系统吞吐性能优化简述
来源:互联网 发布:梦里花落知多少 91 编辑:程序博客网 时间:2024/05/05 19:33
被朋友问起性能优化的东西,今天简单总结一下:
一般的java系统,大体的模型如下:
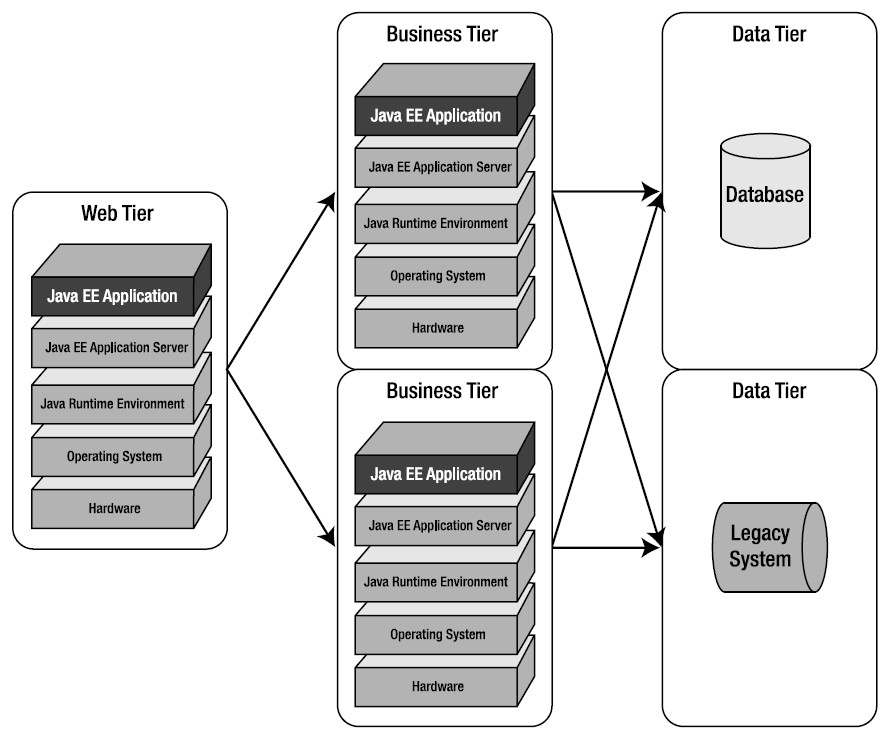
复杂的系统可能在application server一层有多个,简单一些的系统可能没有application server
直观一点说,用户请求的执行路径就是:
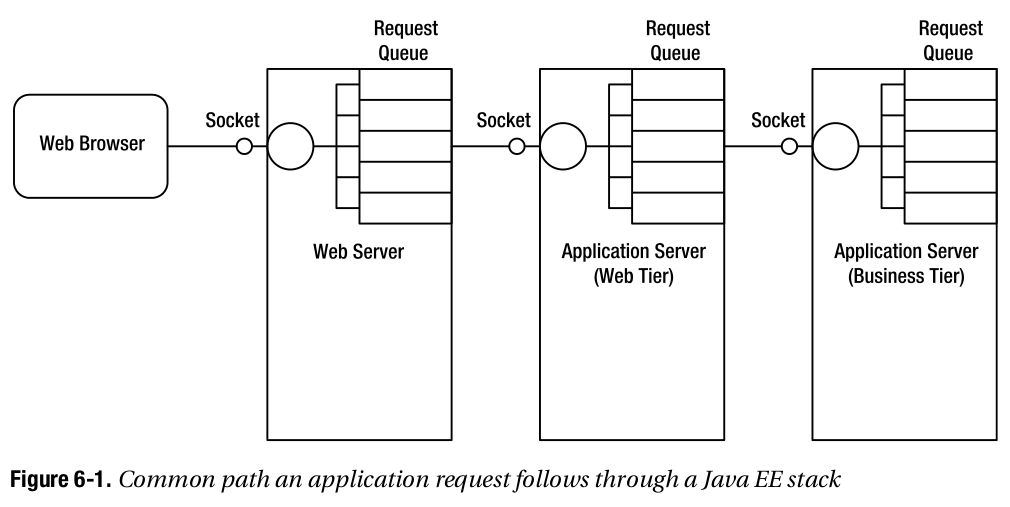
细化到每个server的内部,请求的执行路径就是:
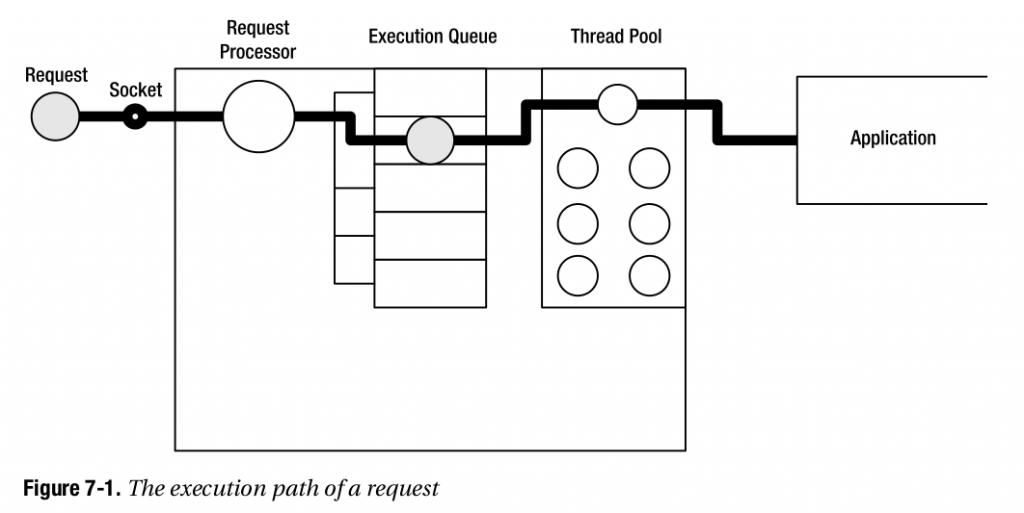
注:这只是一个简化的系统模型,具体的实现可能会有更多的trick
从上面的分析,可以看出,web server、application server,都是一个队列模型,简单的说,系统吞吐量的优化,就是对如下这个队列模型的吞吐量优化:
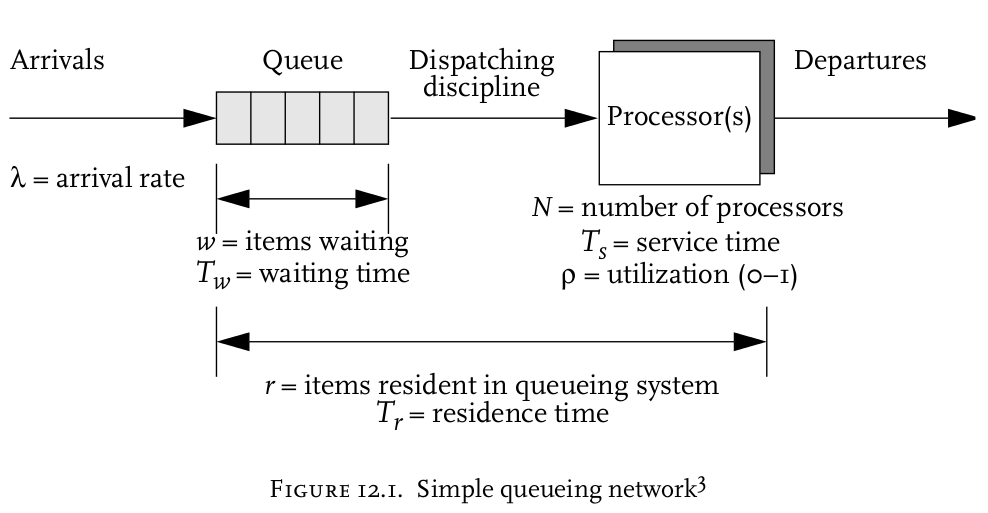
上图中的参数说明如下(不知道博客里面怎么输入这些符号):
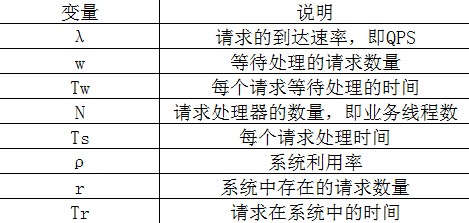
上图中的变量之间有着千丝万缕的关系,不过最终总结出,系统的吞吐量公式为:
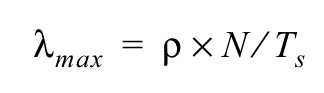
即:系统吞吐量=系统使用率 * 系统线程数 / 请求业务处理时间
为了防止系统请求高峰,系统使用率一般在70%以下,那么优化就只有两条路可以走:
1、增大处理线程数 --> 不是越多越好
2、降低业务处理时间
业务处理时间是业务相关的,暂且不讨论。
线程数的选择,也是有章可循的:
线程数量=(线程总时间/瓶颈资源时间) * 瓶颈资源的线程并行数
比如,一个业务系统,一个请求中,cpu处理时间为20ms,读取数据库总耗时为80ms,服务器为16核,那么该系统的线程数为:
线程数量=(20 + 80) / 20 * 16= 80
这是从cpu的角度还计算线程数的。
如果系统需要获得一个互斥锁呢?
比如还是上面的系统,一个请求中,cpu处理时间为10ms,读取数据库总耗时为80ms,获取互斥锁需要10ms,那么,从互斥锁的角度来计算线程数为:
线程数量= ( 10 + 80 + 10 ) / 10 * 1 = 10
设置再多的线程,也是在等待互斥锁。
有人可能会说,一个简单的web应用里面怎么会有互斥锁呢?数据库连接池,连接池配置不合理,也会成为系统瓶颈。
到这里,系统吞吐量优化的任务简化成了寻找系统瓶颈。最简单的方法就是profile,JProfiler等等的利器,挂到系统上去压测。
不过有时候业务系统的环境非常复杂,搭建一套压力测试环境的成本非常高。能在不影响线上系统的情况下在线上系统采集线上性能数据是最简单而且最有效的方法。推荐一个我写的profile:simple-profiler ,可以直接挂到线上去profile线上代码,性能损耗非常小。
Java系统优化,逃不过GC参数的调整。网上有很多教程,就不多废话了。
- 系统吞吐性能优化简述
- 系统吞吐性能优化简述
- mysql 性能优化简述
- PHP 性能优化简述
- Kafka 高性能吞吐
- NO.41 Web系统性能优化 1.简述(Linux+Weblogic+Oracle)
- 谷歌TPU优化新进展:数据吞吐提升15倍、每瓦特性能猛增
- Kafka 高性能吞吐揭秘
- Kafka 高性能吞吐揭秘
- Kafka 高性能吞吐揭秘
- Kafka 高性能吞吐揭秘
- Linux系统性能优化
- **系统性能优化方案
- 优化Linux系统性能
- 系统性能优化思路
- 系统性能优化
- 优化系统性能
- 系统性能优化攻略
- css属性列表 和 属性值含义
- CSS浏览器兼容汇总
- log4j.properties文件详解
- 内核同步
- 从今天开始!
- 系统吞吐性能优化简述
- Linux shell I/O重定向详解--基础篇
- Java学习笔记1:在控制台输出金字塔
- struts-config.xml中标签path属性传多个参数注意点
- MySQL一个线程处理一个连接源码
- Linux shell I/O重定向--进阶
- 【转】LINUX-2.6.31内核移植及添加驱动
- 第十三天(集合框架-续二)
- Android系统的启动过程分析


