HashMap源码分析
来源:互联网 发布:apache ip不能访问 编辑:程序博客网 时间:2024/04/29 11:13
HashMap源码分析
作者:十年砍材 撰写日期:2011-9-26
HashMap是java中使用非常频繁的容器类,也是java笔试面试中经常会问到的。深入理解HashMap有助于我们更好的使用它。
1. HashMap内部结构了解HashMap的数据结构,有助于理解HashMap的各种操作。HashMap内部结构如下图:
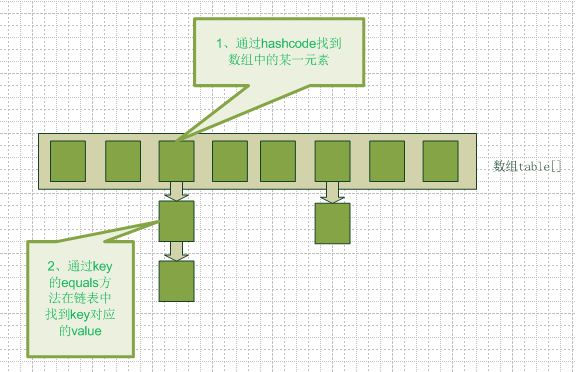
由上图可知,整个HashMap内部构造是一个数组,数组元素是一个链表。熟悉哈希的应该知道,数组元素的存储位置使用哈希方法得到,而链表的作用就是解决哈希存在的冲突。
HashMap中数组长度为2的整数幂,默认初始长度为16 ,装载因子为0.75。
static final int DEFAULT_INITIAL_CAPACITY = 16; static final float DEFAULT_LOAD_FACTOR = 0.75f; 初始化一个HashMap类,可以指定一个容量参数initialCapacity,构造函数会根据initialCapacity进行初始化,找到一个大于等于initialCapacity且为2的整数幂的值作为哈希数组的长度:int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; this.loadFactor = loadFactor; threshold = (int)(capacity * loadFactor); table = new Entry[capacity];
HashMap 中存储的元素为Entry类,此类是HashMap中定义的内部类: static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; } 其中key为存入的key值,value为存入的value值,next是指向下一个Entry元素的指针,hash为key的hashcode经过hash后的值。
2. HashMap中的各种操作
插入操作put:
public V put(K key, V value) { if (key = = null) return putForNullKey(value); int hash = hash(key.hashCode()); //对key的hashcode值重新hash int i = indexFor(hash, table.length); //找到key在table中的放入位置 for (Entry<K,V> e = table[i]; e != null; e = e.next) { //检查内部是否已存在key,若存在,则更新其value Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); //将新的Entry<key,value>放入table中 return null; }插入算法对key为null的情况进行了特别处理,HashMap会将key为null的值插入到table数组的一个位置所在的链表中。HashMap采用如下算法进行hash:
static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }addEntry算法将Entry<key, value>插入链表的头部
void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length);//数组扩容 }插入元素后,检查数组中存放的元素是否超过门限值(数组长度*装载因子),若超过,扩展数组的长度为原来的2倍,并对原数组的元素重新进行哈希,并放入新数组中的新的位置。
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); }/** * Transfers all entries from current table to newTable. */ void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }数组空间重新分配及数组元素重新哈希是非常耗时的,因此,在使用HashMap的过程中,如果可以预知存放元素个数的大致范围,可以在初始化一个HashMap时指定数组长度,从而可以有效避免重新哈希的情况。下面看HashMap是如何快速取值的:
public V get(Object key) { if (key == null) return getForNullKey(); //从数组第一个元素所在的链表取 int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null;}key等于null的情况比较简单,不再说明,对于key不为null的情况,首先通过hash方法,找到带查找的key所在数组中的位置,然后遍历相应的链表。
遍历操作:
由于hashMap中元素的存储位置与插入顺序无关,在遍历时,hashMap不保证遍历结果与插入顺序一致。HashMap通常使用keySet与entrySet进行遍历,keySet遍历方式将元素集的key值转换成一个Set,代码如下:
Map map = new HashMap(); Iterator iter = map.keySet().iterator(); while (iter.hasNext()) { Object key = iter.next(); Object value = map.get(key); }entrySet将hashMap中存储的元素Entry转换成entrySet,其遍历方式如下: for(Map.Entry<Integer, String>m:map.entrySet()){ Object key=m.getKey(); Object value=m.getValue(); }这两种遍历方式在效率上有所差别:ketSet遍历了两次,第一次将元素集转换成keySet,第二次通过map.get(key)有遍历了一次;entrySet遍历方式只遍历了一次,因此在效率上较前者有所提高。
- 源码分析:HashMap
- 源码分析:HashMap
- HashMap源码分析
- HashMap 源码分析
- HashMap源码分析
- HashMap LinkedHashMap源码分析
- HashMap源码分析
- HashMap 源码分析
- HashMap源码分析
- HashMap源码分析
- HashMap源码分析
- Java HashMap 源码分析
- HashMap源码分析
- java HashMap源码分析
- 源码分析HashMap
- HashMap源码分析
- HashMap源码分析
- HashMap源码分析
- android widget 之EditText
- Ruby获取event的方法
- C语言运算符优先级 详细列表(转自:http://blog.csdn.net/shihaojie1219/article/details/5811191)
- (16)XML
- win8安装方式
- HashMap源码分析
- XML2
- 直接插入排序:改进算法---折半插入排序
- [pythonchallenge]level3
- Mac OS X中显示/不显示隐藏文件方法 命令行
- win7下硬盘分区
- 打印矩形
- DTD
- 面试题:五笔的字典序编码与解码


