数据库基本理论和概念:关系模型
来源:互联网 发布:方维众筹系统源码1.7 编辑:程序博客网 时间:2024/04/28 16:57
关系模型有三个原理组件:结构性组件、完整性组件以及操纵性组件。
本文主要介绍结构性组件及其它组件的一些基本概念。本文的产生,基于阅读The Definitive Guide to Sqlite后的一些感想!
(1)结构性组件
定义了信息的组织方式和表示方式。具体点说,所有的信息都用关系(relations)来表示。关系是由tuple(元)组成的,元又是由属性和值两部分组成。关系(relation)是数据库中用来表示各种信息的唯一的数据结构。关系模型中的relation概念起源于数学集合理论中的relation概念,因此它们很多属性有很多相似之处。

tuple可理解为值的集合,每一个值都有相关联的属性。 A set of values, each of which has an associated attribute!
tuple由属性和值两部分组成。属性定义了value的名字(name)和域(domain),name可以用来区分tuple中的value, domain则限制了value的范围。把attribute属性和value值组合起来,就是一个component.
那么,什么是relation呢? A set of one or more tuples that share the same heading!
我们先看看heading的概念。heading就是tuple中一群属性的集合,如上图所示。
一个relation,简单的说,就是具有相同heading的一个或多个tuple。也就是说,在一个relation中,所有的tuple share一个heading.
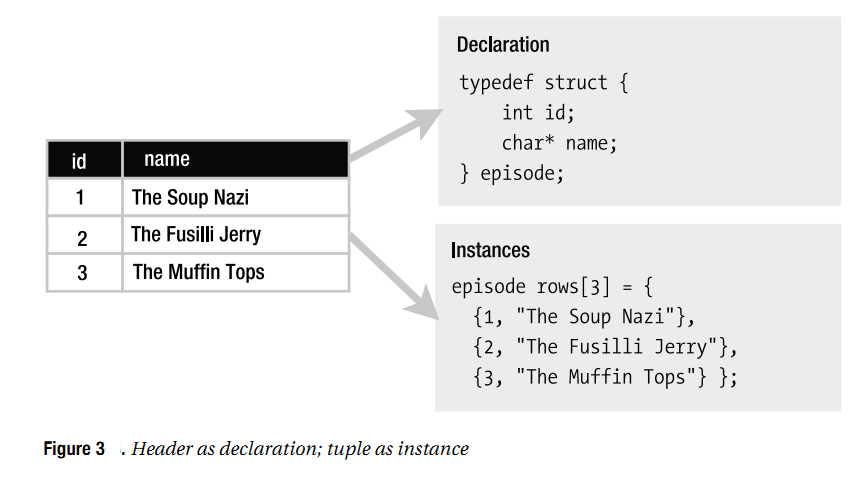
接下来,什么是table呢? 简单的说,可以认为是relation变量。即:Relation Variables.
一个relation,虽然它本身包含很多value, 自己本身也是一个value, 就如同一个整数或字符串一样。不禁要问,relation的value是什么呢?每一个relation的value是由该relation内部的某个tuple赋值的。与此类似,每一个tuple的值也是由该tuple内部的某个值。因此,一个relation是由它各个部分综合来决定的。下面这个图可以用来深入理解下此概念。

上图描述了3个relation, 用R1\R2\R3表示,替代了IXF。他们各自代表不同的值,也就是不同的relation。然而,R1\R2\R3本身并不被认为是relation,而被认为是relation variables.在SQL中,它们被形象的称为tables.他们也被称为基表,由于他们也是变量,并且变量的值为relations.
在实际应用中, Relation的准确定义可能比较让人难以理解,其定义比较模糊。通常,relations和table都在同样的语境中使用。然而,relation和table并不是一样的东西。可以这么理解, relation是值,而table是变量。
tables,是变量,既有名字,也有值。名字只是一个标记,而值就是relations. tables具有relations的所有属性(heading,degree,cardinality等),这就如同一个整型变量具有所有整数的特性一样。请注意:
A table is a variable holding an entire relation as its value。
有了前面这些知识作为基础,大家可以思考下,如果更新或者修改一个table,意味着什么呢?无论变化多么细微, 你都将改变整个relation.也就是说,你不会只是改变某个行或列,实际上你会用一个relation去交换一个新的relation. 在新的relation里, 包含有你希望改变的行和列。
接下来 ,我们介绍视图的概念。
然而不能说视图就是table. 这 就比如说,代数表达式x+y本身不是一个数字,但是如果给表达式赋值,它可以得到一个数字。例如,如果数据系统管理员(DBA)把一个大的table拆成2个小的table,他可以创建一个视图,这个视图看起来就与拆分前的table一模一样。实际上,这个。这样,对于用户和应用程序来说,似乎就没有差别。这样,就实现了一种逻辑数据的独立性。
逻辑数据的独立性,不仅仅体现在用户查看数据的时候。实际上,你也可以对视图进行写操作,就像对普通的table进行写操作一样。

结构组件是其它组件的基础,它定义了信息表示的表格或形式。定义的规则最早由codd提出。
信息原理:关系数据库中的所有信息都是在逻辑层明确表示,并且只通过唯一的方式表示。这种唯一的方式就是通过表(table)中的value来表示。
也可总结如下:
数据库中的所有信息内容都是通过表(table)中的由行和列共同确定的位置处存放的值来表示的。这种表示方式是唯一的。
逻辑层指的是用户查看数据库和查找其中的数据的方式。它有2个重要属性:
第一,逻辑层的视图(VIEW)由表(table)组成,table由许多行(rows)组成,行由许多value值组成;
第一,逻辑层的视图(VIEW)与数据库系统是完全独立的,包括实现它的软件技术和硬件技术;
也就是说,逻辑层的表示自成体系,完全不同于数据库的具体实现方式、数据库的物理存储方式以及数据库内部如何操作数据。如果数据库供应商决定改变数据库表格(tables)在磁盘上的存储方式,信息原理保证了这种物理层的改变不能影响数据的逻辑表示,即你看到数据的方式是不能改变的。可以参看下面的示意图深入体会下:
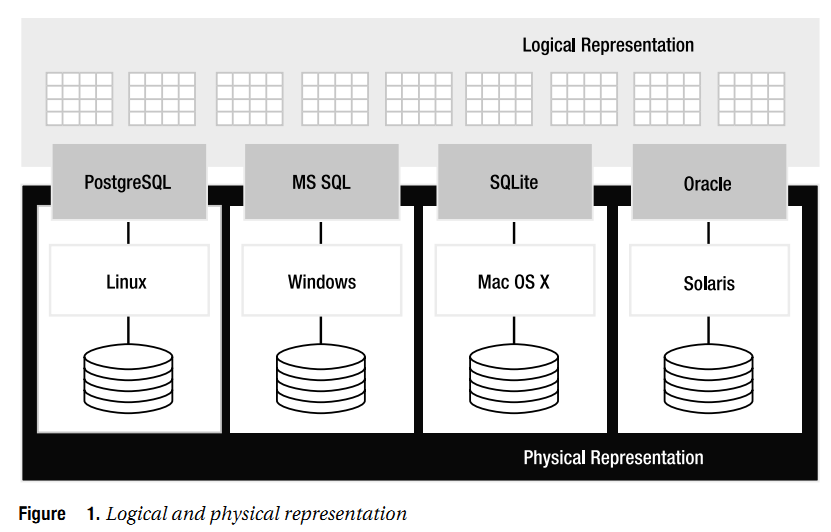
可见,信息原理的强制性特点,使得我们无论采用什么硬件,无论运行什么操作系统,无论采用什么方法来实现软件,用户都可以看到完全一致的信息逻辑视图。
我们已经知道,数据库是由tables和views组成的。你也许还想知道,如何在数据库中找到指定的数据呢? 所有的表,视图,约束条件以及其他数据库对象都注册到了系统目录中。

(2)完整性组件:
定义了结构性组件中relation内部和relation(或者table)之间的生成和维持关联性(relationship)的方法。这些方法以规则的形式表示,被称为约束条件(constraints).完整性组件有三种原理类型:(一)domain integrity域的完整性,该类型主要限制了列中的值大小;(二)实体完整性(entity integrity),主要控制table的行数;(三)引用(referential)完整性,主要管理表(table)之间的关系。

(3)操纵性组件:
定义了用于操纵或管理信息的方法,如relations。这些方法起源于数学中的关系代数理论和关系微积分理论。
- 数据库基本理论和概念:关系模型
- 概念模型和关系模型
- 【Oracle数据库】关系型数据库的基本理论
- 数据库系统概念读书笔记(3)--关系模型
- 《数据库系统概念》笔记:关系模型
- 数据库系统概念笔记-关系模型介绍
- 概念模型与关系模型和关系规范化
- 数据库概念模型和物理模型设计
- 数据库基本理论
- 数据库基本理论
- 数据库基本理论
- 关系模型--码概念
- 数据库设计之概念模型ER关系图
- 【数据库系统概念部分习题】第二章 关系模型介绍
- 数据库系统概念(第二章:关系模型介绍)
- 数据库概念模型和逻辑模型及物理模型
- 关系数据库、数据仓库的概念和异同
- 数据库模型的概念、作用和三要素
- 汇编,减法指令SUB是怎样影响标志位的?
- 使用exp备份数据库时丢失数据库表解决方案
- good
- 使用C#彻底的删除文件
- evc中使用CWebBrowser2控件
- 数据库基本理论和概念:关系模型
- boost正则表达式库regex库和xpressive库关于零宽断言的问题
- 如何创建一个Database Link
- android 跑马灯
- init、loadView、viewDidLoad、viewDidUnload、dealloc
- GOLDEN RULE(s) of design pattern
- RESTful框架 摘记
- 2011-10-12
- BFILE数据的存取


