我的中文ocr——从miniocr说起
来源:互联网 发布:matlab矩阵代码 编辑:程序博客网 时间:2024/05/18 00:59
本文地址:http://blog.csdn.net/SerenityMoon/archive/2010/12/09/6066476.aspx转载请注明出处。
众所周知,现在已经有很多成熟的ocr产品,但是这些ocr产品都有一个共同的特点就是对小字符图片的识别效果很差,而这样的缺陷也催生了马飞涛先生的miniocr的诞生。
我开始做文字模式识别前,没有任何基础,甚至对模式识别都所知甚少。文字识别可查的资料更是少的可怜,几乎没有什么有用的信息,这段时间的确是一段非常痛苦的开始。miniocr的简介非常简单,我一个字一个字的读完也没有为我提供太多有用的信息。从其他一些资料上可以看到的关于文字识别也通常是只有简单的几行描述,能够搜索到的代码也都是关于手写体识别或者数字识别的。就是靠着这些只言片语,我一点一点的试验摸索,走到了现在。目前对汉字的识别尤其是小四号字以下字体、字母数字的识别效果非常好,四号字体以上的稍差一点,对中英文字符的区分还正在优化中。
我做做这个东西目的和miniocr的起源是差不多的,所面对都是小字符图片的文字识别,不同的是我所面对的需要更多的处理一张图片中可能只有两三个字、字符下面带背景的情况。而miniocr对这两种情况的识别效果基本为0,尤其是像地图这样的文字排列杂乱无章的情况,程序直接崩溃。这就说明miniocr的字符切分算法使用了大部分ocr产品使用行列分别进行切分的切分方式,这种切分方式默认文字的排列是成行的,所以对不成行的情况下的切分无能为力了。
对于图文混排情况下的文字模式识别,文字切分的好坏直接决定了文字识别的效果。由于考虑到图片中文字数可能会很少甚至有类似于地图的文字排列情况,我放弃了使用通用的行列切分的方法。经过试验,采用基于区域生长的方式来搜索文字区域。从疑似文字区域的一个像素点出发,生长出整个文字区域,然后通过多种校验手段来判断这个区域是否是文字区域,事实验证我的这个方法行至有效。几张实际的切分效果图如下所示:

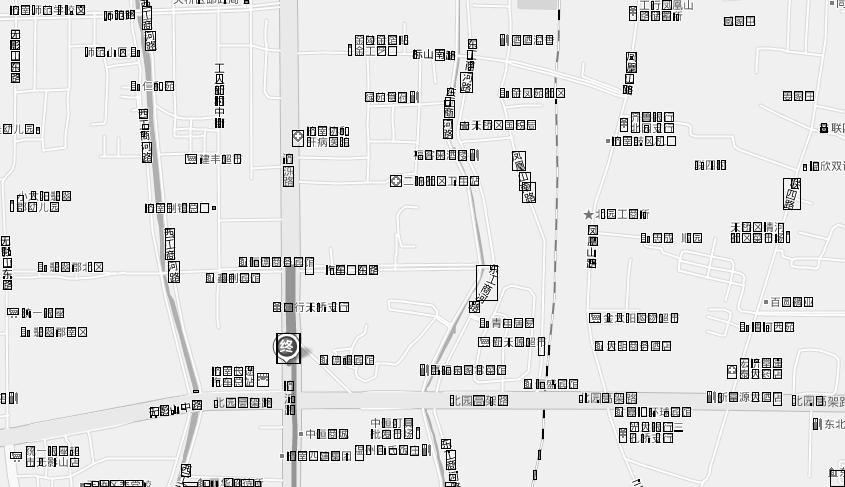

由于文字切分使用了以上的方法,这也导致了在中英字符区分时,我就不能利用前后文字的长宽与当前文字长宽相比等一些有效的进行区分字符类型的手段,这样我需要更多有用的信息来对字符类型进行判断,目前在这点上我还没有达到非常满意的效果。
由于是应用在实际项目中的,所以对识别性能要求是非常之苛刻的,在字符切分与识别上,我采用多种加快计算的快速搜索算法,最终我的整个ocr模块完全达到项目的性能要求,远远超出了miniocr的识别速度。
另外我的ocr是完全使用C语言完成的,并且是跨平台的,没有使用任何第三方库。由于各种原因,我不能继续透漏更多的技术细节,敬请谅解,如有需求可另作交流。
- 我的中文ocr——从miniocr说起
- 雅虎通——从怀念我的雅虎说起
- 从《我的青春我做主》说起
- 从企业的运行价值链说起——我眼中的测试驱动开发(TDD)
- 从企业的运行价值链说起——我眼中的测试驱动开发(TDD)
- 从企业的运行价值链说起——我眼中的测试驱动开发(TDD) 转
- 从我的第一个Flex应用说起(一)——开篇
- 从我的第一个Flex应用说起(二)——规范与设计
- 我的职场-从大学说起
- 昨日关注:从企业的运行价值链说起——我眼中的测试驱动开发(TDD)
- IT思考——从SOA的定义说起
- Henry手记—从Datagrid的标题居中说起
- 从我的身边说起软件业的小发展
- 理解AngularJS——从WPF说起
- 我的简单OCR
- 从普林斯顿的宽容说起
- 从北京的四合院说起
- 从js的dtree说起
- DataSet,DataTable,DataView
- Linux设备模型 学习总结(转)
- 设置html表格的线宽颜色
- IBM_Thinkpad_X30奔三也疯狂之三 Ubuntu安装和体验
- 第六讲:类、对象的简单应用及类封装、隐蔽性
- 我的中文ocr——从miniocr说起
- 第七讲:构造函数与析构函数
- Portlet中需要引入多个javascript文件的写法
- FTP的两种不同工作模式
- 用c++编写的文件分割器源码!
- 第八讲:对象数组与指针
- 我的第一的博文
- Business Glossary
- 我的C++


