《独辟蹊径品Linux内核源代码导读》VFS一章内容笔记2
来源:互联网 发布:淘宝女士高腰内裤 编辑:程序博客网 时间:2024/04/30 05:38
虚拟文件系统的管理结构
Linux 支持各种不同的文件系统,同时对上层抽象出一个统一的接口,例如应用程序无需关心文件系统的细节,只需要调用open,read,write等系统调用,就能够对文件进行操作。为此提出了虚拟文件系统(Virtual FileSystem),对于不同的文件系统,它的磁盘文件的结构布局肯定是不一样的,但是虚拟文件系统屏蔽了这些差异,向上层提供一个统一的接口。虚拟文件系统管理的结构包括超级块,Inode,目录项等。
文件系统对象
每一个文件系统驱动程序都有一个文件系统对象,定义如下:
struct file_system_type {
const char *name;
int fs_flags;
int (*get_sb) (struct file_system_type *, int,
const char *, void *, struct vfsmount *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type *next;
struct list_head fs_supers;
};
name: 文件系统的名字, 例如"ext2"、"iso9660"、"msdos"等
fs_flags: 各种标志(亦即: FS_REQUIRES_DEV, FS_NO_DCACHE 等)
get_sb: 每当该类型的文件系统被挂载时, 调用该方法
kill_sb: 每当该类型的文件系统被卸载时, 调用该方法
owner: VFS 内部使用:多数情况下该被赋值为 THIS_MODULE
next: VFS 内部使用:多数情况下该被赋值为 NULL
各文件系统驱动都需要调用register_filesystem()注册文件系统对象。所有文件系统对象通过next指针来链接成链表,全局变量file_systems指向链表的头部。
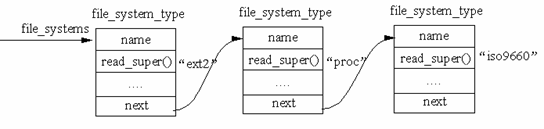
由于一个文件系统可能对应多个分区,因此fs_supers链表链接了各个分区的超级块。
Ext2的file_system_type的结构定义如下:
static struct file_system_type ext2_fs_type = {
.owner = THIS_MODULE,
.name = "ext2",
.get_sb = ext2_get_sb,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
int __init init_ext2_fs(void)
{
return register_filesystem(&ext2_fs_type);
}
int init_module(void)
{
return init_ext2_fs();
}
VFS的超级块
VFS的超级块是根据具体文件系统的超级块建立的内存结构。
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned long s_blocksize;
unsigned char s_blocksize_bits;
unsigned char s_dirt;
loff_t s_maxbytes; /* Max file size */
struct file_system_type * s_type;
const struct super_operations * s_op;
const struct dquot_operations * dq_op;
const struct quotactl_ops * s_qcop;
const struct export_operations * s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry * s_root;
struct rw_semaphore s_umount;
struct mutex s_lock;
int s_count;
int s_need_sync;
atomic_t s_active;
# ifdef CONFIG_SECURITY
void * s_security;
# endif
struct xattr_handler * * s_xattr;
struct list_head s_inodes; /* all inodes */
struct hlist_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_files;
/* s_dentry_lru and s_nr_dentry_unused are protected by dcache_lock */
struct list_head s_dentry_lru; /* unused dentry lru */
int s_nr_dentry_unused; /* # of dentry on lru */
struct block_device * s_bdev;
struct backing_dev_info * s_bdi;
struct mtd_info * s_mtd;
struct list_head s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
int s_frozen;
wait_queue_head_t s_wait_unfrozen;
char s_id[ 32] ; /* Informational name */
void * s_fs_info; /* Filesystem private info */
fmode_t s_mode;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char * s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char * s_options;
} ;
s_fs_info字段指向一个文件系统信息的数据结构,对于Ext2文件系统,该字段指向ext2_sb_info类型的结构.
Ext2的内存结构
之前学习了Ext2磁盘上的布局,在使用过程中,内核需要频繁的访问某些结构,因此当磁盘驱动程序把相关数据从磁盘上读出来之后,内核会建立相应的内存中的结构。
在/include/linix/ext2_fs_sb.h中定义如下:
struct ext2_sb_info {
unsigned long s_frag_size; /* fragment片的长度,以字节为单位 */
unsigned long s_frags_per_block;/* 每块中fragment片数 */
unsigned long s_inodes_per_block;/* 每块中inode数 */
unsigned long s_frags_per_group;/* 每一块组中fragment数 */
unsigned long s_blocks_per_group;/* 每一块组中块数 */
unsigned long s_inodes_per_group;/* 每一块组中inode数 */
unsigned long s_itb_per_group; /* 每一块组中inod表占用的块数 */
unsigned long s_db_per_group; /* 每一块组中描述符占用的块数 */
unsigned long s_desc_per_block; /* 一块中组描述符数*/
unsigned long s_groups_count; /* 整个文件系统中的块组数 */
struct buffer_head * s_sbh; /* 指向内存中包含超级块的缓冲区的指针 */
struct ext2_super_block * s_es; /* 指向缓冲区中超级块的指针 */
struct buffer_head ** s_group_desc; /* 指向缓冲区组描述符数组的指针 */
struct buffer_head ** s_group_desc; /* 指向缓冲区组描述符数组的指针 */
unsigned short s_loaded_inode_bitmaps; /* 装入缓冲区的inode位图块数 */
unsigned short s_loaded_block_bitmaps; /* 装入缓冲区的块位图块数 */
unsigned long s_inode_bitmap_number[EXT2_MAX_GROUP_LOADED];
/* inode位图数组 */
struct buffer_head * s_inode_bitmap[EXT2_MAX_GROUP_LOADED];
/* inode位图指针数组 */
unsigned long s_block_bitmap_number[EXT2_MAX_GROUP_LOADED];
/* 块位图数组 */
struct buffer_head * s_block_bitmap[EXT2_MAX_GROUP_LOADED];
/* 块位图指针数组 */
int s_rename_lock; /* 重命名时的锁信号量 */
struct wait_queue * s_rename_wait; /* 重命名时的等待队列指针 */
unsigned long s_mount_opt; /* 安装选项 */
unsigned short s_resuid; /* 可以使用保留块的用户uid */
unsigned short s_resgid; /* 可以使用保留块的用户组gid */
unsigned short s_mount_state; /* 超级用户使用的安装选项 */
unsigned short s_pad; /* 填充 */
int s_addr_per_block_bits; /* 块地址(编号)的位(bit)数 */
int s_desc_per_block_bits; /* 块描述符的位(bit)数 */
int s_inode_size; /* inode长度 */
int s_first_ino; /* 第一个inode号 */
};
- 磁盘超级块中的大部分字段
- s_sbh指针,指向包含磁盘超级块的缓冲区的缓冲区首部
- s_es指针,指向磁盘超级块所在的缓冲区
- 组描述符的个数s_desc_per_block,可以放在一个块中
- s_group_desc指针,指向一个缓冲区(包含组描述符的缓冲区)首部数组(只用一项就够了)
- 其他与安装状态、安装选项等有关的数据
Ext2在内存中的Inode结构定义如下:
在include/linux/ext2_fs_i.h中,如下所示:
struct ext2_inode_info {
__u32 i_data[15]; /* 数据块指针数组 */
__u32 i_flags; /* 文件标志(属性)*/
__u32 i_faddr; /* Fragment (片)地址 */
__u8 i_frag_no; /* Fragment (片)号 */
__u8 i_frag_size; /* Fragment (片)大小 */
__u16 i_osync; /* 同步标志 */
__u32 i_file_acl; /* 文件访问控制链表 */
__u32 i_dir_acl; /* 目录访问控制链表 */
__u32 i_dtime; /* 文件删除时间 */
__u32 i_version; /* 文件版本 */
__u32 i_block_group;/* inode所在块组号 */
__u32 i_next_alloc_block;/* 下一个要分配的块 */
__u32 i_next_alloc_goal; /*下一个要分配的对象 */
__u32 i_prealloc_block; /* 预留块首地址 */
__u32 i_prealloc_count; /* 预留计数 */
int i_new_inode:1; /* 标志,是否为新分配的inode */
};
下图表示的是与Ext2超级块和组描述符有关的缓冲区与缓冲区首部和ext2_sb_info数据结构之间的关系。
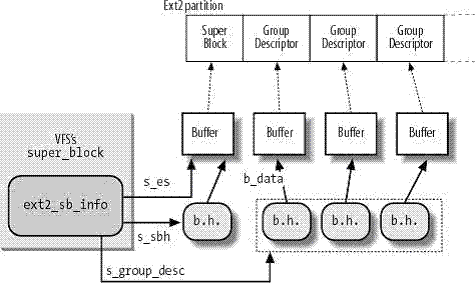
当内核需要mount一个块设备的时候,会根据分区表中的信息分析这个块设备的文件系统类型,然后从file_systems链表中找到对应的文件系统驱动程序的文件系统对象,调用它的get_sb()函数获取具体文件系统超级块的信息,然后根据这些信息初始化VFS超级块。结构中s_fs_info就指向具体文件系统的超级块内存对象。如果这个分区的文件类型为Ext2,那么这个结构就是ext2_sb_info。由于各种文件系统的超级块不同,对超级块的操作也不一样,因此内核定义了一个super_operations结构。get_sb函数会根据文件系统类型设置不同的super_operations指针。以ext2文件系统为例:ext2文件系统的get_sb函数是ext2_get_sb(),ext2_get_sb请求磁盘驱动程序把相应的块读取出来以后,调用ext2_fill_super根据磁盘上ext2_super_block结构,初始化内存中的ext2_sb_info及VFS的super_block结构,同时把s_op设置为ext2_sops.
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*dirty_inode) (struct inode *);
int (*write_inode) (struct inode *, int);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
int (*show_stats)(struct seq_file *, struct vfsmount *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
};
static int ext2_fill_super(struct super_block *sb, void *data, int silent)
{
/*参数sb指向VFS的超级块*/
struct buffer_head * bh;
/*
*sbi指向内存中的Ext2超级块,es指向从磁盘读取到的Ext2超级块
*这个函数的主要工作就是根据es结构初始化sbi和sb结构
*/
struct ext2_sb_info * sbi;
struct ext2_super_block * es;
struct inode *root;
unsigned long block;
unsigned long sb_block = get_sb_block(&data);
unsigned long logic_sb_block;
unsigned long offset = 0;
unsigned long def_mount_opts;
long ret = -EINVAL;
/*BLOCK_SIZE默认为1KB。*/
int blocksize = BLOCK_SIZE;
int db_count;
int i, j;
__le32 features;
int err;
/*分配内存的ext2_sb_info结构*/
sbi = kzalloc(sizeof(*sbi), GFP_KERNEL);
if (!sbi)
return -ENOMEM;
sbi->s_blockgroup_lock =
kzalloc(sizeof(struct blockgroup_lock), GFP_KERNEL);
if (!sbi->s_blockgroup_lock) {
kfree(sbi);
return -ENOMEM;
}
/*VFS超级块的s_fs_info指向Ext2超级块ext2_sb_info结构*/
sb->s_fs_info = sbi;
/*Ext2超级块的s_sb_block指向VFS超级块的super_block结构*/
sbi->s_sb_block = sb_block;
/*
* See what the current blocksize for the device is, and
* use that as the blocksize. Otherwise (or if the blocksize
* is smaller than the default) use the default.
* This is important for devices that have a hardware
* sectorsize that is larger than the default.
*/
blocksize = sb_min_blocksize(sb, BLOCK_SIZE);
if (!blocksize) {
ext2_msg(sb, KERN_ERR, "error: unable to set blocksize");
goto failed_sbi;
}
/*
* If the superblock doesn't start on a hardware sector boundary,
* calculate the offset.
*/
if (blocksize != BLOCK_SIZE) {
logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize;
offset = (sb_block*BLOCK_SIZE) % blocksize;
} else {
logic_sb_block = sb_block;
}
/*
*请求磁盘驱动程序读取超级块:在缓冲区页中分配一个缓冲区和缓冲区首部。然后从磁盘读入超级块存放在缓冲区中。
* 如果一个块已在页高速缓存的缓冲区页而且是最新的,那么无需再分配。将缓冲区首部地址存放在Ext2超级块对象sbi的s_sbh字段
*/
if (!(bh = sb_bread(sb, logic_sb_block))) {
ext2_msg(sb, KERN_ERR, "error: unable to read superblock");
goto failed_sbi;
}
/*
* Note: s_es must be initialized as soon as possible because
* some ext2 macro-instructions depend on its value
*/
/*bh->b_data指向读取缓冲区的首地址,offset是超级块的偏移*/
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset);
/*Ext内存超级块的s_es指向Ext2磁盘超级块es(现在这个结构在内存中)*/
sbi->s_es = es;
sb->s_magic = le16_to_cpu(es->s_magic);
if (sb->s_magic != EXT2_SUPER_MAGIC)
goto cantfind_ext2;
......
/*根据磁盘上的s_log_block_size计算逻辑块的大小*/
blocksize = BLOCK_SIZE << le32_to_cpu(sbi->s_es->s_log_block_size);
if (ext2_use_xip(sb) && blocksize != PAGE_SIZE) {
if (!silent)
ext2_msg(sb, KERN_ERR,
"error: unsupported blocksize for xip");
goto failed_mount;
}
......
/*片大小,当前没有实现分片,片大小等于块大小*/
sbi->s_frag_size = EXT2_MIN_FRAG_SIZE <<
le32_to_cpu(es->s_log_frag_size);
if (sbi->s_frag_size == 0)
goto cantfind_ext2;
sbi->s_frags_per_block = sb->s_blocksize / sbi->s_frag_size;
/*每个组的块个数*/
sbi->s_blocks_per_group = le32_to_cpu(es->s_blocks_per_group);
/*每个组的片个数*/
sbi->s_frags_per_group = le32_to_cpu(es->s_frags_per_group);
/*每个组的Inode个数*/
sbi->s_inodes_per_group = le32_to_cpu(es->s_inodes_per_group);
if (EXT2_INODE_SIZE(sb) == 0)
goto cantfind_ext2;
/*一个块中Inode个数等于块大小处以Inode大小*/
sbi->s_inodes_per_block = sb->s_blocksize / EXT2_INODE_SIZE(sb);
if (sbi->s_inodes_per_block == 0 || sbi->s_inodes_per_group == 0)
goto cantfind_ext2;
/*一个组的inode数量除以一个块的Inode数量,就得到一个组中有几个块是用来存储Inode的*/
sbi->s_itb_per_group = sbi->s_inodes_per_group /
sbi->s_inodes_per_block;
/*块大小处以组描述符大小,得到一个块中最多有几个组描述符*/
sbi->s_desc_per_block = sb->s_blocksize /
sizeof (struct ext2_group_desc);
......
/*由于没有实现分片,片大小不能与块大小就报错*/
if (sb->s_blocksize != bh->b_size) {
if (!silent)
ext2_msg(sb, KERN_ERR, "error: unsupported blocksize");
goto failed_mount;
}
if (EXT2_BLOCKS_PER_GROUP(sb) == 0)
goto cantfind_ext2;
/*
计算当前分组的个数,前面已经讨论过,组的个数由分区大小和块大小决定。
这里需要处理,分区中块的边界不能凑成一个组的情况。
*/
sbi->s_groups_count = ((le32_to_cpu(es->s_blocks_count) -
le32_to_cpu(es->s_first_data_block) - 1)
/ EXT2_BLOCKS_PER_GROUP(sb)) + 1;
db_count = (sbi->s_groups_count + EXT2_DESC_PER_BLOCK(sb) - 1) /
EXT2_DESC_PER_BLOCK(sb);
/*
*为组描述符分配buffer_head结构:
*/
sbi->s_group_desc = kmalloc (db_count * sizeof (struct buffer_head *), GFP_KERNEL);
if (sbi->s_group_desc == NULL) {
ext2_msg(sb, KERN_ERR, "error: not enough memory");
goto failed_mount;
}
bgl_lock_init(sbi->s_blockgroup_lock);
/*分配一个字节数组,每组一个字节,把它的地址存放在ext2_sb_info描述符的s_debts字段*/
sbi->s_debts = kcalloc(sbi->s_groups_count, sizeof(*sbi->s_debts), GFP_KERNEL);
if (!sbi->s_debts) {
ext2_msg(sb, KERN_ERR, "error: not enough memory");
goto failed_mount_group_desc;
}
/*请求磁盘驱动程序,把组描述符读取出来,并设置对应的s_group_desc数组中的指针*/
for (i = 0; i < db_count; i++) {
/*根据超级块中的s_first_data_block,块大小,以及组描述符的大小,计算第i个组描述符的逻辑块号*/
block = descriptor_loc(sb, logic_sb_block, i);
/*请求磁盘驱动程序读取第block块*/
sbi->s_group_desc[i] = sb_bread(sb, block);
/*一个块包含多个组描述符*/
if (!sbi->s_group_desc[i]) {
for (j = 0; j < i; j++)
brelse (sbi->s_group_desc[j]);
ext2_msg(sb, KERN_ERR,
"error: unable to read group descriptors");
goto failed_mount_group_desc;
}
}
if (!ext2_check_descriptors (sb)) {
ext2_msg(sb, KERN_ERR, "group descriptors corrupted");
goto failed_mount2;
}
sbi->s_gdb_count = db_count;
......
/*
* set up enough so that it can read an inode
*/
/*
*设置VFS超级块的super_operation指针为ext2_sops
*这样就建立了抽象的VFS超级块对象和具体的ext2超级块对象之间的关联
*/
sb->s_op = &ext2_sops;
sb->s_export_op = &ext2_export_ops;
sb->s_xattr = ext2_xattr_handlers;
/*获取根目录的inode*/
root = ext2_iget(sb, EXT2_ROOT_INO);
if (IS_ERR(root)) {
ret = PTR_ERR(root);
goto failed_mount3;
}
if (!S_ISDIR(root->i_mode) || !root->i_blocks || !root->i_size) {
iput(root);
ext2_msg(sb, KERN_ERR, "error: corrupt root inode, run e2fsck");
goto failed_mount3;
}
/*初始化根的目录结构*/
sb->s_root = d_alloc_root(root);
if (!sb->s_root) {
iput(root);
ext2_msg(sb, KERN_ERR, "error: get root inode failed");
ret = -ENOMEM;
goto failed_mount3;
}
......
return ret;
}
- 《独辟蹊径品Linux内核源代码导读》VFS一章内容笔记2
- 《独辟蹊径品Linux内核源代码导读》VFS一章内容笔记
- 《独辟蹊径品内核:Linux内核源代码导读(china-pub首发)》的前言
- linux VFS概述以及内核源代码分析
- linux VFS概述以及内核源代码分析
- Linux内核学习笔记导读
- linux VFS学习笔记一
- webkit内核源代码导读
- VFS与Ext2文件系统------《深入Linux内核架构》笔记
- VFS与Ext2文件系统------《深入Linux内核架构》笔记
- 《Linux内核设计与实现》笔记——VFS
- Linux内核编程导读
- linux内核导读
- linux内核学习导读
- webkit内核源代码导读2: FrameLoader的初步分析
- linux VFS数据结构(一)
- Linux VFS分析(一)
- Linux内核导读之微型计算机组成原理(笔记)
- Android NDK概述
- 深入理解Magento – 第四章 – 模型和ORM基础.doc
- Hash算法
- 深入理解Magento – 第五章 – Magento资源配置.doc
- 深入理解Magento – 第六章 – 高级Magento模型.doc
- 《独辟蹊径品Linux内核源代码导读》VFS一章内容笔记2
- 广珠城际动车容桂站初体验
- Android提高十七篇之多级树形菜单的实现
- 英语口语的提高
- 【STM32 .Net MF开发板学习-26】借道调试口与开发板通信
- 再回首
- C++静态数据成员定义及应用浅谈
- 表达式解析引擎的设计
- 30个最酷的Windows Phone 7教程


