个项目中有100个类,那么专门存储类的表中就会有100行,每行放一个类描述。另外,元数据还会以堆方式存储,这个我不懂,希望高人指教。
下面来看下元数据标记。了解IL的人应该知道,IL的变量操作是靠着元数据才能混下去的。所以这个时候,元数据标记就诞生了,他有点类似于指针,专门用于指向某一张表的某一行。元数据标记是一个四个字节的数字,比如说0x0f001103,前两位是来指向表,而后6位则是用来指向表中的行。不知道大家明白了没有。
接下来,很多人会以为是将托管模块编译成机器码的时候了,其实不是这样的。在这个之前还有一步,也就是我们所熟悉的程序集。CLR不合托管模块打交道,他交往的对象是程序集。什么是程序集?程序集从结构上你可以理解为是一个或多个托管模块,加上一些资源文件所组成的逻辑组合。从内存上,你可以理解为是以CLR为宿主的版本化的二进制文件。
你可以这样理解程序集的结构:程序集=托管模块+资源文件+清单。托管模块我就不再说了,资源文件就是一些比如文本文件,图片之类的东东,而清单呢?则主要是记录在这个程序集中的每一个模块,程序集的版本以及这个程序集所引用的其他程序集信息。
好了,这次可以和CLR打交道了,CLR开始执行程序集。谈到CLR,在这里提到CLR中一个很重要的东东,mscoree.dll:公共语言运行库执行引擎。主要来负责寻找所有要加载的dll的位置并且加载它们,然后读取程序集的元数据,因此mscoree.dll又被称为是CLR的垫片。在这里,提到一点,微软对.NET做了一点优化,就是说CLR会根据特定机器的CPU来加载不同的dll来改善性能,比如说AMD的CPU和Intel的CPU加载的dll是不同的。
我们把这个分为第一次执行和非第一次执行。
对第一次执行,我把它总结为三个大阶段:编译—>验证-à执行。而编译阶段,我又把它分为五部分:查元数据—>调ILà分配内存àIL编译成机器码à存入内存。这里很容易理解,时间原因,就不详细些了。
第二次执行,由于JIT编译器已经将机器码存储于动态内存当中,记住这个,这很重要,尤其对于泛型效率的理解!因此,第二次执行,相当于比第一执行少了编译和验证的过程,因此提高了效率。
好了,.NET整个程序的运行过程就讲到这了。最后,做些小补充,算我为.NET做广告了。
1. JIT编译器会为一些新型的CPU产生这些CPU所提供的特殊指令的本地代码。比如说Core2,那么JIT就会产生Core2所特有的本地代码,这样在Core2的机器上提高了程序的性能。
2. JIT会为程序做出程序优化。有个.NET的反编译器工具叫做Reflector.exe,这个工具的作用是把机器码给反编译回去。因此我们可以通过这个工具查看.NET代码优化后的结果。举个例子,用foreach遍历二维数据,用这个工具查看我们可以发现,其实.NET实际上是把他拆成了两个for语句。推荐这个工具,这对你理解.NET的一些内部原理非常有好处。
3. CLR能够对你的代码进行评估,然后对你的代码进行重新排列。比如说
int i=Convert.ToInt32(Console.Readline());
if(i==1){}
if(i!=1){}
那么,由于i!=1的可能性远远大于i=1的可能性,所以CLR就会把i!=1提到前面,这样就能减少了逻辑判断的次数,从而提高了效率。
CLR还能对代码做出很多优化,在这里就不继续提了。好了,今天就写到这了,很晚了,
有些困了……白天又是难熬的一天,带着耳机继续过……
- 转 .NET 运行全程简析
- ASP.NET MVC |B2C商城全程开发
- google全程面试题目【转】
- ArmLinux BOOTLOADER全程详解[转]
- java项目开发全程实录第5章运行错误。
- 2012考研全程学习规划简案
- [转]2004年候捷老师大陆行,全程记录!
- 玩转VMware虚拟机全程图解
- UPX脱壳全程分析(转)
- 让.Net程序脱离.Net Framework框架运行(转)
- win7 里配置iis 和asp.net步骤,及发布asp.net网站全程
- win7 里配置iis 和asp.net步骤,及发布asp.net网站全程
- Hadoop学习全程记录——在Eclipse中运行第一个MapReduce程序
- Hadoop学习全程记录——在Eclipse中运行第一个MapReduce程序
- Hadoop学习全程记录——在Eclipse中运行第一个MapReduce程序
- [转载]Hadoop学习全程记录——在Eclipse中运行第一个MapReduce程序
- Hadoop学习全程记录——在Eclipse中运行第一个MapReduce程序
- Hadoop学习全程记录——在Eclipse中运行第一个MapReduce程序
- sprintf函数详细解释
- 理想
- Ubuntu10.04修复grub
- Silverlight调用WebService时出现的跨域方式访问服务
- qq克隆匹配DOM,并选中当前克隆匹配元素集合
- 转 .NET 运行全程简析
- Protect Your Flash Files From Decompilers by Using Encryption
- Android平台硬件调试之Camera篇
- SQL SERVER PIVOT 行列转换
- 部分IT公司笔试算法题(转)
- 创智播客 .NET 文章精华 没看完 存个传送门在这里
- dfasdfasdf
- 如何在 Windows CE 5.0 中开发和测试设备驱动程序
- Windows PowerShell 2.0 开发之命令别名


