算法分析与设计的作业:“基于FMM的分词系统”
来源:互联网 发布:关于程序员的纪录片 编辑:程序博客网 时间:2024/04/29 19:13
准备要截课了,于是乎按老师的要求做了一个简单的分词程序,程序主要是针对中文分词的。断断续续做了几天,感觉做得很一般,仅仅是完成了一些基本的功能。
采用机械分词中全切分的方法将句子进行切分,具体的描述看下边的文档:
本程序分为两个部分来实现:
一、从海量数据中生成我们的数据字典
我们使用一下这样的数据结构来存储我们收集到的数据信息:
// 句子的内容:出现次数,内容,类型
为了提高程序快速收集和查询字典信息,这里我采用了开散列这样的数据结构,同时,为了避免在存储不同的信息的时候可能会造成信息冲突的情况,使用了拉链法处理冲突的情况。
具体的做法是:从指定的数据文件中收集汉字的相关信息(出现次数和内容),然后将其统计的结果保存到另一个文件中,留给后边分词使用。
生成字典文件的流程图如下:
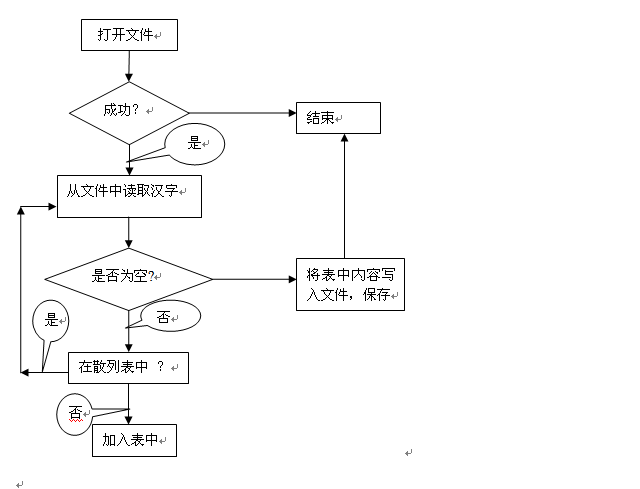
二、依据数据字典对句子进行分词处理
当我们得到之前生成的数据字典后,我们就可以依据数据字典的相关信息和句子的情况进行分词处理。这里,我使用FMM的全切分的方法来对句子进行切分。
FMM:将句子从左向右扫描一遍,遇到字典里有的最长词就标识出来,遇到不认识的字串就分割成单字词。
全切分:获得文本所有可能的切分结果,得到所有切分单元
下边是一个例子:
例句:“我是一个学生!”
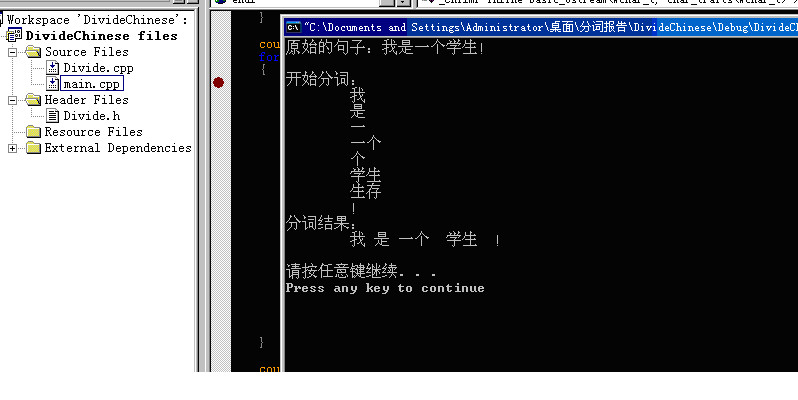
切分结果如上图所示
当我们获得句子的所有切分后,我们就可以根据切分的情况组成切分的句子。具体的选择过程如下:
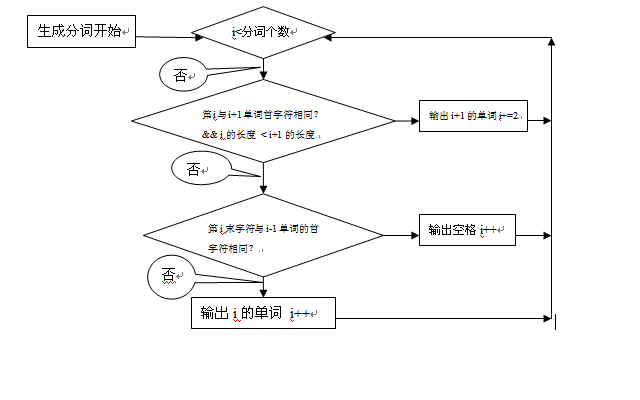
从第一个切分汉字开始,选择它的最长切分结果作为第一个切分块,然后第二个,直到结束,就可得到最后的切分句子。
实验总结:
通过本次实验,使我对自然语言处理中的中文分词技术有了一定的了解,并且对与之相关的应用有了进一步的认识,了解了在搜索引擎中和拼音输入法中使用的一些中文分词的相关技术,为后续课程的学习打下了一定基础。
- 算法分析与设计的作业:“基于FMM的分词系统”
- 中文分词的python实现-基于FMM算法
- FMM算法 分词
- 基于神经网络的汉语自动分词系统的设计与分析
- SIGHAN2005分词baseline的perl程序FMM
- 中文分词的python实现----HMM、FMM
- python 中文分词——FMM 算法
- 基于UML的短消息计费系统的分析与设计
- opencv图像修复算法cvInpaint(Telea的FMM算法)
- 《算法分析与设计》课程作业
- 算法设计与分析第二周作业
- 算法与设计分析作业(分治)
- 算法分析与设计第一次作业
- 算法与设计分析作业3(贪心)
- 算法分析与设计第一次作业
- 算法设计与分析作业(1)
- 计科《算法设计与分析》第四周作业——图的表示
- 中文分词算法——基于统计的分词
- linux程序移植到android
- 在Java程序中调用C函数--打印"HelloWorld"
- observer
- 最简单的C++排序问题
- Best of open source platforms and middleware
- 算法分析与设计的作业:“基于FMM的分词系统”
- OpenCV2.0 2.1里面IplImage 对数据操作的一个注意点
- 2010 ACM-ICPC Multi-University Training Contest(11)——Host by BUPT
- 出行记录
- 调试 core dump 文件
- linux,线程,结束过程详解
- 通过java枚举实现的单例jdbc连接与关闭
- linux下的第一个驱动
- Linux,socket,非阻塞,fcntl


